Arquitetura do Prometheus
O Prometheus trabalha ativamente, ele é quem vai até um endpoint exposto pela aplicação para buscar as métricas através de pull. Porém estas métricas têm que estar formatadas corretamente para entrar no TSDB (Time Series Database).
Geralmente em outras ferramentas, a aplicação é que envia os dados através de um push.
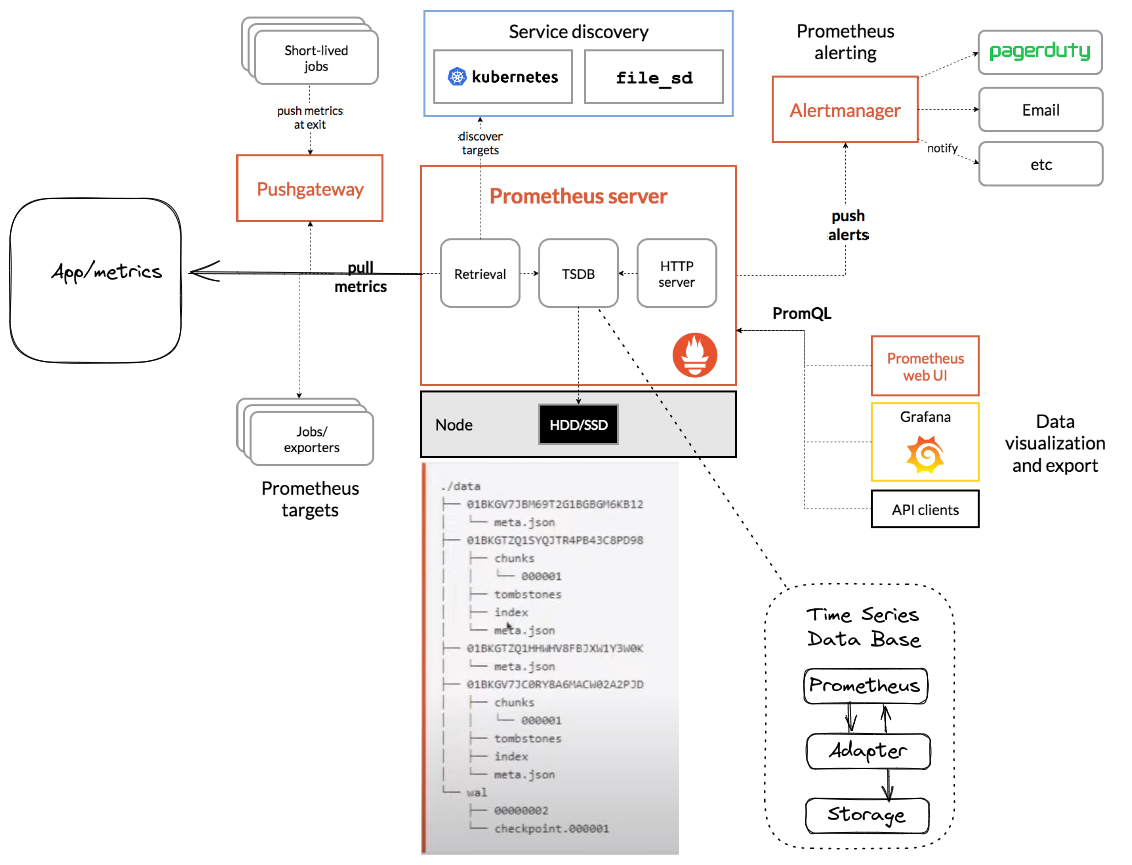
Prometheus Server
Dentro do Prometheus server temos os seguintes elementos:
- TSDB
- Retrieval
- HTTP (PromQL)
TSDB (Time Series Database)
https://prometheus.io/docs/prometheus/latest/storage/
É utilizado para armazenar os dados de métricas.
O Prometheus inclui um banco de dados de série temporal local em disco, mas também se integra opcionalmente com sistemas de armazenamento remoto.
O Prometheus por padrão (pode ser configurado) separa os arquivos em blocos de duas em duas horas e consegue guardar seus valores coletados em diferentes arquivos. Cada bloco de duas horas consiste em um diretório contendo um subdiretório de chunks contendo todas as amostras de séries temporais para aquela janela de tempo, um arquivo de metadados e um arquivo de índice (que indexa nomes de métricas e rótulos para séries temporais no diretório de chunks). As amostras no diretório chunks são agrupadas em um ou mais arquivos de segmento de até 512 MB cada por padrão. Quando as séries são excluídas por meio da API, os registros de exclusão são armazenados em arquivos de exclusão separados (em vez de excluir os dados imediatamente dos segmentos do bloco).
Separar melhora a performance e diminui o consumo de memória, pois não terá um arquivo tão grande ocupando espaço.
O bloco atual para as amostras recebidas é mantido na memória e não é totalmente persistente. Ele é protegido contra travamentos por um log write-ahead (WAL) que pode ser reproduzido quando o servidor Prometheus for reiniciado.
Observe que uma limitação do armazenamento local é que ele não é agrupado ou replicado. O uso de RAID é sugerido para disponibilidade de armazenamento e snapshots são recomendados para backup.
Também é possível utilizar outros bancos de dados ao invés de salvar em arquivo. Para isso é necessário o uso de adaptador de acordo com o banco onde você irá guardar os dados. Porém existe uma perda de desempenho e eficiência.
Com o passar do tempo os blocos de duas horas são compactados em blocos mais longos, geralmente 31 dias. Essa compactação é o que causa uma perda de precisão nos dados coletados.
Por isso o Prometheus não é recomendado para métricas de negócio.
Retrieval
Responsável por ir buscar as métricas no jobs (aplicações). Abaixo um exemplo de como as métricas devem ser formatadas.
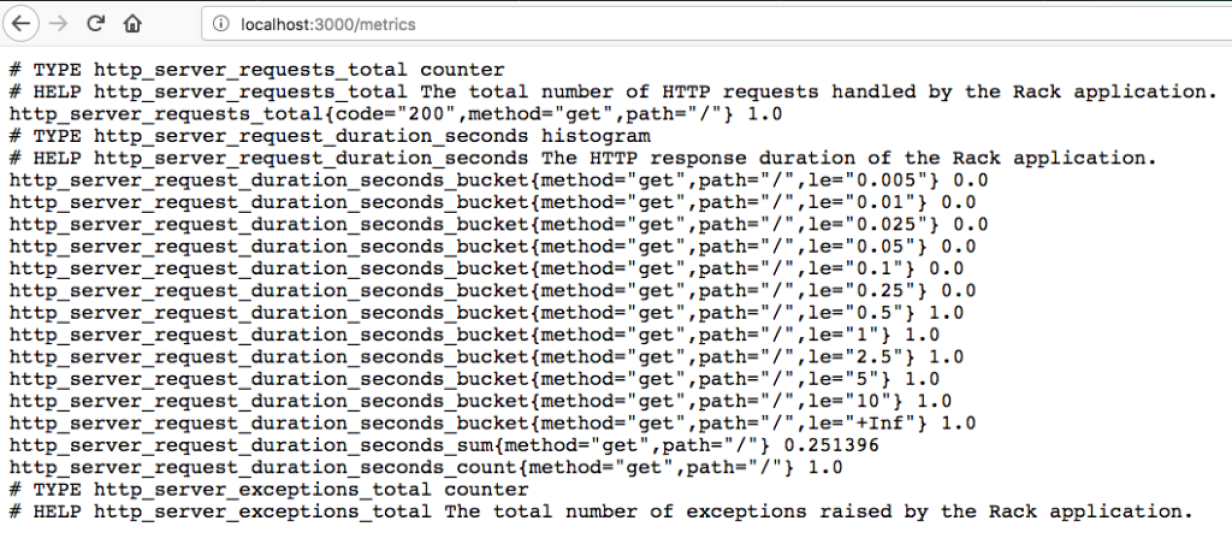
Várias bibliotecas em diferentes linguagens dão suporte a isso. Confira no link https://prometheus.io/docs/instrumenting/clientlibs/.
Além disso existem bibliotecas prontas como o OpenTelemetry que podem ser usadas.
Integração Nativa
Algumas ferramentas de mercado já possuem suporte nativo para o Prometheus expondo endpoints de métricas para que o Prometheus colete as métricas.
- Grafana
- Docker
- Kubernetes
- Traefik
- Gitlab
- Netdata
- RabbitMQ
- Etcd
- ...
Exporters
Quando uma ferramenta não tem suporte ao Prometheus (não expõe suas métricas, ou não utilizam os padrões necessários para o Prometheus) usamos o que chamamos de exporters para esse cenário.
Os exporters são processos que vão coletar as métricas dessas aplicações e expô-las para o Prometheus coletar essas métricas.
Push Gateway
Quando um processo possui uma curta duração (Short-lived jobs) e não dá tempo do Prometheus buscar as métricas, utilizamos um recurso chamado Push Gateway. Nesse caso cabe a esse processo enviar suas métricas para o push gateway e o Prometheus buscará nele funcionando como um cache.
Service Discovery
Para o retrieval conseguir encontrar os endpoints de aplicações que ficam mudando IP e escalando dinamicamente, o Prometheus dispõe da funcionalidade de service discovery e dá suporte a vários serviços como Kubernetes, Consul, etc. Isso é muito bom para o cenário de microserviços.
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
HTTP server
Esta é a parte que faz a interação do Prometheus com o usuário.
- WEB UI
- API
- Grafana ou algum outro dashboard
AlertManager
Não é responsabilidade do Prometheus entregar o alerta para o usuário quando este acontecer. Para isso ele utiliza um outro sistema chamado AlertManager.
Observe que o AlertManager é um app à parte do Prometheus no qual o Prometheus envia para ele um alerta e cabe a ele enviá-lo para o usuário seja através do Slack, Telegram, e-mail ou algum outro push notification.
O Prometheus pode ser altamente disponível?
Sim, execute servidores Prometheus idênticos em duas ou mais máquinas separadas. Alertas idênticos serão desduplicados pelo AlertManager.
Para alta disponibilidade do AlertManager você pode executar várias instâncias em um cluster Mesh e configurar os servidores Prometheus para enviar notificações para cada um deles.