Pod Network Interface
Falamos sobre a rede que conecta os nós, mas há também outra camada de rede que é crucial para o funcionamento dos clusters, que é a rede na camada do pod.
Nosso cluster do Kubernetes em breve terá um grande número de pods e serviços em execução.
Como os pods são tratados? Como eles se comunicam entre si? Como você acessa os serviços em execução nesses pods internamente, de dentro do cluster, e externamente, de fora do cluster?
O Kubernetes não vem com uma solução integrada para isso, ele espera que você implemente uma solução de rede que resolva esses desafios. No entanto, o Kubernetes definiu claramente os requisitos para a rede de pods. O Kubernetes espera que:
- cada pod obtenha seu próprio endereço IP exclusivo e que cada pod possa alcançar todos os outros pods no mesmo nó usando esse endereço IP.
- cada pod deve ser capaz de alcançar todos os outros pods em outros nós também usando o mesmo endereço IP. Não importa qual é o endereço IP e a que intervalo ou sub-rede ele pertence.
Contanto que você possa implementar uma solução que cuide da atribuição automática de endereços IP e estabeleça a conectividade entre os pods em um nó, bem como entre os pods em nós diferentes, não haverá problema.
Então, como você implementaria um modelo que atende a esses requisitos?
Há muitas soluções de rede disponíveis que fazem isso, mas como é um estudo, vamos tentar usar o que o que aprendemos para resolver esse problema por nós mesmos primeiro para ajudará a entender como outras soluções funcionam.
Vamos imaginar que temos um cluster de três nós. Não importa se é master ou worker, pois todos executam pods.
Os nós fazem parte de uma rede externa e têm endereços.
- master1 (192.168.0.1)
- worker1 (192.168.0.2)
- worker2 (192.168.0.3)
Quando os contêineres são criados, o container runtime utilizado nos nodes do kubernetes cria espaços os networks namespaces para eles. Para permitir a comunicação entre eles precisamos anexar esses namespaces a uma rede bridge como vimos anteriormente.
Para respeitar o que o CNI definiu precisaríamos criar uma interface bridge em cada nó que deve ser pertencer a uma rede diferente. O containers precisariam receber IPs diferentes também..
Teríamos então.
- master1 bridge 10.244.1.1 (rede é 10.244.1.0/24)
- containers teriam ip 10.244.1.2, 10.244.1.3, 10.244.1.4
- node1 bridge 10.244.2.1 (rede é 10.244.2.0/24)
- containers teriam ip 10.244.2.2, 10.244.1.3, 10.244.1.4
- node2 bridge 10.244.3.1 (rede é 10.244.3.0/24)
- containers teriam ip 10.244.3.2, 10.244.3.3, 10.244.3.4
Criamos uma rede em bridge em cada nó, ativamos a interface e atribuímos um endereço IP e definimos o ip acima proposto.
As etapas restantes devem ser executadas para cada contêiner e sempre que um novo contêiner for criado, portanto, escrevemos um script para isso.
Nesse script teríamos os seguintes passos.
- Criar um pipe ou de um cabo de rede virtual. Criamos isso usando o comando ip link add.
- Conectar uma extremidade ao contêiner e a outra extremidade à bridge usando o comando ip link set.
- Atribuir o endereço IP usando o comando ip addr e adicionamos uma rota ao gateway padrão. Mas qual IP adicionamos? Nós mesmos gerenciamos isso ou armazenamos essas informações em algum tipo de banco de dados. Por enquanto, assumiremos essa função pega um IP livre na sub-rede.pegar um IP na rede bridge que não esta sendo usado.
- Ativar as interfaces criadas
Os containers no mesmo node podem se comunicar entre si agora dentro do mesmo node.
Copiamos o script para os outros nós e executamos o script neles para atribuir o endereço IP e conectar esses contêineres às suas próprias redes internas. Resolvemos a primeira parte do desafio. Todos os pods recebem seu próprio endereço IP exclusivo e podem se comunicar uns com os outros em seus próprios nós.
A próxima parte é permitir que eles alcancem outros pods em outros nós. Digamos, por exemplo, que o pod esteja em 10.244.2.2 no node1 deseja fazer ping no pod 10.244.3.2 no node2.
Até o momento, o primeiro não tem ideia de onde está o endereço 10.244.3.2 é porque ele está em uma rede diferente da sua.
Portanto, ele encaminha para o IP da bridge, pois ele está configurado como o gateway padrão. O nó um também não sabe desde o 10. 244. 2. 2 é uma rede privada no nó dois.
Adicione uma rota à tabela de roteamento do nó um para rotear o tráfego para 10. 244. 2. 2 em que o IP do segundo nó é 192. 168. 1. 12.
Depois que a rota é adicionada, o pod azul pode fazer ping.
Em vez de configurar rotas em cada servidor, uma solução melhor é fazer isso em um roteador, se houver um em sua rede, e indicar a todos os hosts que o usem como gateway padrão. Dessa forma, você pode gerenciar facilmente as rotas para todas as redes na tabela de roteamento do roteador.
Com isso, as redes virtuais individuais que criamos com o endereço 10. 244. 1. 0/24 em cada nó agora formam uma única rede grande com o endereço 10. 244. 0. 0/16.
É hora de unir tudo.
Executamos várias etapas manuais para preparar o ambiente com as redes bridge e as tabelas de roteamento.
Em seguida, escrevemos um script que pode ser executado para cada contêiner e que executa as etapas necessárias para conectar cada contêiner à rede. E executamos o script manualmente.
É claro que não queremos fazer isso como em ambientes grandes em que milhares de pods são criados a cada minuto.
Então, como executamos o script automaticamente quando um pod é criado no Kubernetes?
É aí que a CNI entra, atuando como intermediária. A CNI informa ao Kubernetes que é assim que você deve chamar um script assim que criar um contêiner.
E a CNI nos diz: "É assim que seu script deve ser. Portanto, precisamos modificar um pouco o script para atender aos padrões da CNI.
Ele deve ter uma seção de adição (ADD) que se encarregará de adicionar um contêiner à rede e uma seção de exclusão (DEL) que se encarregará de excluir as interfaces do contêiner da rede e liberar o endereço IP, etc.
Portanto, nosso script está pronto.
O container runtime em cada nó é responsável pela criação de contêineres.
Sempre que um contêiner é criado, o container runtime examina a configuração da CNI passada como argumento de linha de comando quando foi executado e identifica o nome do nosso script.
Em seguida, ele procura no diretório bin dos CNIs para encontrar o nosso script e, em seguida, executa o script com o comando add e o nome e o ID do namespace do contêiner, e o nosso script cuida do resto.
Os plubins, scripts que fazem o trabalho repetitivo, ficam em /opt/cni/bin/
root@kind-cluster-worker:/etc/cni/net.d# ls -lha /opt/cni/bin
total 15M
drwxr-xr-x 2 root root 4.0K Feb 2 00:14 .
drwxr-xr-x 3 root root 4.0K Feb 2 00:14 ..
-rwxr-xr-x 1 root root 3.4M Feb 2 00:12 host-local
-rwxr-xr-x 1 root root 3.4M Feb 2 00:12 loopback
-rwxr-xr-x 1 root root 3.8M Feb 2 00:12 portmap
-rwxr-xr-x 1 root root 4.2M Feb 2 00:12 ptp
E a configuração fica em /etc/cni/net.d/. Se tivesse mais de um arquivo nessa pasta, ele iria pegar o primeiro de acordo com a ordem lexicográfica.
root@kind-cluster-worker:/etc/cni/net.d# ls /etc/cni/net.d/
10-kindnet.conflist
Analisando esse arquivo 10-kindnet.conflist que é um arquivo de configuração de cni usado pelo kind
{
"cniVersion":"0.3.1",
"name":"kindnet",
"plugins":[
{
"type":"ptp",
"ipMasq":false,
"ipam":{
"type":"host-local",
"dataDir":"/run/cni-ipam-state",
"routes":[
{
"dst":"0.0.0.0/0"
}
],
"ranges":[
[
{
"subnet":"10.244.2.0/24"
}
]
]
},
"mtu":1500
},
{
"type":"portmap",
"capabilities":{
"portMappings":true
}
}
]
}
Mas vamos tentar procurar onde é mostrado a configuração que aponta para esse cni.
Quem é responsável por criação de containers no kubernetes? Kubelet, então é lá que precisamos conferir.
O kubelet não é executado como um pod, então vamos ver o que service que o define.
root@kind-cluster-worker:/etc/systemd/system# cat /etc/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=http://kubernetes.io/docs/
ConditionPathExists=/var/lib/kubelet/config.yaml
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=1s
CPUAccounting=true
MemoryAccounting=true
Slice=kubelet.slice
KillMode=process
[Install]
WantedBy=multi-user.target
root@kind-cluster-worker:/etc/systemd/system#
#Vamos olhar o que temos aqui ConditionPathExists=/var/lib/kubelet/config.yaml
root@kind-cluster-worker:/etc/systemd/system# cat /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
cgroupRoot: /kubelet
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionHard:
imagefs.available: 0%
nodefs.available: 0%
nodefs.inodesFree: 0%
evictionPressureTransitionPeriod: 0s
failSwapOn: false
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageGCHighThresholdPercent: 100
imageMaximumGCAge: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
root@kind-cluster-worker:/etc/systemd/system# ps -aux | grep kubelet
root 216 1.5 0.1 2998920 87512 ? Ssl Feb28 15:19 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///run/containerd/containerd.sock --node-ip=172.18.0.3 --node-labels= --pod-infra-container-image=registry.k8s.io/pause:3.9 --provider-id=kind://docker/kind-cluster/kind-cluster-worker --runtime-cgroups=/system.slice/containerd.service
root 10841 0.0 0.0 3324 1664 pts/1 S+ 14:51 0:00 grep kubelet
Já que não encontramos nada, vamos recriar o nosso kind cluster, mas agora desativando cni default para instalar outro. Já vamos aproveitar melhorar algumas coisas na configuração que vamos passar para o kind.
Desinstale o cluster anterior
kind delete cluster
Crie um arquivo chamado king-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: cka-cluster
networking:
ipFamily: ipv4
disableDefaultCNI: true
kubeProxyMode: "ipvs"
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
kind create cluster --config kind-config.yaml
Creating cluster "cka-cluster" ...
✓ Ensuring node image (kindest/node:v1.29.1) 🖼
✓ Preparing nodes 📦 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-cka-cluster"
You can now use your cluster with:
kubectl cluster-info --context kind-cka-cluster
Thanks for using kind! 😊
# Node ready nodes
k get nodes
NAME STATUS ROLES AGE VERSION
cka-cluster-control-plane NotReady control-plane 34s v1.29.1
cka-cluster-worker NotReady <none> 13s v1.29.1
cka-cluster-worker2 NotReady <none> 11s v1.29.1
cka-cluster-worker3 NotReady <none> 12s v1.29.1
E agora vamos instalar o [weave cni[(https://github.com/weaveworks/weave/releases)].
kubectl apply -f https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
serviceaccount/weave-net created
clusterrole.rbac.authorization.k8s.io/weave-net created
clusterrolebinding.rbac.authorization.k8s.io/weave-net created
role.rbac.authorization.k8s.io/weave-net created
rolebinding.rbac.authorization.k8s.io/weave-net created
daemonset.apps/weave-net created
kubectl get nodes
NAME STATUS ROLES AGE VERSION
cka-cluster-control-plane Ready control-plane 110s v1.29.1
cka-cluster-worker Ready <none> 89s v1.29.1
cka-cluster-worker2 Ready <none> 87s v1.29.1
cka-cluster-worker3 Ready <none> 88s v1.29.1
kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 4 4 4 4 4 kubernetes.io/os=linux 3m15s
weave-net 4 4 4 4 4 <none> 103s
Agora vamos conferir as coisas novamente.
root@cka-cluster-worker:/etc/cni/net.d# cat /etc/cni/net.d/10-weave.conflist
{
"cniVersion": "0.3.0",
"name": "weave",
"plugins": [
{
"name": "weave",
"type": "weave-net",
"hairpinMode": true
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"snat": true
}
]
}
# Temos plugins diferentes pois usamos o weavenet ao inves do kindnet
root@cka-cluster-worker:/etc/cni/net.d# ls /opt/cni/bin/
host-local loopback portmap ptp weave-ipam weave-net weave-plugin-latest
ps -aux | grep kubelet
root 251 2.0 0.1 2998152 84476 ? Ssl 18:16 0:08 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///run/containerd/containerd.sock --node-ip=172.18.0.5 --node-labels= --pod-infra-container-image=registry.k8s.io/pause:3.9 --provider-id=kind://docker/cka-cluster/cka-cluster-worker --runtime-cgroups=/system.slice/containerd.service
Ainda não encontramos nada analisando outros materiais de estudo vimos que no service poderíamos passar os parâmetros para avisar onde esta a pasta do plugin.
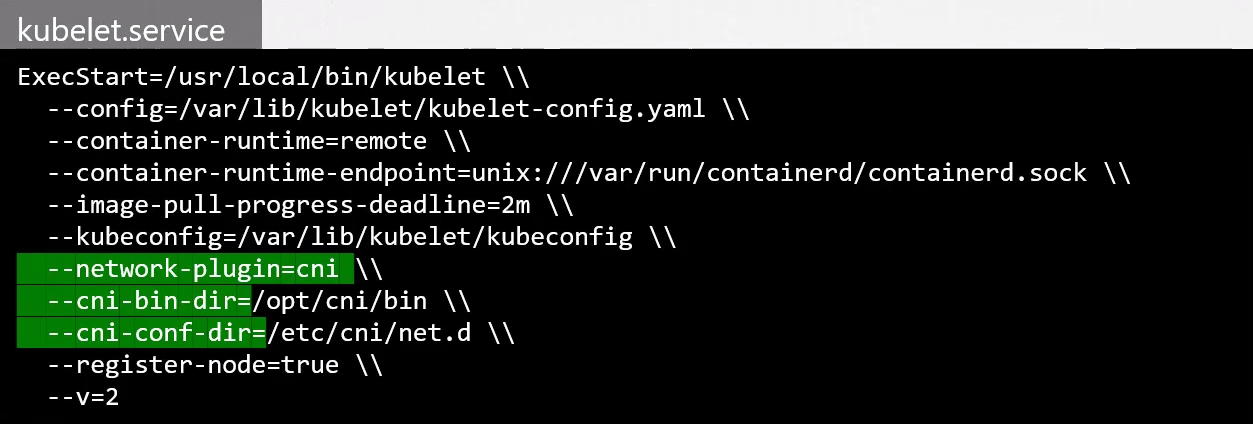
CNI Plugin
Vamos nos aprofundar melhor em uma solução de CNI e os conceitos podem ser aplicados ao restante. Vamos tomar como exemplo o Weave.
A solução que usamos até agora mapeava quais redes estão em quais hosts, enquanto quando um pacotes era enviado de um pod para outro, ele segue o fluxo de ir para a rede, depois para o roteador, depois o host e depois para outro pod. Mas essa solução não funciona bem com milhares de pods e centenas de nodes. A tabela de roteamento pode nao suportar tantas entradas e precisamos ser criamos e encontrar novas soluções.
Pensando no kubernetes como uma empresa e os nodes filiais. Dentro das filiais temos diferentes setores com diferentes departamentos. Se fosse dentro da mesma cidade ou em um país pequeno, poderíamos criar um sistema de logística e contratar um office boy que levaria os documentos de um lado para outro. Ninguém precisa saber o endereço das filiais e colocaríamos nas correspondências somente:
- Nome da filial
- Nome do setor
- NOme do departamento
- Nome do destinatário
Se o office boy vai de carro, ônibus, moto, carro ou bicicleta é problema dele. Só precisa entregar! Quem tem que saber onde é o endereço das filiais é ele.
Se a empresa possui filiais em diferentes países um office boy não é suficiente, então precisaríamos melhorar nosso sistema terceirizando o serviço de entrega. Então podemos contratar uma empresa que colocará um agente responsável por cada país ou área. Os documentos seriam entregues sempre entre os agentes e esses são responsáveis por resolver a entrega dentro da sua responsabilidade.
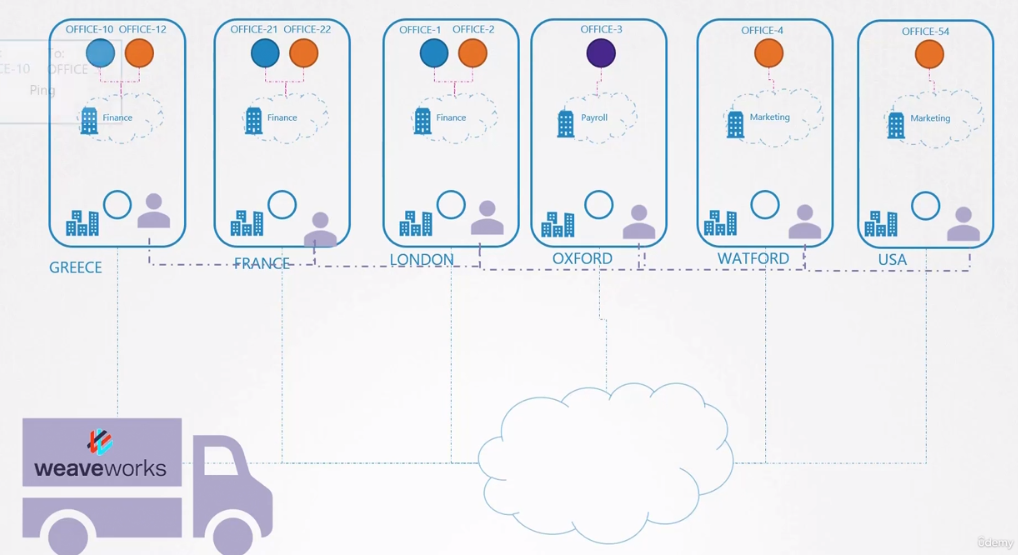
Voltando para o nosso CNI, vimos acima que o Weavenet cria um daemonset, ou seja, um pod (agente) por node (país). Esses agentes conhecem a topologia de toda a rede pois se comunicam entre si. Eles se comunicam entre si para trocar informações sobre os nós, as redes e os pods dentro deles. Cada agente ou par armazena uma topologia de toda a configuração. Dessa forma, eles conhecem os pods e seus IPs nos outros nós. A Weave cria sua própria Bridge nos nós com o nome de weave e atribui um endereço IP a cada rede.
# WORKER-1
root@cka-cluster-worker:/# ip link show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether e2:0f:fd:ef:ad:fa brd ff:ff:ff:ff:ff:ff
root@cka-cluster-worker:/# ip addr show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether e2:0f:fd:ef:ad:fa brd ff:ff:ff:ff:ff:ff
inet 10.40.0.0/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
# WORKER-2 Veja que inicia com 10.32
root@cka-cluster-worker2:/# ip link show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 5e:56:a8:56:6e:f4 brd ff:ff:ff:ff:ff:ff
root@cka-cluster-worker2:/# ip addr show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether 5e:56:a8:56:6e:f4 brd ff:ff:ff:ff:ff:ff
inet 10.34.0.0/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
root@cka-cluster-worker2:/#
Lembre-se de que um único pod pode estar conectado a várias redes bridge. Tudo depende das rotas configuradas no namespaces. Por exemplo, você pode ter um pod anexado ao Weave Bridge, bem como ao Docker Bridge criado pelo Docker.
O caminho que um pacote percorre para chegar ao seu destino depende da rota configurada no contêiner.
O Weave garante que os pods obtenham a rota correta configurada para alcançar o agente, e o agente cuida dos outros pods. Agora, quando um pacote é enviado de um pod para outro em outro nó, o Weave intercepta o pacote e identifica que ele está em uma rede separada, encapsulando-o em um novo pacote com nova origem e destino e enviando-o pela rede. Do outro lado, o agente Weave recupera o pacote, descapsula-o e o encaminha para o pod correto.
O Weave e os Weave Peers podem ser implantados como services ou daemons em cada nó do cluster manualmente ou, se o Kubernetes já estiver configurado, uma maneira mais fácil de fazer isso é implantá-los como pods no cluster como fizemos com o apply no kind.
Quando o sistema Kubernetes básico estiver pronto, com os nós e a rede configurados corretamente entre os nós e os componentes básicos do plano de controle implantados, o Weave poderá ser implantado no cluster com um único comando kubectl apply que implementa todos os componentes necessários para o Weave no cluster. O mais importante é que os pares do Weave são implantados como um conjunto de daemons.
kubectl get pods -A -n kube-system -o wide | grep weave
kube-system weave-net-29ffl 2/2 Running 4 (4h4m ago) 23h 172.18.0.2 cka-cluster-worker <none> <none>
kube-system weave-net-4q8kr 2/2 Running 4 (4h4m ago) 23h 172.18.0.4 cka-cluster-worker3 <none> <none>
kube-system weave-net-8zxbw 2/2 Running 5 (4h4m ago) 23h 172.18.0.3 cka-cluster-worker2 <none> <none>
kube-system weave-net-phbz8 2/2 Running 4 (4h4m ago) 23h 172.18.0.5 cka-cluster-control-plane <none> <none>
Uma coisa importante é que quando aplicamos o yaml do Weavenet é bom conferir o CIDR no configmap do kube-proxy e aplicar o mesmo.
kubectl describe cm -n kube-system kube-proxy | grep CIDR
clusterCIDR: 10.244.0.0/16
excludeCIDRs: null
Se conferirmos o que vem default no yaml.
wget https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
# Vamos conferir as definições do container weave no item daemonset
cat weave-daemonset-k8s.yaml
# Removido para cima
- apiVersion: apps/v1
kind: DaemonSet
metadata:
name: weave-net
labels:
name: weave-net
namespace: kube-system
spec:
# Removido esta parte para ficar fácil a leitura aqui!
containers:
- name: weave
command:
- /home/weave/launch.sh
env:
##############################################
# não temos uma variável que definir o CIDR que vamos usar então podemos colocar
- name: IPALLOC_RANGE # ADICIONE
value: 10.244.0.0/16
###############################################
- name: INIT_CONTAINER
value: "true"
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
Para fins de solução de problemas, visualize os registros usando o comando kubectl logs.