Volúmenes
Sabemos que la función del contenedor es procesar datos y morir, y lo que lo mantiene vivo es el proceso con ID 1. Si ese proceso muere, el contenedor se detiene. Solo se destruyen los datos cuando el contenedor es destruido.

En el mundo de los contenedores, para persistir los datos usamos los volúmenes.

Los contenedores dentro de un pod se ejecutan en sus respectivas capas read-write como mencionamos anteriormente. El pod controla los contenedores dentro de él y cuando un pod finaliza, destruye sus respectivos contenedores llevándose los datos.

Para persistir los datos también es necesario el uso de volúmenes.

Si creamos un pod normalmente, los datos se pierden cuando el pod muere.
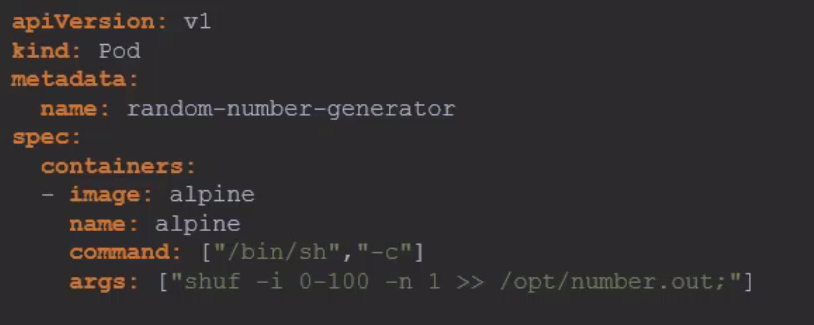
Para crear un volumen usando un driver Local necesitamos declarar un volumen. Sería el mismo proceso cuando un contenedor crea el volumen automáticamente. En el escenario siguiente creamos un volumen dentro del host, pero el volumen aún no está siendo usado.
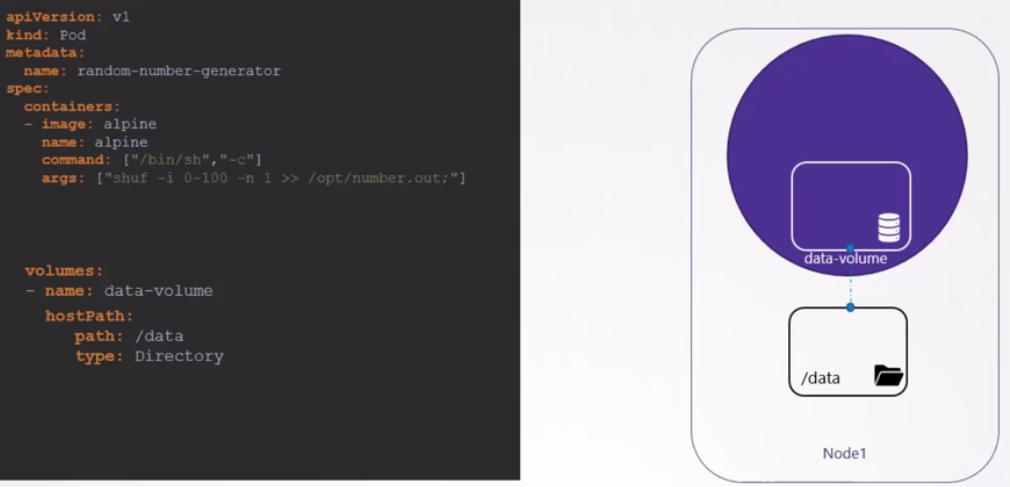
Es necesario mapear que el /opt del contenedor corresponda al volumen en /data.
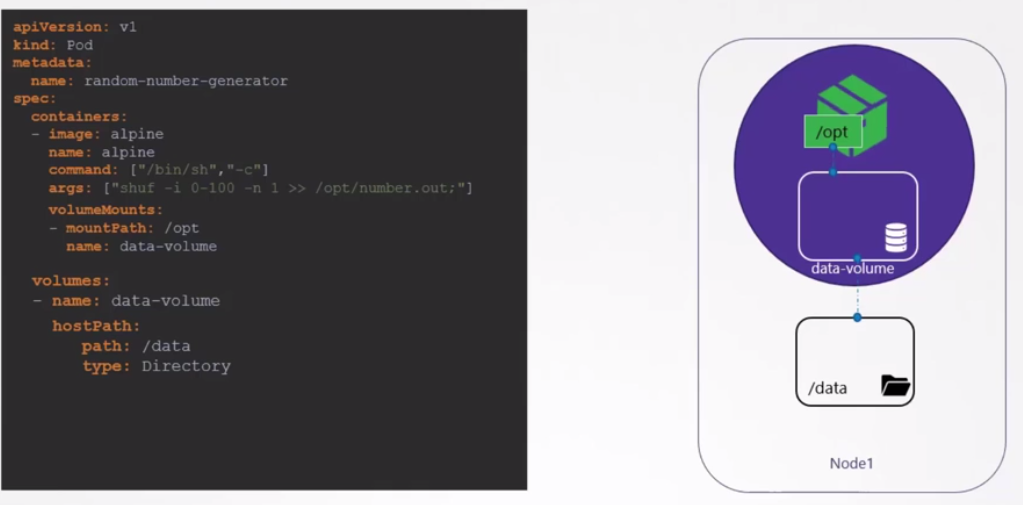
Si ese pod es destruido y creado nuevamente y se levanta en un nodo diferente, ¿los datos estarán ahí? No.
Dos puntos que debemos tener en cuenta aquí:
-
Este volumen está pasando una ruta en el nodo, por lo que este directorio necesita existir previamente con el permiso adecuado.
-
Esto funcionaría para un cluster con un único nodo.
-
En un cluster con múltiples nodos, el pod puede levantarse en cualquier nodo que pase por el filtrado del scheduler. Los datos no estarían disponibles si se levantara en un nodo diferente del que se levantó antes.
Tener réplicas para el mismo pod requiere que todos los pods vean el mismo directorio para que los datos tengan sentido.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: "ramdon-number-generator"
spec:
containers:
- name: alpine
image: "alpine"
command: ["/bin/sh", "-c"]
args: ["shuf -i 0-100 -n 1 >> /opt/number.out;"]
volumeMounts:
- name: data-volume
mountPath: /opt
volumes:
- name: data-volume
hostPath:
path: /data
type: Directory
EOF
# Observe que el pod no está ready
kubectl get pods
NAME READY STATUS RESTARTS AGE
ramdon-number-generator 0/1 ContainerCreating 0 22s
kubectl describe pod ramdon-number-generator
## Removido para facilitar la lectura
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 28s default-scheduler Successfully assigned default/ramdon-number-generator to kind-cluster-worker2
# No pudo montar como esperado
Warning FailedMount 13s (x6 over 29s) kubelet MountVolume.SetUp failed for volume "data-volume" : hostPath type check failed: /data is not a directory
Si cambiaras por /tmp funcionaría.
Pero esta es una solución específica para algunos y no para la gran mayoría. Lo ideal no es guardar los datos de las aplicaciones dentro de los nodos, sino tener una solución externa para ese propósito.
Kubernetes soporta diferentes tipos de soluciones de almacenamiento:
- NFS
- GlusterFS
- Flocker
- Ceph
- Scaleio
- vSphere
- Otras
Y también muchas soluciones de nube como:
- AWS
- Azure
- GCP
- otros
Por ejemplo, en AWS podríamos usar EBS.
volumes:
- name: data-volume
awsElasticBlockStore:
volumeID: <volume-id>
fsType: ext4
Vamos a crear un contenedor de nginx y un volumen compartido entre él y otro. El segundo contenedor deberá poner la hora en el index.html del nginx.
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: pod-com-dois-containers
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html
- name: hora-container
image: alpine
command: ["/bin/sh", "-c"]
args:
- while true; do echo "$(date '+%Y-%m-%d %H:%M:%S')" > /mnt/html/index.html; sleep 1; done
volumeMounts:
- name: html-volume
mountPath: /mnt/html
volumes:
- name: html-volume
emptyDir: {}
EOF