ETCD Alta Disponibilidade
O ETCD é um banco de dados de chave-valor seguro, rápido e simples.
Geralmente um banco de dados guarda os dados em forma de tabela. 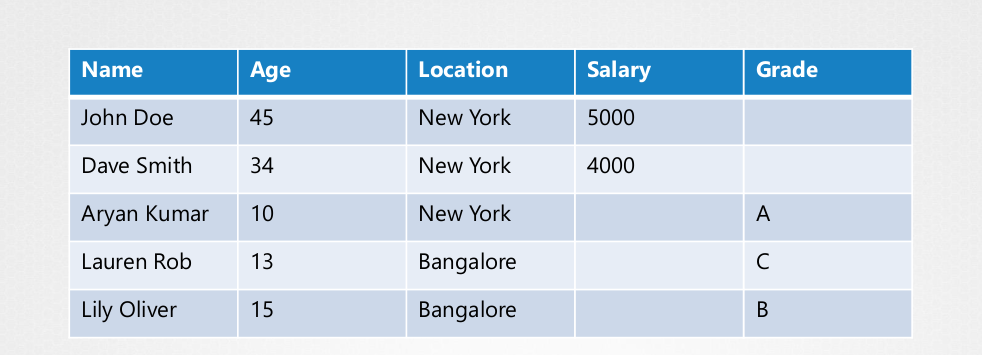
Mas o ETCD guarda os dados em forma de documento ou pages. Isso significa que cada indivíduo na tabela tem o seu arquivo de chave-valor. Alterar cada um dos documentos não altera outros arquivos.
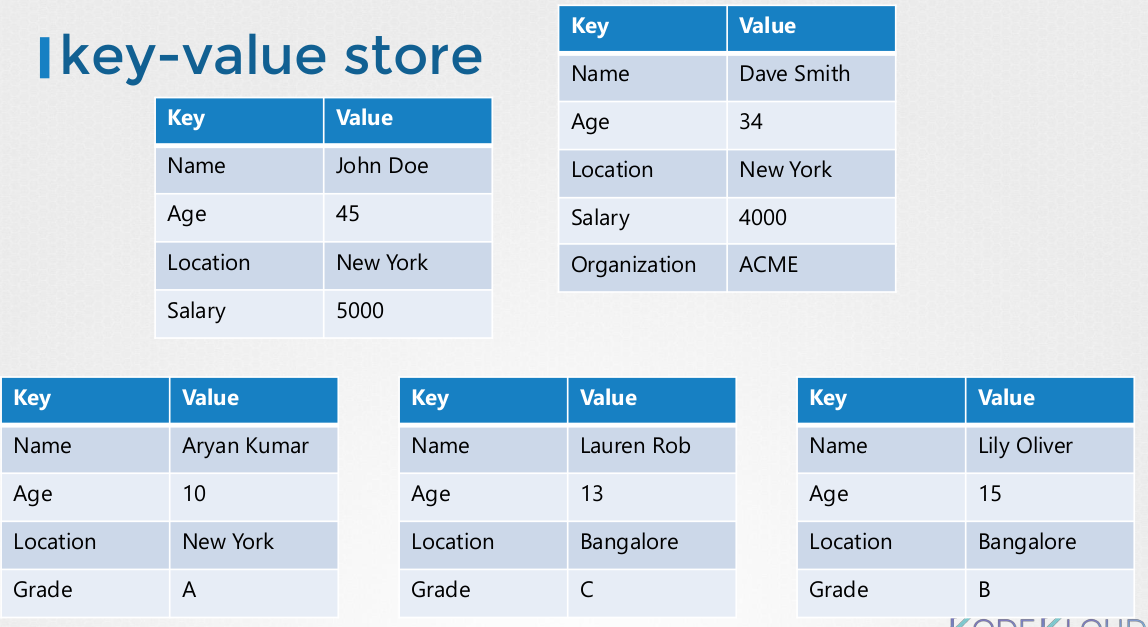
O ETCD opera de maneira distribuída, mas como exatamente isso funciona?
Tanto a leitura quanto a escrita podem ser realizadas em qualquer uma das instâncias do ETCD, com a garantia de que os dados entre elas permanecerão consistentes. Enquanto a leitura não apresenta dificuldades, o processo de escrita merece uma explicação mais detalhada.
Em um cluster ETCD, uma das instâncias é designada como líder (leader), enquanto as demais são seguidoras (followers). Quando uma solicitação de escrita é enviada diretamente ao líder, este a executa automaticamente e replica os dados para os seguidores. No caso de uma escrita ser feita em um endpoint de um seguidor, este recebe a solicitação, encaminha-a ao líder para ser processada e então replica os dados atualizados para os outros membros do cluster.
Uma escrita só é considerada completa quando é replicada com sucesso para a maioria dos membros do cluster. Este mecanismo é viabilizado pelo Raft Consensus, um algoritmo utilizado pelo ETCD, que você pode conhecer melhor através deste link.
Em suma, para garantir a resiliência do sistema, o Raft Consensus exige a presença de pelo menos três instâncias do ETCD, evitando assim pontos únicos de falha.
| Num Nodes | Pontos de falha | Maioria (Nodes/2 +1) | Utilizável |
|---|---|---|---|
| 1 | 0 | 1 | Sim, mas não recomendado |
| 2 | 0 | 2 | Não |
| 3 | 1 | 2 | Sim |
| 4 | 1 | 3 | Não |
| 5 | 2 | 3 | Sim |
| 6 | 3 | 4 | Não |
| 7 | 3 | 4 | Sim |
É importante ressaltar que o número de instâncias no cluster do ETCD precisa ser ímpar e maior que 3 para pelo menos 1 ponto de falha.
Quando o líder torna-se indisponível, é iniciada uma votação para eleger um novo líder. Cada instância no cluster se propõe a assumir o papel de líder, e a votação é baseada no tempo. Cada instância gera um tempo randômico e comunica aos demais que está se propondo a ser o novo líder. A instância que gerar o menor tempo será a primeira a comunicar e assumir a liderança.
Se um seguidor ficar indisponível em um cluster de 3, é crucial que pelo menos o líder e outro seguidor possam replicar os dados, garantindo assim a maioria (2 em 3) para manter a consistência dos dados.
Para que uma escrita seja considerada bem-sucedida, não é necessário que todos os membros do cluster recebam a replicação dos dados, mas sim a maioria. Quando um seguidor retorna à disponibilidade, os dados são sincronizados com ele.