Conceptos de Observabilidad
La observabilidad representa un cambio fundamental en la forma en que monitorizamos sistemas, permitiendo comprenderlos de fuera hacia dentro. A diferencia de la monitorización tradicional, la observabilidad posibilita hacer preguntas sobre el sistema sin necesariamente conocer su funcionamiento interno detallado. Esta capacidad es especialmente crucial para identificar y resolver no solo problemas conocidos, sino también "problemas desconocidos" - aquellos que no podríamos anticipar.
Para alcanzar una observabilidad efectiva, los sistemas necesitan estar adecuadamente instrumentados. La instrumentación consiste en la capacidad del código de emitir señales que nos permiten entender su comportamiento. OpenTelemetry (OTel) se concentra inicialmente en tres tipos fundamentales de señales:
- Traces (Rastreos): Permiten visualizar el camino de una petición a través de diferentes servicios
- Métricas: Proporcionan datos cuantitativos sobre el rendimiento del sistema
- Logs: Registran eventos específicos del sistema
Es importante notar que, aunque OpenTelemetry comienza con estos tres pilares, su arquitectura fue diseñada para expandir e incorporar otros tipos de telemetría conforme la tecnología evoluciona.
Contexto de la Computación Moderna
OpenTelemetry surgió como respuesta a las necesidades específicas de la era cloud-native, donde las aplicaciones se caracterizan por:
- Arquitecturas distribuidas
- Componentes serverless
- Ejecución en contenedores
- Comunicación intensa entre diferentes servicios
En este contexto, el rastreo distribuido (distributed tracing) gana especial importancia, pues permite visualizar y comprender el flujo de datos a través de múltiples servicios y componentes.
La eficacia de la observabilidad puede ser medida directamente por su impacto en los indicadores de negocio, especialmente:
- Mean Time To Detection (MTTD): Tiempo para detectar un problema
- Mean Time To Resolution (MTTR): Tiempo para resolver un problema
- Disponibilidad del servicio (Service Level Objectives - SLOs)
Evolución de la Monitorización
Para contextualizar la importancia de OpenTelemetry, es útil comparar con el escenario tradicional:
Aplicaciones Monolíticas:
- Ejecución en un único proceso
- Comunicación directa con base de datos
- Diagnóstico centralizado
- Análisis cronológico simplificado
Aplicaciones Modernas:
- Múltiples servicios distribuidos
- Comunicación asíncrona
- Dependencias complejas
- Necesidad de correlación entre diferentes señales
Esta evolución destaca por qué las herramientas tradicionales de monitorización no son más suficientes para sistemas modernos, y por qué necesitamos un enfoque más sofisticado como OpenTelemetry.
Dificultades para Encontrar el Problema
En un escenario donde tenemos el monolito que pierde la comunicación con la base de datos, generalmente íbamos directamente a los logs para buscar los registros de todo lo que ocurrió, pues estaban en orden cronológico y en un solo lugar.

El problema comienza a surgir cuando un sistema llama a otro sistema que llama a otro. Si tuviéramos la siguiente estructura, ¿dónde podría estar el problema?
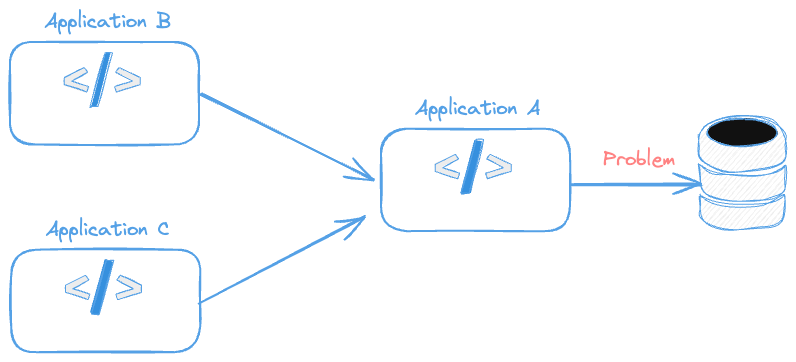
- Aplicación A no consigue comunicarse con la base de datos.
- Aplicación B no consigue comunicarse con la Aplicación A y causa algún fallo en la base de datos.
- Aplicación C no consigue comunicarse con la Aplicación A y causa algún fallo en la base de datos.
Y esto se volverá cada vez más complejo.
Si se añadiera la información de que la Aplicación B siempre funciona con la Aplicación A sabríamos que B y A funcionan, es decir, no tenemos problema entre ellos y la comunicación con la BD está activa. Siendo así ya sabríamos que el problema está en la Aplicación C.
En esto es en lo que el trace ayuda, a entender la historia entre los diferentes componentes.
- El log nos informará del proceso único de la historia de la aplicación y lo que ocurrió en ese proceso.
- Las métricas nos ayudan a ver la salud de la aplicación.
- El trace el contexto, es decir, el camino, el camino distribuido entre los diferentes componentes.
Así será posible entender cómo los componentes se están comunicando unos con otros.
Logs
Un log es un registro temporal de un evento que ocurrió en un sistema. Es como una "anotación digital" que contiene:
- Un timestamp (fecha y hora del evento)
- Un mensaje describiendo lo que ocurrió
- Generalmente también incluye un nivel de severidad (como ERROR, WARN, INFO, DEBUG)
Por ejemplo, cuando haces login en un sitio web, el sistema puede generar un log así:
2024-01-14 10:30:15 [INFO] Usuario 'juan123' realizó login con éxito
Los logs son independientes - es decir, no necesitan estar necesariamente vinculados a una acción específica del usuario o transacción. Pueden registrar cualquier tipo de evento del sistema, desde errores hasta operaciones rutinarias.
Una característica importante de los logs es que son como "fotografías" de momentos específicos - registran lo que ocurrió en aquel instante, pero no muestran automáticamente el camino que llevó hasta aquel evento o lo que ocurrió después.
Métricas
Las métricas son datos numéricos que representan el estado o comportamiento de un sistema a lo largo del tiempo. Son medidas cuantitativas que, cuando se recolectan y analizan, ayudan a entender el rendimiento, la salud y la utilización de recursos de una aplicación o infraestructura.
Tipos Comunes de Métricas:
- Contadores: Números que solo aumentan (ej: total de peticiones recibidas)
- Medidores: Valores que pueden aumentar o disminuir (ej: usuarios activos)
- Histogramas: Distribución de valores en intervalos (ej: tiempo de respuesta)
Ejemplos Prácticos:
- Tasa de errores por minuto
- Uso de CPU y memoria
- Tiempo medio de respuesta de las peticiones
- Número de usuarios conectados
- Cantidad de transacciones por segundo
- Espacio en disco disponible
- Tamaño de la cola de procesamiento
Vale la pena una lectura también sobre los niveles de servicio de la observabilidad para entender dónde estos números pueden ayudarnos.
Traces: Rastreo Distribuido
Un trace (rastro) es como una "historia" que muestra el viaje completo de una petición a través de un sistema distribuido. Imagina una línea de tiempo detallada que registra cada etapa que una petición recorre, desde el momento en que entra en el sistema hasta su conclusión.
Conceptos Fundamentales
Trace es el viaje completo de una petición. Compuesto por una serie de spans (tramos) conectados e identificado por un trace ID único.
Muestra el flujo end-to-end a través de diferentes servicios
Un Span (Tramo) representa una única operación dentro del trace. Puede ser una llamada HTTP, consulta de base de datos, o procesamiento interno y contiene información crucial:
- Nombre de la operación
- Timestamps (inicio y fin)
- Duración
- Estado de la operación
- Atributos (metadatos)
- Eventos importantes durante la ejecución
Los spans se organizan en una estructura padre-hijo. Un span padre puede tener múltiples spans hijos. Cada span hijo representa una sub-operación del span padre. Por ejemplo, cuando haces login en un sitio web, un trace puede mostrar:
- Recepción de la petición de login
- Validación de las credenciales
- Consulta a la base de datos
- Generación del token de acceso
- Retorno de la respuesta
Esta estructura permite identificar rápidamente dónde están los cuellos de botella de rendimiento o dónde ocurren errores en sistemas distribuidos.
Vamos a demostrar un trace visualmente usando Jaeger-UI. De forma gráfica tenemos algo como lo que vemos abajo. No vamos a entrar en detalles ahora, pero podemos ver que funciona con un árbol de llamada con relación padre-hijo de quién llamó a quién.
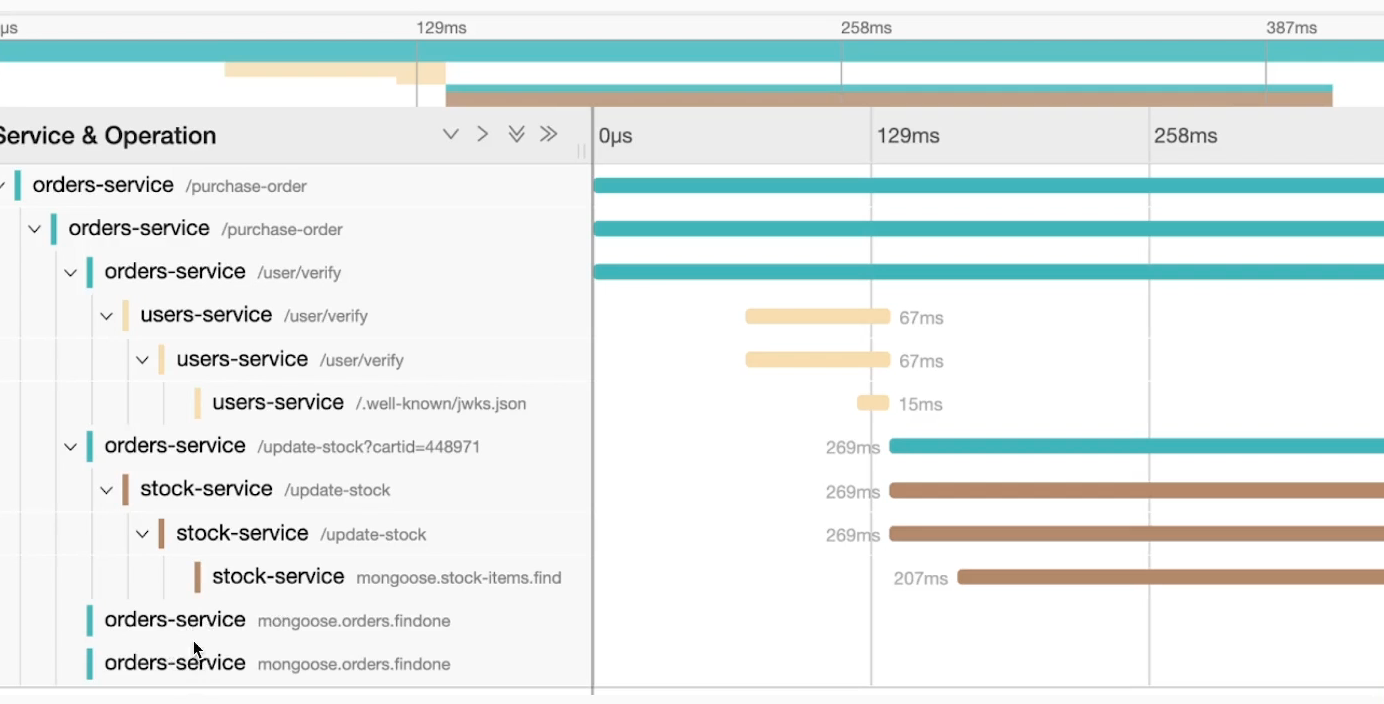
Observa que el trace cuenta una historia de lo que ocurrió con una llamada a /purchase-order de forma visual en árbol. Al lado tenemos una timeline para ayudar a entender el tiempo que las cosas fueron procesadas.
Lo que estamos viendo aquí es lo que llamamos Context, es decir, contexto de todo lo que ocurrió a partir de la llamada principal y el tiempo que tardó en completar todo y el tiempo de cada etapa.
Solamente después de que la llamada a /user/verify fue completada en 67ms fue hecha la llamada a /update-stock.
Entonces tenemos algo como /purchase-order > /user/verify > /update-stock.
Con el trace podemos ver lo que fue ejecutado en secuencia y lo que fue ejecutado en paralelo.