ETCD High Availability
ETCD is a secure, fast, and simple key-value database.
Generally, a database stores data in table format. 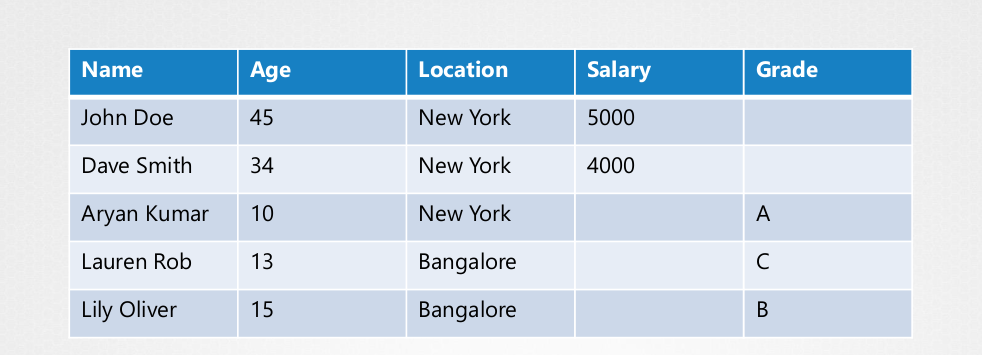
But ETCD stores data in document or page format. This means that each individual in the table has its own key-value file. Changing each document doesn't alter other files.
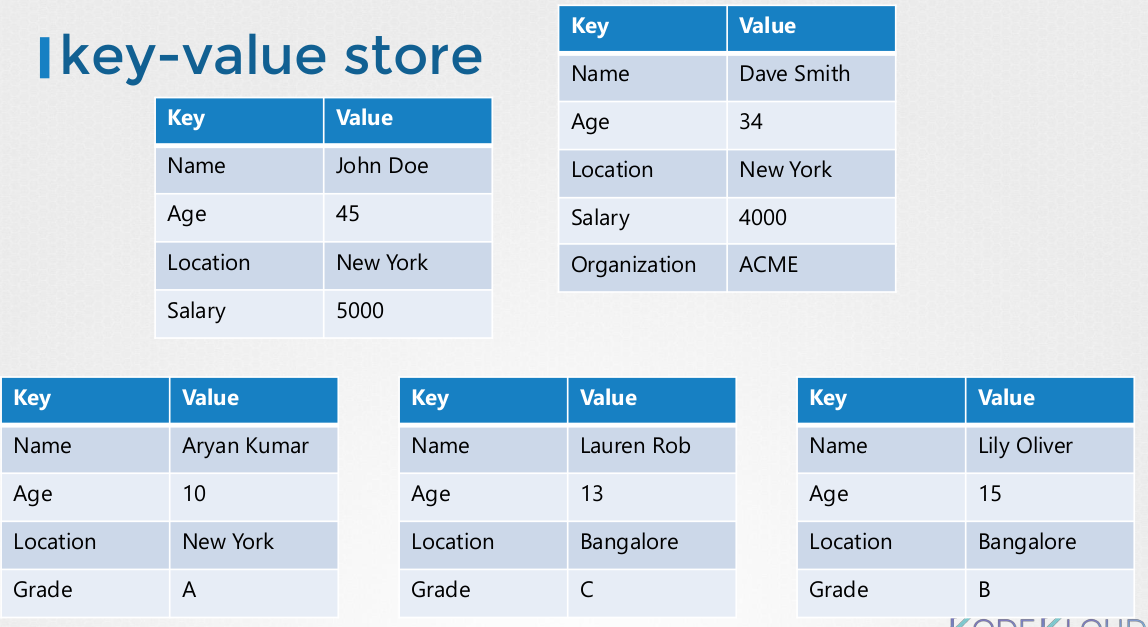
ETCD operates in a distributed manner, but how exactly does this work?
Both read and write operations can be performed on any ETCD instance, with the guarantee that data among them will remain consistent. While reading presents no difficulties, the write process deserves a more detailed explanation.
In an ETCD cluster, one instance is designated as the leader, while the others are followers. When a write request is sent directly to the leader, it executes it automatically and replicates the data to the followers. If a write is made to a follower's endpoint, it receives the request, forwards it to the leader for processing, and then replicates the updated data to other cluster members.
A write is only considered complete when successfully replicated to the majority of cluster members. This mechanism is enabled by Raft Consensus, an algorithm used by ETCD, which you can learn more about through this link.
In summary, to ensure system resilience, Raft Consensus requires at least three ETCD instances, thus avoiding single points of failure.
| Num Nodes | Failure Points | Majority (Nodes/2 +1) | Usable |
|---|---|---|---|
| 1 | 0 | 1 | Yes, but not recommended |
| 2 | 0 | 2 | No |
| 3 | 1 | 2 | Yes |
| 4 | 1 | 3 | No |
| 5 | 2 | 3 | Yes |
| 6 | 3 | 4 | No |
| 7 | 3 | 4 | Yes |
It's important to note that the number of instances in the ETCD cluster needs to be odd and greater than 3 for at least 1 failure point.
When the leader becomes unavailable, a vote is initiated to elect a new leader. Each instance in the cluster proposes to assume the leader role, and voting is time-based. Each instance generates a random time and communicates to others that it's proposing to be the new leader. The instance that generates the shortest time will be the first to communicate and assume leadership.
If a follower becomes unavailable in a 3-node cluster, it's crucial that at least the leader and another follower can replicate data, thus ensuring the majority (2 out of 3) to maintain data consistency.
For a write to be considered successful, it's not necessary for all cluster members to receive data replication, but rather the majority. When a follower returns to availability, data is synchronized with it.