Multiple Schedulers
Podemos ter diferentes schedulers no cluster. O que precisamos fazer é passar qual scheduler queremos usar no pod. Esse scheduler será o responsável por ler a configuração do pod e escolher o node correto.
É necessários que os schedulers tenham diferentes nomes.
Vamos pegar um pod qualquer que temos no nosso cluster.
k get pods busybox -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-03-18T03:06:56Z"
labels:
run: busybox
name: busybox
namespace: default
resourceVersion: "2879304"
uid: b055b81d-96d4-4fe7-8666-635a9d03f4bf
spec:
containers:
- command:
- sleep
- "1000"
image: busybox
imagePullPolicy: Always
name: busybox
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-xxwlk
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: cka-cluster-worker3
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler #<<<
...
Podemos observar que mesmo que não foi definido um scheduler, temos o default-scheduler. Poderíamos passar um outro scheduler no spec.
A maneira mais simples de criar um scheduler é deployando outro.
O cluster kind cria o scheduler como pod ao invés de service, o que podemos fazer? Criar outro, mas passando as configurações específicas.
Vamos analisar a configuração do kube-scheduler. Esse é o scheduler que o próprio kind criou com o kubeadm.
kubectl get pods -n kube-system kube-scheduler-cka-cluster-control-plane -o=jsonpath='{.spec.containers[*].command}' | jq
[
"kube-scheduler",
"--authentication-kubeconfig=/etc/kubernetes/scheduler.conf",
"--authorization-kubeconfig=/etc/kubernetes/scheduler.conf",
"--bind-address=127.0.0.1",
"--kubeconfig=/etc/kubernetes/scheduler.conf",
"--leader-elect=true"
]
Podemos colocar outro scheduler e passar o --config com o arquivo de configuração que vamos criar.
Se vamos criar esse scheduler em todos os masters precisamos definir o --leader-elect=true. Poderíamos criar o scheduler utilizando static pods indo dentro do master e colocando o manifesto em /etc/kubernetes/manifest.
Na documentação temos um modelo usando o próprio scheduler oficial.
Neste conjunto de manifestos temos.
- Service account
- 2 Cluster role binding que darão a permissão para o service account no mesmo grupo do kube-scheduler
system:kube-schedulere emsystem:volume-scheduler - 1 Role binding que dará permissão em do service account em
extension-apiserver-authentication-reader - O configmap que será montado como volume afim de prover um arquivo de configuração. Com isso podemos colocar todos os parâmetros dentro dele e diminuir o monte de entrada acima.
Crie um arquivo com o conteúdo abaixo e aplique no cluster.
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-kube-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-volume-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:volume-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: my-scheduler-extension-apiserver-authentication-reader
namespace: kube-system
roleRef:
kind: Role
name: extension-apiserver-authentication-reader
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
---
## Aqui podemos definir um configmap que será montado como volume afim de nos entregar este arquivo.
apiVersion: v1
kind: ConfigMap
metadata:
name: my-scheduler-config
namespace: kube-system
data:
my-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: true # Era false alterado para true para testar com 3 replicas.
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 3 #<< Era 1 , alterado para 3
template:
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: registry.k8s.io/kube-scheduler:v1.29.1 # Alterada pois não temos a imagem antiga
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-config
kubectl apply -f my-scheduler.yaml
serviceaccount/my-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-kube-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-volume-scheduler created
rolebinding.rbac.authorization.k8s.io/my-scheduler-extension-apiserver-authentication-reader created
configmap/my-scheduler-config created
deployment.apps/my-scheduler created
k get pods -n kube-system | grep my-scheduler
my-scheduler-8ffc64976-449zr 1/1 Running 0 92s
my-scheduler-8ffc64976-6hn6t 1/1 Running 0 92s
my-scheduler-8ffc64976-nj8xp 1/1 Running 0 92s
Algumas coisas que podemos analisar.
- O master possui taints e não definimos nenhum tolerations para que ele possar ir para o master. Ele não irá.
- Não definimos nenhum nodeAffinity ou podAntiAffinity para que ele possa distribuir as 3 replicas em diferentes nodes. Se acontecer é mera coincidência.
- O scheduler default que schedulou esses pods!
Agora vamos usar esse scheduler para criar um pod
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
schedulerName: my-scheduler
EOF
k describe pod nginx | grep scheduler
Normal Scheduled 56s my-scheduler Successfully assigned default/nginx to cka-cluster-worker3
Scheduler Profiles
Um scheduler possui uma fila para agendar os pods. Se todos tem a mesma prioridade então eles vão entrando no fim da fila e seguindo o fluxo. Quem chega primeiro é o primeiro a ser escalado.
É possível configurar prioridades diferentes e vincular um pod a esta prioridade. Dessa forma é possível que pods de alta prioridade furem a fila. Isso é bastante útil se um serviço realmente não pode esperar.
Para definir uma prioridade podemos criar como definido abaixo. Esse não é um recurso a nível de namespace, mas a nível do cluster. Um scheduler olha para todos os pods independente do namespace.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false # Se será o default ou não
description: "This priority class should be used for XYZ service pods only."
Já existem dois definidos no cluster.
k get priorityclasses.scheduling.k8s.io -o wide
NAME VALUE GLOBAL-DEFAULT AGE
system-cluster-critical 2000000000 false 18d
system-node-critical 2000001000 false 18d
Quando chegar a vez do pod de ser schedulado ele vai para etapa de filtragem. Os nodes que não podem receber o pod, seja por falta de recurso ou por escolha do usuário usando nodeSelector, affinities, taints e tolerations serão eliminado e somente aquele que passaram pela filtragem poderão schedular o pod.
Por último temos a etapa de score. Esta etapa selecionará qual dos nodes que sobraram é o melhor para subir o pod. Como essa pontuação é definida? Se um pod precisa de 2 cpus e temos dois nodes possíveis sendo o primeiro com 2 cpus disponíveis e o segundo com 6 obviamente o que tem 6 já possui um score maior. Nesse caso ambos teriam memória suficiente para rodar o pod senão nem teriam passado pela etapa de filtragem.
Por último temos o processo de binding que é quando de fato o node é definido e o Kubelet daquele node será responsável por subir o pod.
As etapas são:
- Scheduling Queue
- Filtering
- Scoring
- Binding
Todas essas operações são realizadas com certos plugins.
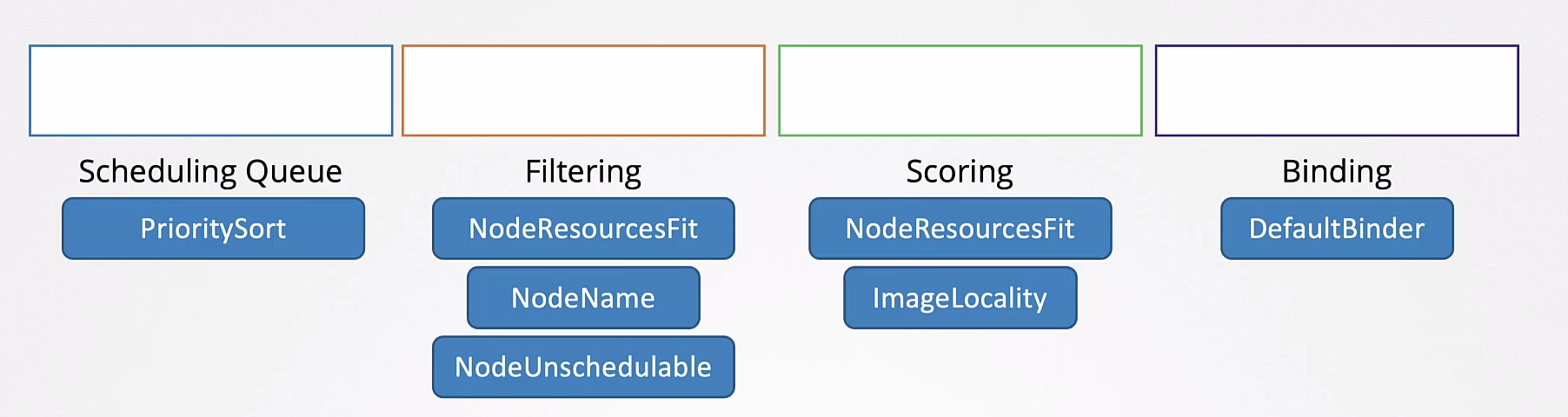
Um plugins pode estar associado em mais de uma etapa.
Uma curiosidade é que na etapa de score, temo um plugin chamado ImageLocality. Um node que já possui a imagem disponível pode ter uma score maior.
Essas etapas podem ser ainda subdivididas utilizando diferentes plugins que analisam de forma diferentes.
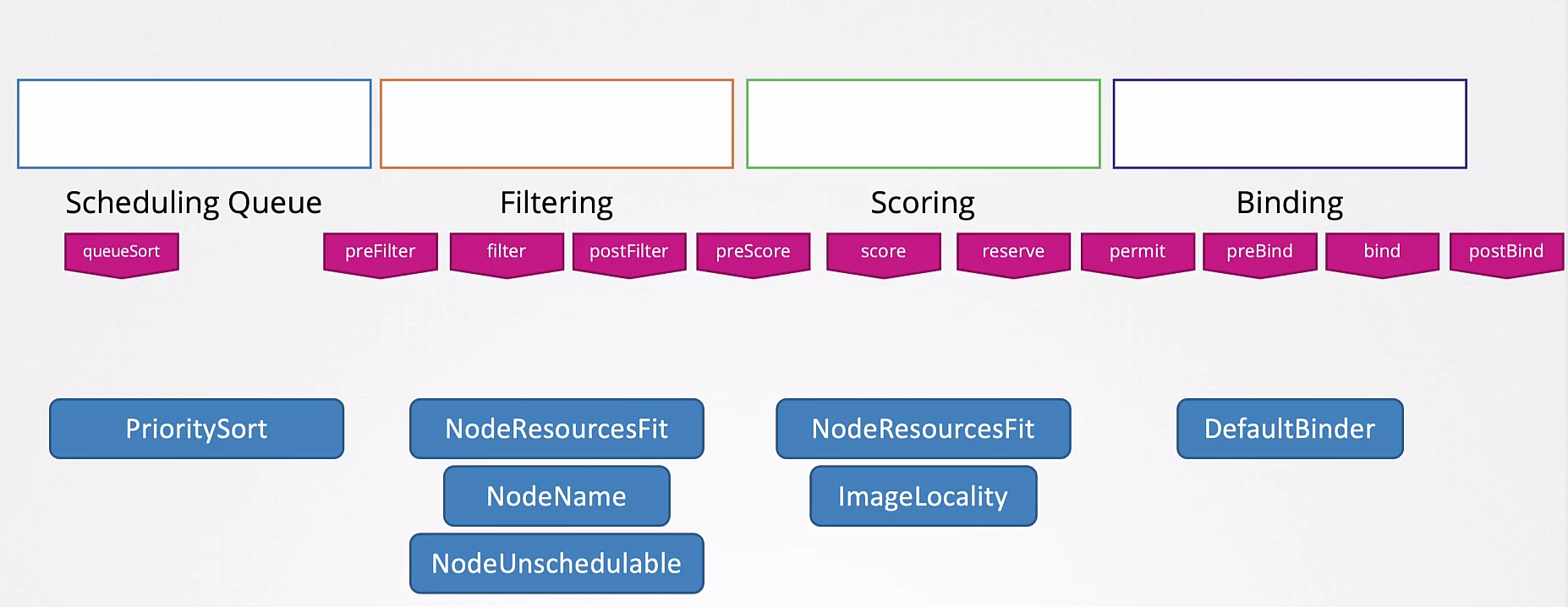
Você pode escrever seus próprio métodos de scheduler.
Uma situação que pode ocorrer de ter vários scheduler diferentes é que cada um pode ter regras completamente diferentes, lendo e interpretando os nodes de forma diferente criando uma condição de corrida.
Para evitar isso é interessante ter um scheduler com vários profiles. Dessa forma o mesmo binário estaria sendo usado para todo mundo.
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
plugins:
score:
disabled:
- name: TaintToleration
enabled:
- name: MyCustomPluginA
- name: MyCustomPluginB
- schedulerName: my-scheduler2
plugins:
preScore:
disabled:
- name: '*'
- schedulerName: my-scheduler3
leaderElection:
leaderElect: true # Era false alterado para true para testar com 3 replicas.