¿Qué es Docker?
2.1. ¿Dónde entra Docker en esta historia?
Todo comenzó en 2008, cuando Solomon Hykes fundó dotCloud, una empresa especializada en PaaS con una gran diferencia: su Platform-as-a-Service no estaba vinculado a ningún lenguaje de programación específico, como era el caso, por ejemplo, de Heroku, que solo soportaba aplicaciones desarrolladas en Ruby.
El gran punto de inflexión en la historia de dotCloud ocurrió en marzo de 2013, cuando decidieron hacer open source el core de su plataforma -- ¡así nacía Docker!
Las primeras versiones de Docker no eran más que un wrapper de LXC integrado con Union Filesystem, pero su crecimiento fue fantástico y muy rápido, tanto que en seis meses su GitHub ya tenía más de seis mil stars y más de 170 personas contribuyendo al proyecto alrededor del mundo.
Con esto, dotCloud pasó a llamarse Docker y la versión 1.0 fue lanzada apenas 15 meses después de su versión 0.1. La versión 1.0 de Docker trajo mucha más estabilidad y fue considerada "production ready", además de traer Docker Hub, un repositorio público para containers.
Al ser un proyecto open source, cualquier persona puede visualizar el código y contribuir con mejoras para Docker. Esto trae mayor transparencia y hace que las correcciones de bugs y mejoras ocurran mucho más rápido de lo que sería en un software propietario con un equipo mucho menor y pocos escenarios de pruebas.
Cuando Docker 1.0 fue lanzado y anunciado que estaba listo para producción, empresas como Spotify ya lo utilizaban a gran escala; luego AWS y Google comenzaron a ofrecer soporte a Docker en sus nubes. Otro gigante en moverse fue Red Hat, que se convirtió en uno de los principales socios de Docker, incluso incorporándolo a OpenShift.
Actualmente, Docker es oficialmente soportado solo en máquinas Linux 64 bits. Esto significa que sus containers también tendrán que ser un Linux 64 bits, pues recuerde que el container utiliza el mismo kernel de la máquina host. ;)
Hoy Docker puede ser ejecutado tranquilamente en otras plataformas como Windows y MacOS, pero aún no con el mismo rendimiento y estabilidad de Docker siendo ejecutado en Linux. ¡Ahhh, Linux!
2.2. ¿Y ese asunto de las capas?
2.2.1. Copy-On-Write (COW) y Docker
Antes de entender las capas propiamente dichas, necesitamos entender cómo uno de los principales requisitos para que esto suceda, el Copy-On-Write (o COW para los íntimos), funciona. En palabras del propio Jérome Petazzoni:
It's a little bit like having a book. You can make notes in that book if you want, but each time you approach the pen to the page, suddenly someone shows up and takes the page and makes a xerox copy and hand it back to you, that's exactly how copy on write works.
En traducción libre, sería como si tuvieras un libro y que fuera permitido hacer anotaciones en él si quisieras, pero, cada vez que estuvieras a punto de tocar la página con el bolígrafo, de repente alguien apareciera, sacara una fotocopia de esa página y te entregara la copia. Es exactamente así como funciona el Copy-On-Write.
Básicamente, significa que un nuevo recurso, sea un bloque en el disco o un área en memoria, solo es asignado cuando es modificado.
Bien, pero ¿qué tiene que ver todo esto con Docker? Bueno, como sabes, Docker usa un esquema de capas, o layers, y para montar esas capas se usan técnicas de Copy-On-Write. Un container es básicamente una pila de capas compuestas por N capas read-only y una, la superior, read-write.
2.3. Storage drivers
A pesar de que un container posee una capa de escritura, la mayor parte del tiempo no quieres escribir datos directamente en él, por varios motivos, entre ellos su naturaleza volátil. En situaciones donde tu aplicación genera datos, preferirás usar volúmenes "adjuntados" al container y escribir en ellos (veremos más adelante cómo hacer esto). Sin embargo, en algunas situaciones es, sí, necesaria la escritura local en el container, y es ahí donde el storage driver entra en la historia. Storage driver es el mecanismo utilizado por el engine de Docker para dictar la forma en que esos datos serán manipulados en el filesystem del container. A continuación, los principales storage drivers y sus peculiaridades.
2.3.1. AUFS (Another Union File System)
El primer filesystem disponible para Docker fue AUFS, uno de los más antiguos Copy-On-Write filesystems, e inicialmente tuvo que pasar por algunas modificaciones a fin de mejorar la estabilidad.
AUFS funciona a nivel de archivos (no en bloque), y la idea es tener múltiples directorios (capas) que él presenta para el SO como un punto único de montaje.
Cuando intentas leer un archivo, la búsqueda se inicia por la capa superior, hasta encontrar el archivo o concluir que no existe. Para escribir en un archivo, este necesita primero ser copiado a la capa superior (writable) -- y, sí, adivinaste: escribir en archivos grandes puede causar cierta degradación del rendimiento, ya que el archivo necesitaría ser copiado completamente a la primera capa, incluso cuando una parte muy pequeña va a sufrir alteración.
Ya que estamos hablando de cosas molestas, otra cosa que puede degradar tu rendimiento usando AUFS es el hecho de que busca cada directorio de un path en cada capa del filesystem cada vez que intentas ejecutar un comando. Por ejemplo, si tienes un path con cinco capas, se realizarán 25 búsquedas (stat(), una system call). Esto puede ser muy complicado en aplicaciones que hacen load dinámico, como las apps Python que importan los .py de la vida.
Otra particularidad es cuando algún archivo es eliminado. Cuando esto ocurre se crea un whiteout para ese archivo. En otras palabras, es renombrado a ".wh.archivo" y queda indisponible para el container, ya que, bueno, no se puede borrar de verdad, pues las otras capas son read-only.
2.3.2. Device Mapper
Device Mapper es un kernel-based framework de Red Hat usado para algunas abstracciones, como, por ejemplo, el mapeo de "bloques físicos" a "bloques lógicos", permitiendo técnicas como LVM y RAID. En el contexto de Docker, sin embargo, se resume al "thin provisioning target" o al storage driver "devicemapper". Tan pronto como esto de Docker comenzó a andar, la gente de Red Hat (y toda la gente que usaba alguna distro relacionada con Red Hat) se interesó bastante, solo que había un problema: no querían usar AUFS. Para resolver esto, reunieron un equipo de ingenieros muy habilidosos que agregaron soporte a Device Mapper en Docker.
Tratándose de Docker, Device Mapper y AUFS son bastante similares: la gran diferencia entre ellos es que, en Device Mapper, cuando necesitas escribir en el archivo, la copia se hace a nivel de bloques, que era un problema allá en AUFS, y con esto ganas una granularidad mucho mayor. En teoría, el problema que tenías cuando escribías un archivo grande desaparece. Por defecto, Device Mapper escribe en archivos de loopback, lo que deja las cosas más lentas, pero ahora en la versión 1.17+ ya puedes configurarlo en modo direct-lvm, que escribe en bloques y, en teoría, resolvería este problema. Es un poco más molesto de configurar, pero es una solución más elegante para ambientes en producción.
Además de AUFS y Device Mapper, también puedes usar BTRFS y OverlayFS como storage driver. Por ser tecnologías relativamente jóvenes, aprecia con moderación.
2.3.3. OverlayFS y OverlayFS2
La opción del momento. Una versión mejorada de AUFS, OverlayFS y su versión siguiente y oficialmente recomendada por Docker, Overlay2, son ambos other union filesystems, pero esta vez mucho más eficientes, rápidos y con una implementación mucho más simple.
Por ser union file systems, también comparten la idea de juntar varios directorios en un único punto de montaje como nuestro amigo AUFS, sin embargo, en el caso de OverlayFS, solo dos directorios son soportados, lo que no ocurre en Overlay2, que tiene soporte multi-layer. Ambos soportan page caching sharing, es decir, múltiples containers accediendo al mismo archivo comparten la misma entrada en el archivo de paginación, lo que es un uso más eficiente de memoria.
Aquel problema antiguo de AUFS de tener que copiar todo el archivo a la capa de arriba para escribir en él todavía persiste, pero en OverlayFS solo se copia una vez y queda ahí para que las otras escrituras en el mismo archivo puedan ocurrir más rápido, entonces tiene una pequeña ventaja.
Se nota un consumo excesivo de inodes cuando se usa OverlayFS. Este es un problema resuelto en Overlay2, así que siempre que sea posible busca usarlo -- hasta porque, en general, tiene un rendimiento superior. Recordando que kernel 4.0+ es prerrequisito para usar OverlayFS2.
2.3.4. BTRFS
BTRFS es la siguiente generación de union filesystem. Es mucho más space-efficient, soporta muchas tecnologías avanzadas de storage y ya está incluido en el mainline del kernel. BTRFS, a diferencia de AUFS, realiza operaciones a nivel de bloque y usa un esquema de thin provision parecido al de Device Mapper y soporta copy-on-write snapshots. Puedes incluso combinar varios devices físicos en un único BTRFS filesystem, algo así como un LVM.
BTRFS es soportado actualmente en la versión CE solo en distribuciones debian-like y en la versión EE solo en SLES (Suse Linux Enterprise Server).
IMPORTANTE: alterar el storage drive hará que cualquier container ya creado se vuelva inaccesible al sistema local. ¡Cuidado!
2.4. Docker Internals
Docker utiliza algunas features básicas del kernel Linux para su funcionamiento. A continuación tenemos un diagrama en el cual es posible visualizar los módulos y features del kernel que Docker utiliza:
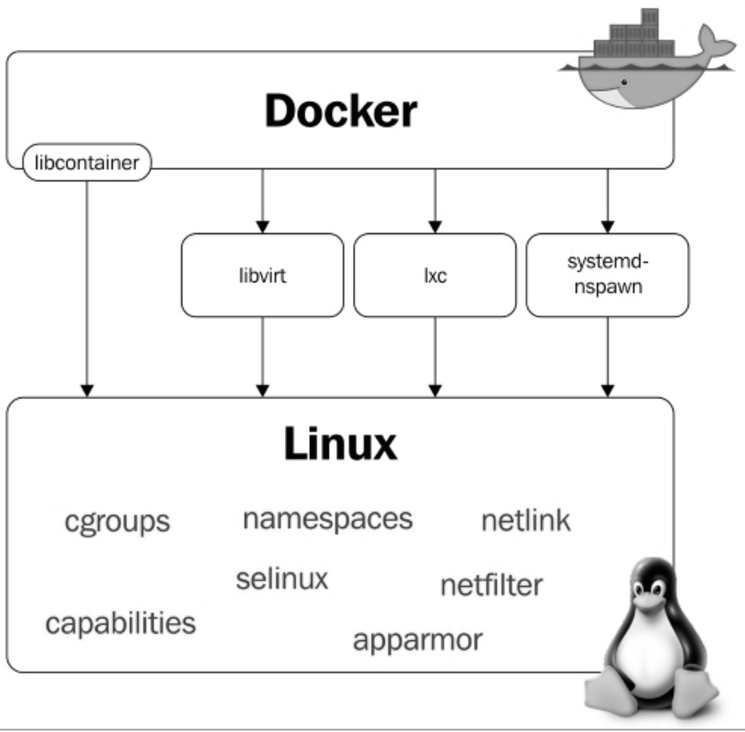
2.5. Namespaces
Los Namespaces fueron agregados en el kernel Linux en la versión 2.6.24 y son ellos los que permiten el aislamiento de procesos cuando estamos utilizando Docker. Son los responsables de hacer que cada container posea su propio environment, es decir, cada container tendrá su árbol de procesos, puntos de montaje, etc., haciendo que un container no interfiera en la ejecución de otro. Vamos a saber un poco más sobre algunos namespaces utilizados por Docker.
2.5.1. PID namespace
El PID namespace permite que cada container tenga sus propios identificadores de procesos. Esto hace que el container posea un PID para un proceso en ejecución -- y cuando busques ese proceso en la máquina host lo encontrarás; sin embargo, con otra identificación, es decir, con otro PID.
A continuación tenemos el proceso "testando.sh" siendo ejecutado en el container.
Nota el PID de este proceso en el árbol de procesos:
root@c774fa1d6083:/# bash testando.sh &
[1] 7
root@c774fa1d6083:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 18:06 ? 00:00:00 /bin/bash
root 7 1 0 18:07 ? 00:00:00 bash testando.sh
root 8 7 0 18:07 ? 00:00:00 sleep 60
root 9 1 0 18:07 ? 00:00:00 ps -ef
root@c774fa1d6083:/#
Ahora, nota el PID del mismo proceso mostrado a través del host:
root@linuxtips:~# ps -ef | grep testando.sh
root 2958 2593 0 18:12 pts/2 00:00:00 bash testando.sh
root 2969 2533 0 18:12 pts/0 00:00:00 grep --color=auto testando.sh
root@linuxtips:~#
¿Diferentes, verdad? Sin embargo, son el mismo proceso. :)
2.5.2. Net namespace
El Net Namespace permite que cada container posea su interfaz de red y puertos. Para que sea posible la comunicación entre los containers, es necesario crear dos Net Namespaces diferentes, uno responsable de la interfaz del container (normalmente utilizamos el mismo nombre de las interfaces convencionales de Linux, por ejemplo, eth0) y otro responsable de una interfaz del host, normalmente llamada veth* (veth + un identificador aleatorio). Estas dos interfaces están linkeadas a través del bridge Docker0 en el host, que permite la comunicación entre los containers a través del enrutamiento de paquetes.
Como mencionamos, vea las interfaces. Interfaces del host:
root@linuxtips:~# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:1c:42:c7:bd:d8 brd ff:ff:ff:ff:ff:ff
inet 10.211.55.35/24 brd 10.211.55.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fdb2:2c26:f4e4:0:21c:42ff:fec7:bdd8/64 scope global dynamic
valid_lft 2591419sec preferred_lft 604219sec
inet6 fe80::21c:42ff:fec7:bdd8/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:c7:c1:37:14 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:c7ff:fec1:3714/64 scope link
valid_lft forever preferred_lft forever
5: vetha2e1681: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 52:99:bc:ab:62:5e brd ff:ff:ff:ff:ff:ff
inet6 fe80::5099:bcff:feab:625e/64 scope link
valid_lft forever preferred_lft forever
root@linuxtips:~#
Interfaces del container:
root@6ec75484a5df:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
6: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:3/64 scope link
valid_lft forever preferred_lft forever
root@6ec75484a5df:/#
¿Lograste visualizar las interfaces Docker0 y veth* del host? ¿Y la eth0 del container? ¿Sí? ¡Excelente! :D
2.5.3. Mnt namespace
Es evolución del chroot. Con el Mnt Namespace cada container puede ser dueño de su punto de montaje, así como de su sistema de archivos raíz. Garantiza que un proceso ejecutándose en un sistema de archivos no pueda acceder a otro sistema de archivos montado por otro Mnt Namespace.
2.5.4. IPC namespace
Provee un SystemV IPC aislado, además de una cola de mensajes POSIX propia.
2.5.5. UTS namespace
Responsable de proveer el aislamiento de hostname, nombre de dominio, versión del SO, etc.
2.5.6. User namespace
El namespace más reciente agregado en el kernel Linux, disponible desde la versión 3.8. Es el responsable de mantener el mapa de identificación de usuarios en cada container.
2.6. Cgroups
Es el cgroups el responsable de permitir la limitación de la utilización de recursos del host por los containers. Con cgroups puedes gestionar la utilización de CPU, memoria, dispositivos, I/O, etc.
2.7. Netfilter
La ya conocida herramienta iptables forma parte de un módulo llamado netfilter. Para que los containers logren comunicarse, Docker construye diversas reglas de enrutamiento a través de iptables; inclusive utiliza NAT, que veremos más adelante en el libro.
root@linuxtips:~# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 anywhere
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere
root@linuxtips:~#
2.8. ¿Para quién es bueno?
Docker es muy bueno para los desarrolladores, pues con él tienes libertad para elegir tu lenguaje de programación, tu base de datos y tu distribución preferida. Ya para los sysadmins es mejor aún, pues, además de la libertad de elegir la distribución, no necesitamos preparar el servidor con todas las dependencias de la aplicación. Tampoco necesitamos preocuparnos si la máquina es física o virtual, pues Docker soporta ambas.
La empresa como un todo gana, con la utilización de Docker, mayor agilidad en el proceso de desarrollo de aplicaciones, acortando el proceso de transición entre los ambientes de QA, STAGING y PROD, pues se utiliza la misma imagen. Trae menos costos con hardware debido al mejor gerenciamiento y aprovechamiento de los recursos, además del overhead, que es mucho menor si se compara con otras soluciones, como la virtualización.
Con Docker se vuelve mucho más viable la creación de microservices (microservicios, la idea de que una gran aplicación sea dividida en varias pequeñas partes y estas ejecuten tareas específicas), un tema que ha ganado cada vez más espacio en el mundo de la tecnología y que vamos a abordar con más detalles al final de este libro.
Todavía tenemos diversos otros motivos para utilizar containers y que vamos descubriendo conforme evolucionamos con la utilización de Docker. :D