Múltiples Schedulers
Podemos tener diferentes Schedulers en el cluster. Lo que necesitamos hacer es pasar cuál Scheduler queremos usar en el Pod. Ese Scheduler será el responsable por leer la configuración del Pod y elegir el Nodo correcto.
Es necesario que los Schedulers tengan diferentes nombres.
Vamos a tomar un Pod cualquiera que tenemos en nuestro cluster.
k get pods busybox -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2024-03-18T03:06:56Z"
labels:
run: busybox
name: busybox
namespace: default
resourceVersion: "2879304"
uid: b055b81d-96d4-4fe7-8666-635a9d03f4bf
spec:
containers:
- command:
- sleep
- "1000"
image: busybox
imagePullPolicy: Always
name: busybox
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-xxwlk
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: cka-cluster-worker3
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler #<<<
...
Podemos observar que aunque no se definió un Scheduler, tenemos el default-scheduler. Podríamos pasar otro Scheduler en el spec.
La manera más simple de crear un Scheduler es implantando otro.
El cluster kind crea el Scheduler como Pod en vez de service, ¿qué podemos hacer? Crear otro, pero pasando las configuraciones específicas.
Vamos a analizar la configuración del kube-scheduler. Este es el Scheduler que el propio kind creó con el kubeadm.
kubectl get pods -n kube-system kube-scheduler-cka-cluster-control-plane -o=jsonpath='{.spec.containers[*].command}' | jq
[
"kube-scheduler",
"--authentication-kubeconfig=/etc/kubernetes/scheduler.conf",
"--authorization-kubeconfig=/etc/kubernetes/scheduler.conf",
"--bind-address=127.0.0.1",
"--kubeconfig=/etc/kubernetes/scheduler.conf",
"--leader-elect=true"
]
Podemos colocar otro Scheduler y pasar el --config con el archivo de configuración que vamos a crear.
Si vamos a crear ese Scheduler en todos los masters necesitamos definir el --leader-elect=true. Podríamos crear el Scheduler utilizando Static Pods yendo dentro del master y colocando el manifiesto en /etc/kubernetes/manifest.
En la documentación tenemos un modelo usando el propio Scheduler oficial.
En este conjunto de manifiestos tenemos.
- Service account
- 2 ClusterRoleBinding que darán el permiso para el ServiceAccount en el mismo grupo del kube-scheduler
system:kube-schedulery ensystem:volume-scheduler - 1 RoleBinding que dará permiso para el ServiceAccount en
extension-apiserver-authentication-reader - El ConfigMap que será montado como volumen a fin de proveer un archivo de configuración. Con esto podemos colocar todos los parámetros dentro de él y disminuir la cantidad de entradas arriba.
Cree un archivo con el contenido abajo y aplique en el cluster.
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-kube-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-volume-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:volume-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: my-scheduler-extension-apiserver-authentication-reader
namespace: kube-system
roleRef:
kind: Role
name: extension-apiserver-authentication-reader
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
---
## Aquí podemos definir un ConfigMap que será montado como volumen a fin de entregarnos este archivo
apiVersion: v1
kind: ConfigMap
metadata:
name: my-scheduler-config
namespace: kube-system
data:
my-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: true # Era false, alterado para true para probar con 3 réplicas
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 3 # Era 1, alterado para 3
template:
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: registry.k8s.io/kube-scheduler:v1.29.1 # Alterada pues no tenemos la imagen anterior
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-config
kubectl apply -f my-scheduler.yaml
serviceaccount/my-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-kube-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-volume-scheduler created
rolebinding.rbac.authorization.k8s.io/my-scheduler-extension-apiserver-authentication-reader created
configmap/my-scheduler-config created
deployment.apps/my-scheduler created
k get pods -n kube-system | grep my-scheduler
my-scheduler-8ffc64976-449zr 1/1 Running 0 92s
my-scheduler-8ffc64976-6hn6t 1/1 Running 0 92s
my-scheduler-8ffc64976-nj8xp 1/1 Running 0 92s
Algunas cosas que podemos analizar.
- El master posee Taints y no definimos ninguna Toleration para que pueda ir al master. No irá.
- No definimos ningún nodeAffinity o podAntiAffinity para que pueda distribuir las 3 réplicas en diferentes Nodos. Si ocurre es mera coincidencia.
- ¡El Scheduler por defecto que programó esos Pods!
Ahora vamos a usar ese Scheduler para crear un Pod
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
schedulerName: my-scheduler
EOF
k describe pod nginx | grep scheduler
Normal Scheduled 56s my-scheduler Successfully assigned default/nginx to cka-cluster-worker3
Scheduler Profiles
Un Scheduler posee una cola para programar los Pods. Si todos tienen la misma prioridad entonces van entrando al final de la cola y siguiendo el flujo. Quien llega primero es el primero en ser programado.
Es posible configurar prioridades diferentes y vincular un Pod a esta prioridad. De esa forma es posible que Pods de alta prioridad se salten la cola. Esto es bastante útil si un servicio realmente no puede esperar.
Para definir una prioridad podemos crear como definido abajo. Este no es un recurso a nivel de namespace, sino a nivel del cluster. Un Scheduler mira para todos los Pods independiente del namespace.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false # Si será el por defecto o no
description: "This priority class should be used for XYZ service pods only."
Ya existen dos definidos en el cluster.
k get priorityclasses.scheduling.k8s.io -o wide
NAME VALUE GLOBAL-DEFAULT AGE
system-cluster-critical 2000000000 false 18d
system-node-critical 2000001000 false 18d
Cuando llegue el turno del Pod de ser programado va para la etapa de filtrado. Los Nodos que no pueden recibir el Pod, sea por falta de recurso o por elección del usuario usando nodeSelector, affinities, Taints y Tolerations serán eliminados y solamente aquellos que pasaron por el filtrado podrán programar el Pod.
Por último tenemos la etapa de score. Esta etapa seleccionará cuál de los Nodos que sobraron es el mejor para levantar el Pod. ¿Cómo esa puntuación es definida? Si un Pod necesita de 2 CPUs y tenemos dos Nodos posibles siendo el primero con 2 CPUs disponibles y el segundo con 6 obviamente el que tiene 6 ya posee un score mayor. En ese caso ambos tendrían memoria suficiente para ejecutar el Pod sino ni habrían pasado por la etapa de filtrado.
Por último tenemos el proceso de binding que es cuando de hecho el Nodo es definido y el kubelet de aquel Nodo será responsable por levantar el Pod.
Las etapas son:
- Scheduling Queue
- Filtering
- Scoring
- Binding
Todas esas operaciones son realizadas con ciertos plugins.
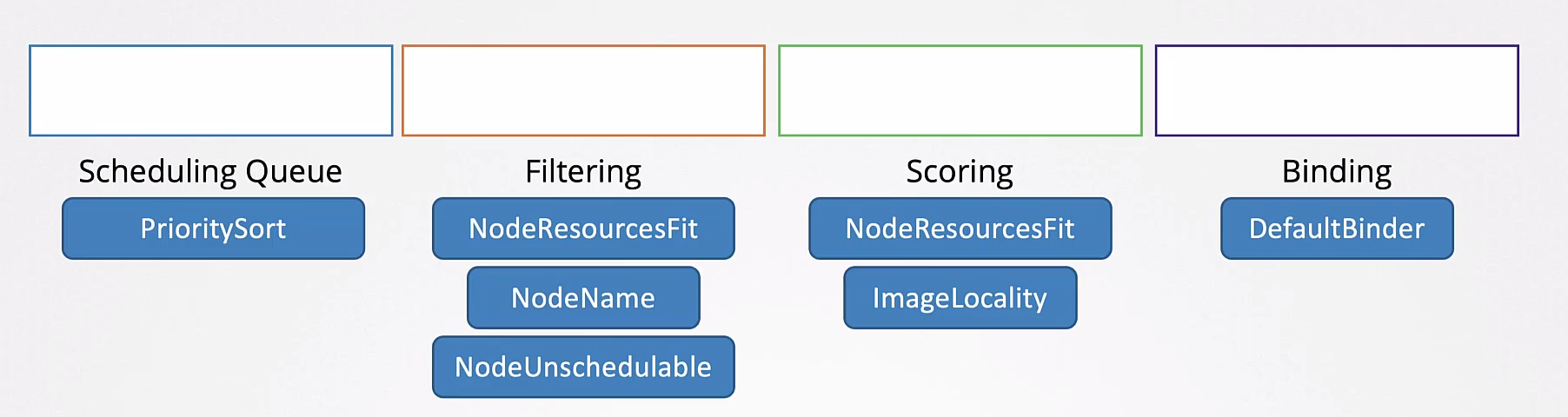
Un plugin puede estar asociado en más de una etapa.
Una curiosidad es que en la etapa de score, tenemos un plugin llamado ImageLocality. Un Nodo que ya posee la imagen disponible puede tener un score mayor.
Esas etapas pueden ser todavía subdivididas utilizando diferentes plugins que analizan de forma diferente.
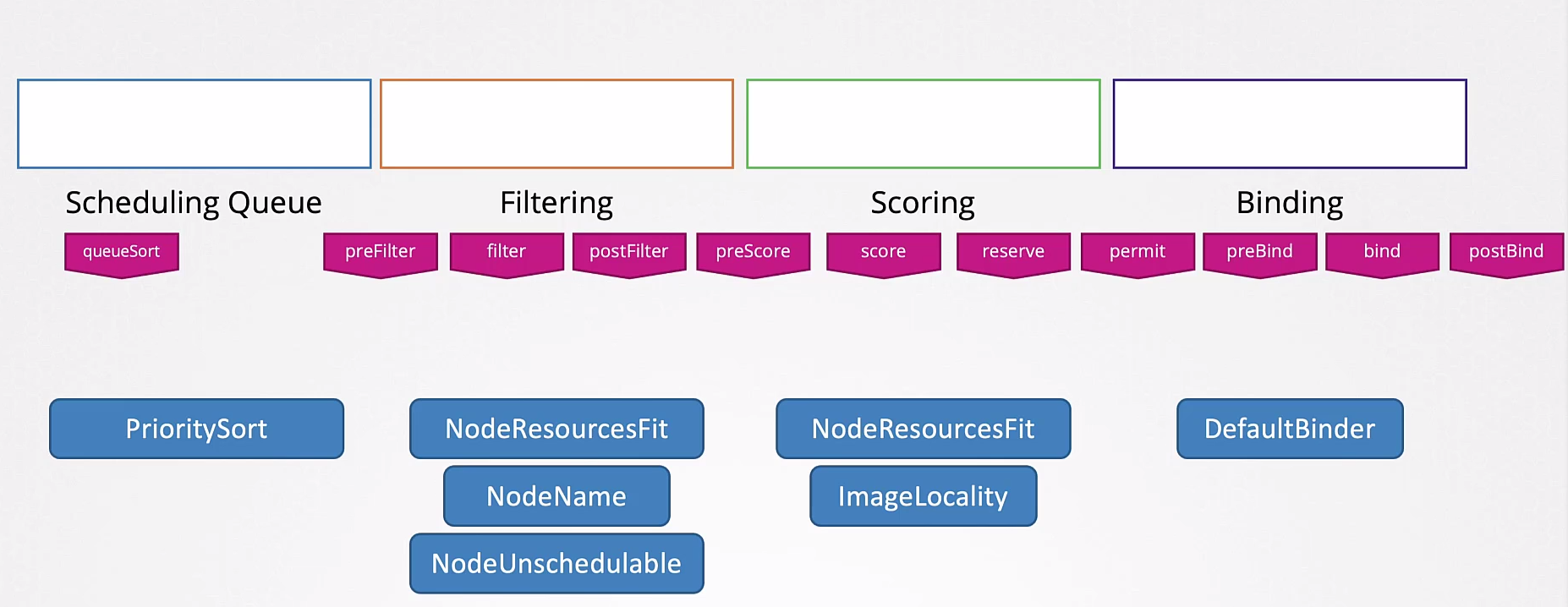
Puedes escribir tus propios métodos de Scheduler.
Una situación que puede ocurrir al tener varios Schedulers diferentes es que cada uno puede tener reglas completamente diferentes, leyendo e interpretando los Nodos de forma diferente creando una condición de carrera.
Para evitar esto es interesante tener un Scheduler con varios profiles. De esa forma el mismo binario estaría siendo usado para todo el mundo.
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
plugins:
score:
disabled:
- name: TaintToleration
enabled:
- name: MyCustomPluginA
- name: MyCustomPluginB
- schedulerName: my-scheduler2
plugins:
preScore:
disabled:
- name: '*'
- schedulerName: my-scheduler3
leaderElection:
leaderElect: true # Era false, alterado para true para probar con 3 réplicas