Fundamentos Básicos
O óbvio precisa ser dito. Essa frase parece boba, mas é importante demais, tanto para IA quanto se você for um lider de equipe. Se você quer algo bem feito evite que quem irá executar a tarefa possa cogitar algo.
Me lembro de um vídeo que vi que a mãe falou para o filho - Vá na padaria e me compre 6 pães, se tiver leite trás 2. O filho aparece em casa só com 2 pães por que tinha leite enquanto a mãe esperava 6 pães e 2 litros de leite.
Sabendo disso, a regra de ouro para trabalhar com LLM é - Que instruções você daria para alguém fazer?. Com essa pequena regra já temos grandes chances de obter uma resposta plausível de um modelo de linguagem. Essa simples regra terá aplicações diretas tanto nos prompts mais simples quanto nas técnicas mais avançadas.
Comece Simples
Comece com o básico. Faça o simples bem feito antes de adicionar complexidade.
Não complique além do necessário. Prompts simples resolvem a maioria dos problemas.
Preços vs Resultados
Você já deve ter notado: quem quer rir, tem que fazer rir.

Empresas oferecem modelos mais baratos e mais caros. Os mais caros entregam melhor resultado, mesmo com prompts simples.
E porque são mais caros?
Mais parâmetros → Quanto mais “neurônios” o modelo tem, mais conexões ele faz e melhor entende contexto, nuances e lógica.
Treinamento com mais dados e mais variados → Modelos grandes foram treinados com muito mais informação de qualidade (livros, códigos, artigos, etc.), então sabem mais coisas.
Ajuste fino com humanos (RLHF) → Eles são ajustados com feedback humano, ou seja, pessoas corrigem as respostas até o modelo aprender a ser mais útil, educado e coerente.
A técnica básica seria usar os modelos mais avançados, mesmo que custe mais caro, e depois conseguir através de melhorias no prompt conseguir gerar um resultado satisfatório em modelos mais baratos para que possamos escalar.
E lembre-se: os modelos caros hoje serão baratos amanhã. A evolução barateia o que era top de linha ontem.
Mesmo com modelos mais inteligentes, as técnicas básicas continuarão sendo úteis para estruturar bem a conversa com a IA — tanto no visual do texto quanto na lógica da interação.
Não exagere. É perda de tempo Às vezes você gasta um tempão refinando algo e, quando consegue, percebe que virou o novo normal. Se a IA não faz hoje, logo vai fazer. O que é sonho hoje é rotina amanhã.
Os computadores estão aprendendo a nossa lingua ao invés de termos que aprender a deles.
Precisamos apenas aprender expressar e comunicar boas idéias do que uma programação complicada.
Web vs API
Mesmo sendo da mesma empresa e usando os mesmos modelos, a assinatura do paga dá acesso só ao uso no app/web, não inclui chamadas via API (chamadas diretamente no endpoint) que é o que usamos para fazer automações.
Já a API é vendida como infraestrutura para desenvolvedores criarem apps, bots, integrações etc., e tem cobrança separada por uso (tokens consumidos).
- Infraestrutura de API é diferente: Ela precisa garantir performance para múltiplos sistemas integrados. O tráfego e controle de custo são outros.
- O Web/app é uso individual: Enquanto API é consumo programático (e pode escalar fácil pra milhares/milhões de chamadas).
- Monetização separada: Um usuário pode usar muito pouco no app, mas gastar muito com API — ou o contrário.
O Que é um Token nesse Contexto?
Precisamos entender sobre tokens quando vamos fazer uma chamada de API.
Um token é uma unidade de texto que o modelo entende. Pode ser uma palavra, parte de uma palavra, ou até símbolos como pontuação.
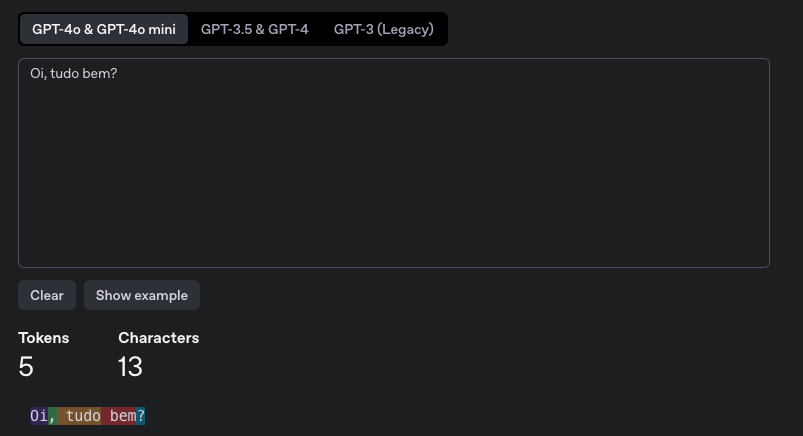
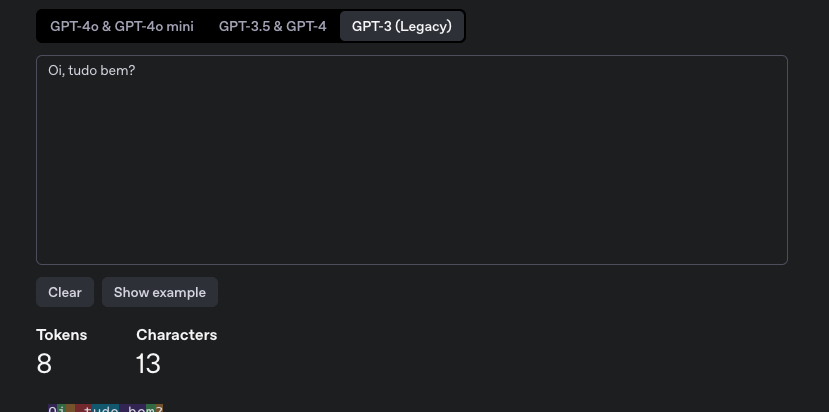
Vamos imaginar que temos um texto simples "Oi, tudo bem?"
Os tokens não são os mesmos se variarmos o modelos, pois a tokenização depende de como o modelo foi treinado. Cada empresa (OpenAI, Google, Anthropic, Mistral, etc.) pode usar algoritmos diferentes para quebrar o texto.
Na OpenAI podemos usar o site https://platform.openai.com/tokenizer para conferir.
Para o modelo GPT-4o temos 5 tokens.
Mas para o modelo GPT-3 temos 8 tokens.
Na Anthropic é necessário uma chamada no endpoint passando a apikey, o modelo e o texto. Temos 15 tokens para o modelo Claude 4.
❯ curl https://api.anthropic.com/v1/messages/count_tokens \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data \
'{
"model": "claude-sonnet-4-20250514",
"messages": [
{"role": "user", "content": "Oi, tudo bem?"}
]
}'
{"input_tokens":15}
Aqui um exemplo de quanto custa 1 Milhão de Token na Anthropic para 3 modelos quando escrevi isso.
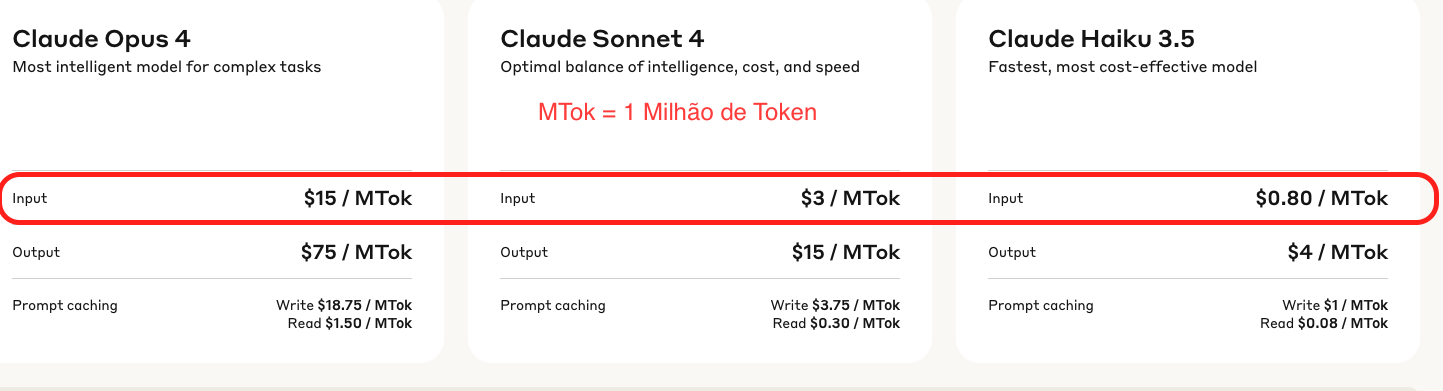
Tomando como base o Claude 3.5, podemos observar que o Claude 4 custa 3.75 vezes mais e o Opus custa 18.75 vezes mais que esse modelo.
A precificação de tokens depende muito da empresa por trás do modelo, então não adianta fazermos uma tabela comparativa que irá mudar o valor.
Como Consumimos Tokens?
Você paga por quantos tokens você envia (Seu prompt completo) e recebe (resposta da IA).
Vamos fazer uma matemática simples para o modelo Claude 3.5 que funciona sob o guarda chuva da Anthropic, logo precisamos usar a precificação deles.
| Tipo | Preço por token |
|---|---|
| Input | $0.80 / 1000000 = $0.0000008 |
| Output | $4.00 / 1000000 = $0.000004 |
Imaginando um exemplo de (500 input / 300 output tokens)
- Input: 500 × 0.0000008 = $0.0004
- Output: 300 × 0.000004 = $0.0012
- Custo real: $0.0016 (pouco mais de 0.001 cent)
A resposta do modelo pode variar, não da para prever totalmente o que virá.
Prompt Caching
É uma técnica pra reaproveitar prompts que você usa com frequência, sem precisar pagar o preço cheio toda vez.
Normalmente você manda um prompt grande tipo:
{
"system": "Você é um assistente técnico que responde como um devsecops sênior.",
"user": "Explique o que é kubernetes."
}
Cada vez que você manda isso, você paga pelo input inteiro.
Com Prompt Caching você salva esse prompt padrão com um ID, tipo:
POST /v1/prompt_cache
{
"id": "meu_prompt_padrao",
"prompt": {
"system": "...",
"user": "..."
}
}
E depois você reusa só o ID.
{
"prompt_id": "meu_prompt_padrao",
"user": "Como melhorar a segurança no cluster?"
}
Falaremos sobre isso com mais detalhes no futuro.
P.R.O.M.P.T Inicial
Na hora de construir um prompt — a conversa com a LLM — é importante seguir um fluxo para organizar as ideias.
O que vem a seguir resolve 80% dos casos:
-
P (PERSONA) – Quem o modelo deve ser?
- Ex: "Você é especialista em segurança da informação."
- LLMs foram treinados com muito conteúdo. Se não direcionarmos, ele pode não saber de onde partir.
-
R (ROTEIRO) – Qual a tarefa?
- Ex: "Quero ajuda para montar uma política de segurança."
-
O (OBJETIVO) – Onde queremos chegar?
- Ex: "Criar uma política clara e aplicável."
-
M (MODELO) – Como deve ser o resultado?
- Ex: "Em formato de lista com tópicos e explicações."
- Nas técnicas avançadas, esse ponto se torna ainda mais poderoso.
-
P (PANORAMA) – Qual o contexto e exemplos?
- Ex: "Organização com 50 colaboradores, ambiente em nuvem, etc."
-
T (TRANSFORMAR) – O que mudar, melhorar ou ajustar?
- Ex: "Agora troque Azure por AWS, e acrescente um exemplo prático."
- Nem sempre a primeira resposta será perfeita. Pode ser necessário interagir com a IA ou até usar self-refinement, como veremos em técnicas futuras.
Processo
Seguiu a estrutura acima e resolveu? Beleza. Mas e quando o prompt exige mais raciocínio lógico? Aí entra o processo:
-
Defina tarefas e critérios de sucesso. Muita gente começa um prompt (ou até um projeto inteiro) sem saber onde quer chegar.
- Desempenho e precisão: Quão bem o modelo precisa ir? Às vezes uma resposta genérica já resolve.
- Latência: Qual o tempo aceitável de resposta? Modelos maiores pensam mais, mas respondem melhor. Porém uma resposta curta e prática pode ser suficiente para o propósito.
- Preço: Qual o orçamento? Avalie custo por chamada, tamanho do modelo, frequência de uso.
-
Desenvolva casos de teste: Como saber se você está perto do resultado ideal?
- Crie exemplos genéricos (80%) e alguns de exceção (casos de borda).
-
Escreva o prompt inicial com base na estrutura P.R.O.M.P.T.
-
Teste com os exemplos
- Avalie os resultados manualmente ou use outra LLM para isso — até com sugestões de melhoria.
-
Refine o prompt com base nos resultados
- Esse é o ciclo: 4, 5, 4, 5, 4, 5... até acertar.
-
Coloque em produção. Quando o prompt for confiável, pronto — pode escalar!