Baremetal AWS Terraform
La idea del proyecto es con un clic provisionar todo el clúster kubernetes.
Requisitos
Terraform
Es necesario el binario de Terraform. La instalación no es más que mover el binario al path de tu sistema donde tengas permiso, o agrega el repositorio y realiza la instalación.
wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor | sudo tee /usr/share/keyrings/hashicorp-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list
sudo apt update && sudo apt install terraform
Cuenta en AWS
El proyecto de Terraform creará recursos de AWS en tu nombre, necesita tener acceso al ID de la clave de acceso y a la clave de acceso secreta de un usuario de IAM en tu cuenta de AWS. Necesitas esta variable de entorno cargada en tu sistema cuando vayas a ejecutar los comandos de terraform.
export AWS_ACCESS_KEY_ID=<AccessKeyID>
export AWS_SECRET_ACCESS_KEY=<SecretAccessKey>
En la Consola de AWS IAM, también puedes generar un nuevo ID de clave de acceso y una clave de acceso secreta para cualquier usuario de IAM si no puedes recuperar el existente. Es necesario que este usuario tenga las siguientes políticas aplicadas en caso de no ser el administrador de la cuenta:
AmazonEC2FullAccess, AmazonVPCFullAccess.
Claves de Acceso SSH
Para acceder a los nodos del clúster después de creado, es necesario instalar un par de claves openssh dentro de cada una de las máquinas.
~/.ssh/id_rsa (clave privada)
~/.ssh/id_rsa.pub (clave pública)
Si no las tienes, puedes generarlas
ssh-keygen
Arquitectura del proyecto
¿Podría hacerse un proyecto único que con un único clic provisionara toda la infra y el clúster? Sí
Pero, como me gustaría entregar un código de gente grande, preferí separar los proyectos de acuerdo con lo que cada uno hace. Si estás empezando desde cero podrás aprovechar estos módulos de hecho para uso en producción.
Un detalle importante para los conocedores es que si utilizo profiles en el código para cargar las claves tal vez algunos no puedan utilizarlo, entonces vamos a utilizar las access key y secrets mismos entregados por AWS.
Carga las variables de entorno y vamos a comenzar...
export AWS_ACCESS_KEY_ID=<AccessKeyID>
export AWS_SECRET_ACCESS_KEY=<SecretAccessKey>
State Backend
El primer proyecto es crear un backend para que terraform guarde los archivos de estado generados para cada uno de los demás proyectos. Este es el único proyecto que el state de hecho quedará dentro de la carpeta del proyecto. Crea un bucket s3 y una dynamodb para dar lock al proyecto si más de una persona está modificando la infra.
Si ya tienes un state backend en tu nube salta este proyecto y sustituye tu backend en los demás proyectos, si no tienes aprovecha el código y sigue adelante.
Si quieres guardar el tfstate localmente puedes, pero no es buena idea.
Entra en la carpeta del proyecto por terminal y ejecuta.
terraform init
terraform apply
Listo, ve a tu cuenta y verifica si el bucket fue creado. Observa también que fue creado un .tfstate y este debe ser mantenido.
Atención: comenta las líneas abajo de tu .gitignore de este proyecto si no vas a perder el archivo si lo usas en tu repositorio, en este caso como estoy subiendo públicamente no lo mantuve en el repositorio.
#*.tfstate
#*.tfstate.*
Network
El módulo de kubernetes necesita una infra provisionada para saber dónde va a subir el clúster en qué subnets, etc. El proyecto network hace exactamente eso. Este proyecto llama un módulo mantenido por la comunidad muy bueno, entonces vamos a aprovecharlo.
Si ya tienes todo eso provisionado en tu infra, puedes ir directo al módulo de kubernetes, pero son necesarias
algunas tags obligatoriasen las subnets public y private para que el módulo kubernetes reconozca estas subnets como suyas, entonces presta atención a eso. Abajo las tags necesarias:
"kubernetes.io/cluster/${var.cluster_name}" = "shared"
"kubernetes.io/role/elb" = "1"
Generalmente la propia AWS sugiere que se usen subnets public, private y database. Si harás uso de esa subnet de database simplemente descomenta la línea abajo comentada en locals.tf.
network_resources = toset(
concat(
# [for resource in module.vpc.database_subnet_arns : resource],
[for resource in module.vpc.private_subnet_arns : resource],
[for resource in module.vpc.public_subnet_arns : resource]
)
)
Existe un movimiento de desplegar todo solamente en kubernetes, incluso la base de datos en pods distribuidos, pero como no soy DBA (Database Administrator) para aguantar esa bomba prefiero utilizar con servidores dedicados.
Si vas a usar el backend local para prueba, simplemente comenta todo el contenido de backend.tf o verifica los datos allí descritos. Yo particularmente suelo usar en la key la secuencia abajo, pero podrías usar cualquier nombre aquí que fuese único para este proyecto. Si no modificas esto entre los proyectos los tfstates se sustituirán y tendrás problemas.
Proyecto + Región + Ambiente + terraform.tfstate
key = "network/us-east-1/production/terraform.tfstate"
Este es un proyecto costoso que levanta una infraestructura de red completa para tu negocio incluso con multi-az. Cuidado con el costo $$$$$$$$$$$. Analiza la situación.
Observa lo que se levanta con este proyecto.
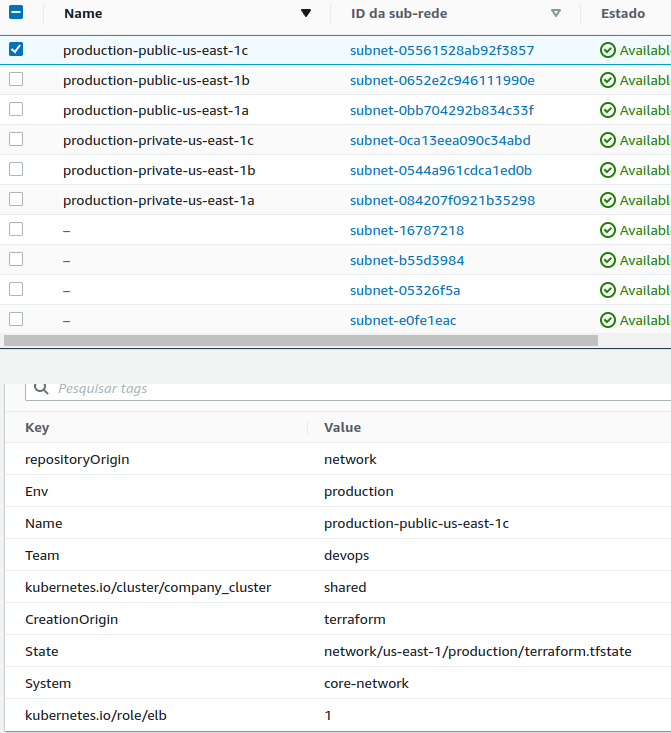
Los valores de los recursos creados que vamos a exponer queda en output.tf que puede ser leído por otros proyectos.
Los valores de entrada están en variables.tf, pero terraform.tfvars sustituye los valores allí definidos como default.
cluster_name solamente acepta letras minúsculas, números y -pues algunos recursos que usarán esta variable poseen limitaciones.
Entra en la carpeta del proyecto por terminal y ejecuta.
terraform init
terraform apply
Imagen para usar en los nodos del clúster
Si partimos de una imagen base de ubuntu en una nueva máquina que se cree cuando sea necesario escalar, tendremos que hacer todos los ajustes del sistema operativo, instalación del container runtime y los binarios de kubernetes. Cada vez que la máquina se iniciara ejecutaría todos los pasos. Para evitar este proceso demorado, podríamos preparar una imagen con todo instalado y dejar en el punto correcto para, o iniciar el clúster o entrar en uno.
La mejor forma de cocinar, el término es ese mismo, una imagen es usando Packer. Una vez que tengas esa imagen lista, podremos avanzar al proyecto final.
Instala packer en tu máquina https://learn.hashicorp.com/tutorials/packer/get-started-install-cli
curl -fsSL https://apt.releases.hashicorp.com/gpg | sudo apt-key add -
sudo apt-add-repository "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main"
sudo apt-get update && sudo apt-get install packer
Packer básicamente levanta una ec2 con una imagen base (en el caso usamos un ubuntu minimal) ejecuta todos los comandos que deseas, crea una imagen, y guarda. Los comandos pueden ser a través de varios métodos, pero generalmente yo acabo usando o scripts o ansible con sus playbooks. Como son muy pocos comandos, un script aquí resolvería el problema fácilmente. Puse a disposición las dos formas, solo elige la tuya y sigue.
Vale recordar que el id de la ami cambia de acuerdo con la región base de ubuntu cambia el id. Por lo tanto, si estás en otra región que no sea la del proyecto necesitas buscar el id de la ami y modificar. Para localizar una ami usa https://cloud-images.ubuntu.com/locator/ec2
Packer con Shell Script
Ya en la carpeta con los archivos de packer
# Para descargar los plugins
packer init .
# Para construir la imagen
packer build .
### ....
#==> Builds finished. The artifacts of successful builds are:
#--> amazon-ebs.node: AMIs were created:
#us-east-1: ami-09e94a872c3b5bc19 << ESTO ES LO QUE QUEREMOS
La salida mostrará el ami_id que usaremos en el proyecto abajo.
Kubernetes_project (aún no obtuve éxito)
Deuda técnica. Con un master solamente funciona bien, con 2 masters, cuando uno es detenido, a la hora de volver no está tomando las configuraciones del init del master que quedó. Inicia otro clúster. Si entran dos al mismo tiempo está dando problema, creo que es a la hora de tomar la IP, tal vez el loop está tomando IP de la máquina que no tiene certificado aún, pues cuando entra una de cada vez funcionaLo ideal es tener 3 instancias masters con IPs fijas. En auto scale, si paras interrumpes una máquina levanta otra aumentando el clúster.
Llegamos al proyecto principal. Este proyecto lee los datos del proyecto network y llama kubernetes_module pasando todas las variables necesarias para la creación del clúster. Se hizo de esta forma para que el módulo pueda ser reutilizado futuramente para otras instalaciones solo pasando las variables necesarias.
Módulo no es proyecto. Es como si fuese biblioteca de código que contiene funciones.
Otro detalle de este proyecto es que vamos a usar un recurso de terraform llamado remote state. Cuando creamos un recurso en terraform guarda todo lo que de hecho fue creado en el archivo .tfstate que subimos a nuestro backend. Podemos leer un backend de otro proyecto para tomar los recursos y aprovechar en este proyecto y es eso lo que vamos a hacer aquí. Vamos a leer los recursos del proyecto network para tener acceso a las subnets, vpc, etc... y llamar el módulo pasando los parámetros.
Observa que el remote.tf apunta al tfstate del proyecto network. Si vas a hacer esto local necesitas cambiar para el método abajo. Simplemente comenta el remote de S3 y descomenta el local.
data "terraform_remote_state" "remote" {
backend = "local"
config = {
path = "../network/terraform.tfstate"
}
}
Las siguientes variables dentro de locals.tf toman los valores del proyecto de network:
- vpc_id
- vpc_cidr_blocks
- cluster_name
Otras variables están declaradas en variables.tf y son sustituidas por los valores en terraform.tfvars cuando declaradas.
Una breve explicación para archivos del módulo
Security Group
El sec-groups.tf contiene los permisos necesarios de comunicación entre los masters, nodos, bastion y load balancer como muestra en la figura abajo.
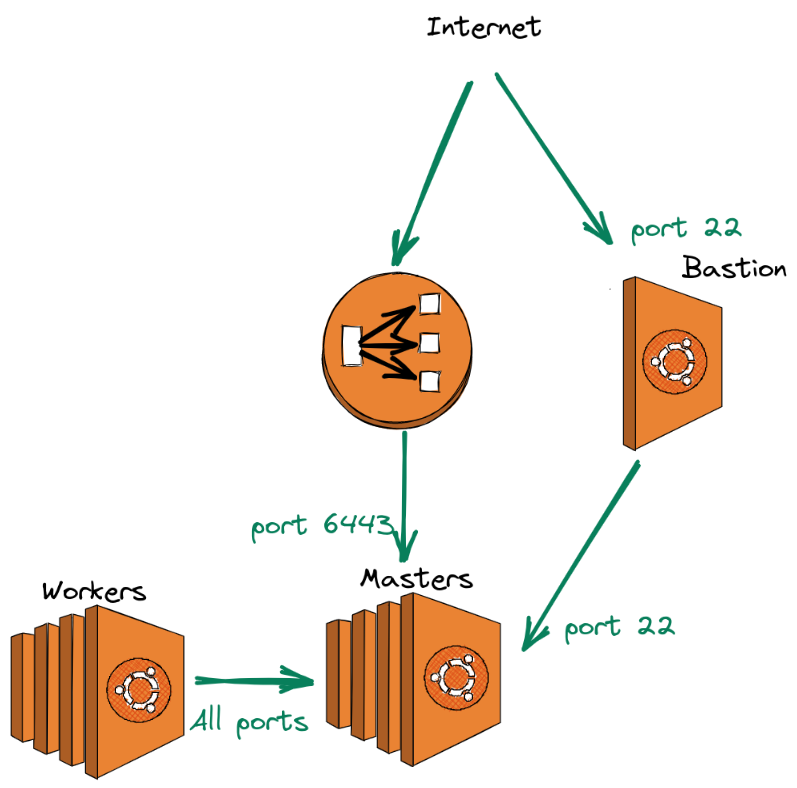
El archivo iam.tf crea los permisos necesarios para la creación de nodos que kubernetes ejecutará. Fue utilizado como base los permisos del repositorio de kops https://github.com/kubernetes/kops/tree/master/pkg/model/iam/tests
terraform init
terraform apply
Load Balancer
Masters y Workers
curl -sk https://api-company-cluster-10fbcbc105819c5f.elb.us-east-1.amazonaws.com:6443 | jq -r '.kind'
MASTERS=$(aws ec2 describe-instances --filters Name=tag-key,Values="kubernetes.io/cluster/company-cluster" --region us-east-1 | jq -r '.Reservations[].Instances[] | select (.State.Name == "running") | select(.Tags[].Key == "k8s.io/role/master") | .PrivateIpAddress')
mkdir -p /home/$USER/.kube
sudo cp -i /etc/kubernetes/admin.conf /home/$USER/.kube/config
sudo chown -R $(id -u $USER):$(id -g $USER) /home/$USER/.kube/