Conceitos de Observabilidade
A observabilidade representa uma mudança fundamental na forma como monitoramos sistemas, permitindo compreendê-los de fora para dentro. Diferentemente do monitoramento tradicional, a observabilidade possibilita fazer perguntas sobre o sistema sem necessariamente conhecer seu funcionamento interno detalhado. Esta capacidade é especialmente crucial para identificar e resolver não apenas problemas conhecidos, mas também "problemas desconhecidos" - aqueles que não poderíamos antecipar.
Para alcançar uma observabilidade efetiva, os sistemas precisam ser adequadamente instrumentados. A instrumentação consiste na capacidade do código em emitir sinais que nos permitem entender seu comportamento. O OpenTelemetry (OTel) se concentra inicialmente em três tipos fundamentais de sinais:
- Traces (Rastreamentos): Permitem visualizar o caminho de uma requisição através de diferentes serviços
- Métricas: Fornecem dados quantitativos sobre o desempenho do sistema
- Logs: Registram eventos específicos do sistema
É importante notar que, embora o OpenTelemetry comece com estes três pilares, sua arquitetura foi projetada para expandir e incorporar outros tipos de telemetria conforme a tecnologia evolui.
Contexto da Computação Moderna
O OpenTelemetry surgiu como resposta às necessidades específicas da era cloud-native, onde os aplicativos são caracterizados por:
- Arquiteturas distribuídas
- Componentes serverless
- Execução em containers
- Comunicação intensa entre diferentes serviços
Neste contexto, o rastreamento distribuído (distributed tracing) ganha especial importância, pois permite visualizar e compreender o fluxo de dados através de múltiplos serviços e componentes.
A eficácia da observabilidade pode ser medida diretamente pelo seu impacto nos indicadores de negócio, especialmente:
- Mean Time To Detection (MTTD): Tempo para detectar um problema
- Mean Time To Resolution (MTTR): Tempo para resolver um problema
- Disponibilidade do serviço (Service Level Objectives - SLOs)
Evolução do Monitoramento
Para contextualizar a importância do OpenTelemetry, é útil comparar com o cenário tradicional:
Aplicações Monolíticas:
- Execução em um único processo
- Comunicação direta com banco de dados
- Diagnóstico centralizado
- Análise cronológica simplificada
Aplicações Modernas
- Múltiplos serviços distribuídos
- Comunicação assíncrona
- Dependências complexas
- Necessidade de correlação entre diferentes sinais
Esta evolução destaca por que ferramentas tradicionais de monitoramento não são mais suficientes para sistemas modernos, e por que precisamos de uma abordagem mais sofisticada como o OpenTelemetry.
Dificuldades para Encontrar o Problema
Em um cenário que temos o monolito que perde a comunicação com o banco de dados geralmente íamos direto nos logs para procurar os registros de tudo que aconteceram, pois eles estavam em uma ordem cronológico e em um só lugar.

O problema começa a surgir quando um sistema chama outro sistema que chama outro. Se tivessemos a seguinte estrutura onde podería estar o problema?
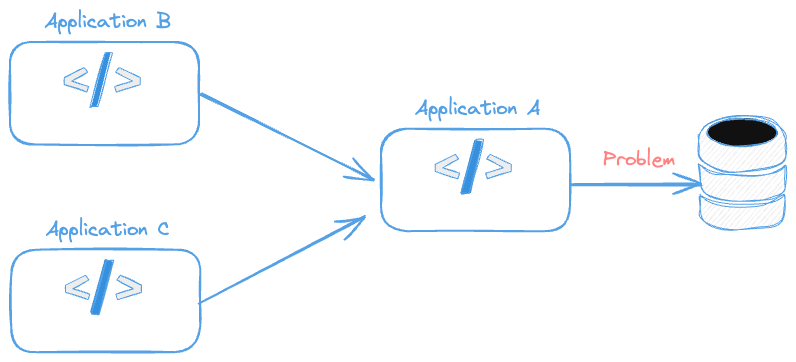
- Aplicativo A não não consegue se comunicar com o banco.
- Aplicativo B não consegue se comunicar com o Aplicativo A e cause alguma falha no banco de dados.
- Aplicativo C não consegue se comunicar com o Aplicativo A e cause alguma falha no banco de dados.
E isso irá ficar cada vez mais complexo.
Se fosse adicionado a informação que o Aplicativo B sempre funciona com o Aplicativo A saberíamos B e A funcionam, ou seja, não temos problema entre ele e a comunicação com o DB está de pé. Sendo assim já saberíamos que o problema esta no Aplicativo C.
É nisso que o trace ajuda, a entender a história entre os diferentes componentes.
- O log nos informará o processo único da história do aplicativo e o que aconteceu nesse processo.
- As métricas no ajudam a ver a saúde da aplicação.
- O trace o contexto, ou seja, o caminho, o caminho distribuído entre os diferentes componentes.
Assim será possível entender como os componentes estão se comunicando uns com os outros.
Logs
Um log é um registro temporal de um evento que ocorreu em um sistema. É como uma "anotação digital" que contém:
- Um timestamp (data e hora do evento)
- Uma mensagem descrevendo o que aconteceu
- Geralmente também inclui um nível de severidade (como ERROR, WARN, INFO, DEBUG)
Por exemplo, quando você faz login em um site, o sistema pode gerar um log assim:
2024-01-14 10:30:15 [INFO] Usuário 'joão123' realizou login com sucesso
Os logs são independentes - ou seja, eles não precisam estar necessariamente ligados a uma ação específica do usuário ou transação. Podem registrar qualquer tipo de evento do sistema, desde erros até operações rotineiras.
Uma característica importante dos logs é que eles são como "fotografias" de momentos específicos - registram o que aconteceu naquele instante, mas não mostram automaticamente o caminho que levou até aquele evento ou o que aconteceu depois.
Métricas
Métricas são dados numéricos que representam o estado ou comportamento de um sistema ao longo do tempo. São medidas quantitativas que, quando coletadas e analisadas, ajudam a entender o desempenho, a saúde e a utilização de recursos de uma aplicação ou infraestrutura.
Tipos Comuns de Métricas
- Contadores: Números que apenas aumentam (ex: total de requisições recebidas)
- Medidores: Valores que podem aumentar ou diminuir (ex: usuários ativos)
- Histogramas: Distribuição de valores em intervalos (ex: tempo de resposta)
Exemplos Práticos
- Taxa de erros por minuto
- Uso de CPU e memória
- Tempo médio de resposta das requisições
- Número de usuários conectados
- Quantidade de transações por segundo
- Espaço em disco disponível
- Tamanho da fila de processamento
Vale a pena uma leitura também sobre os service levels da observabilidade para entender onde esses números podem nos ajudar.
Traces: Rastreamento Distribuído
Um trace (rastro) é como uma "história" que mostra a jornada completa de uma requisição através de um sistema distribuído. Imagine uma linha do tempo detalhada que registra cada etapa que uma requisição percorre, desde o momento em que entra no sistema até sua conclusão. Conceitos Fundamentais
Trace é a jornada completa de uma requisição. Composto por uma série de spans (trechos) conectados e identificado por um trace ID único.
Mostra o fluxo end-to-end através de diferentes serviços
Um Span (Trecho) representa uma única operação dentro do trace. Pode ser uma chamada HTTP, consulta de banco de dados, ou processamento interno e contém informações cruciais:
- Nome da operação
- Timestamps (início e fim)
- Duração
- Status da operação
- Atributos (metadados)
- Eventos importantes durante a execução
Spans se organizam em uma estrutura pai-filho. Um span pai pode ter múltiplos spans filhos Cada span filho representa uma sub-operação do span pai. Por exemplo, quando você faz login em um site, um trace pode mostrar:
- Recebimento da requisição de login
- Validação das credenciais
- Consulta ao banco de dados
- Geração do token de acesso
- Retorno da resposta
Esta estrutura permite identificar rapidamente onde estão os gargalos de performance ou onde ocorrem erros em sistemas distribuídos.
Vamos demonstrar um trace visualmente usando o Jaeger-UI. De forma gráfica temos algo como o que temos abaixo. Não vamos entrar em detalhes agora, mas podemos ver que funciona com uma árvore de chamada com relação pai-filho de quem chamou quem.
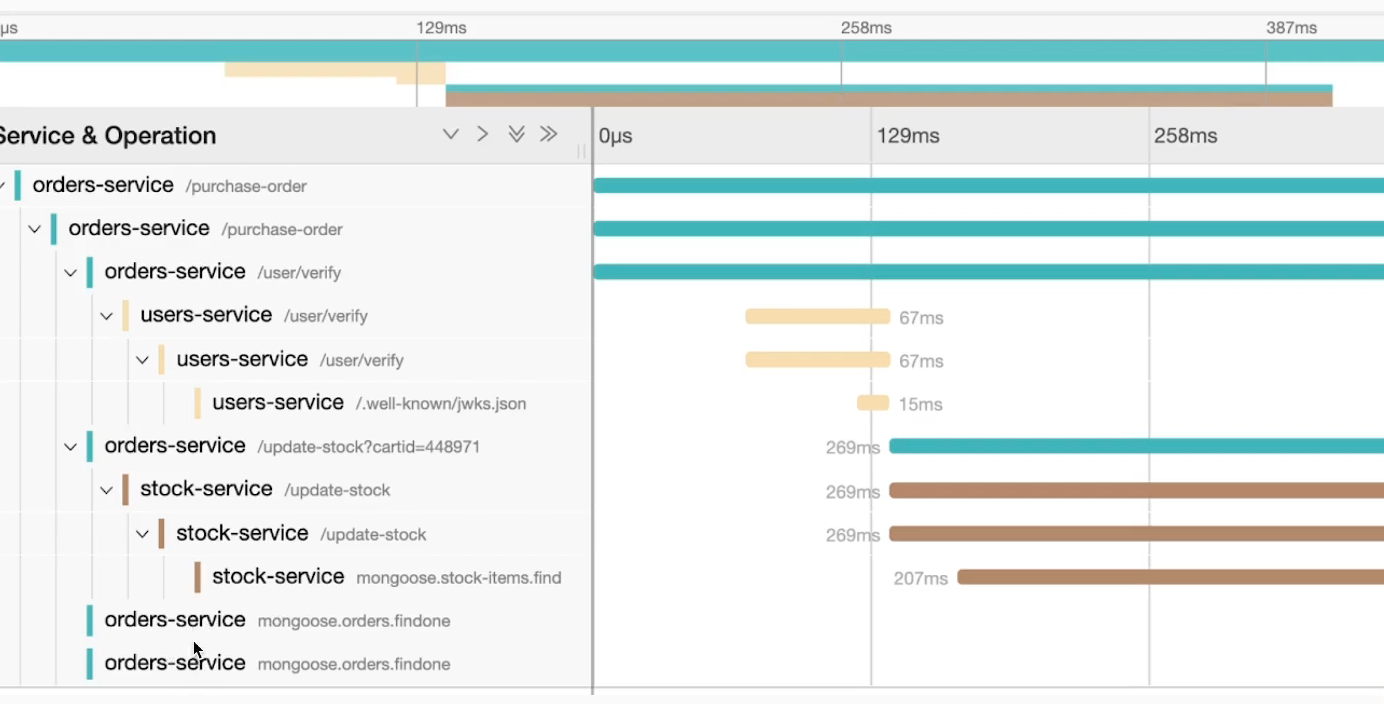
Observe que o trace conta uma história do que aconteceu com uma chamada para /purchase-order de forma visual em árvore. Ao lado temos uma timeline para ajudar a entender o tempo que as coisas foram processadas.
O que estamos vendo aqui é o que chamamos de Context ou seja, contexto de tudo que aconteceu a partir da chamada principal e o tempo que ela levou para completar tudo e o tempo de cada etapa.
Somente depois que a chamada para /user/verify foi completada em 67ms que foi feito a chamada para /update-stock.
Então temos algo como /purchase-order > /user/verify > /update-stock.
Com o trace podemos ver o que foi executado em sequência e o que foi executado em paralelo.