Docker Swarm - Parte 1
Para iniciar esse aprendizado vamos precisar das máquinas zeradas. Por isso se estiver seguindo o estudo, vamos destruir tudo e criar do zero.
❯ cd DCA/Environment
❯ vagrant destroy -f
❯ vagrant up
Docker Swarm é uma ferramenta de orquestração de containers, que possibilita o usuário a gerenciar multiplos containers distribuidos em diversas máquinas hosts (cluster). O Swarm não é a ferramenta mais utilizada hoje em dia, perdeu para o Kubernetes. Porém é bom conhecer o concorrente, assim como o Nomad da Hashicorp. A maioria dos conceitos que aprender aqui funciona para o kubernetes.
Conceitos Básicos
Cluster
Cluster é um grupo de host que fornece a capacidade computacional para a orquestração dos containers. Um cluster é a soma da força de todos os seus nodes. O uso de cluster barateia o custo da infra. Uma máquina extremante potente custa mais caro do que várias máquinas menos potentes juntas.
Escalonamento horintal ou Horizontal Scalingé quando agregamos mais uma máquina (node) ao nosso cluster.Escalonamento Vertical ou Vertical Scalingé quando melhoramos a configuração da nossa máquina.
Nodes
Node é cada host (máquina/computador) de um cluster. Um node pode ser master ou worker.
- Nós masters são os nós de controles.
- Nós workers são onde serão de fato deployados os containers.
Consensus
Raft Consensus é um algorítmo que implementa o protocolo consensus que garante a confiabilidade do cluster. O Docker utiliza esse algorítmo e esse site explica bem como funciona . É esse algorítmo que garante a ordem no cluster. O consensus está aos nodes masters que teremos no nosso cluster para controlar os workers.
Os nodes masters pertencente de um cluster sempre estarão em algum dos estados abaixo do Raft Consensus:
- Follower (seguidor, não da ordem, apenas segue)
- Candidate (candidato a se tornar lider)
- Leader (Lider)
No Raft Consensus cada node master tem direito a um voto para eleger um lider.
Se vc só tem um nó ele inicia como seguidor, se candidata a ser o lider e como só tem 1 para votar (ele mesmo) ele se torna o lider.
Se vc tiver somente um único nó master e ele cair, perderá o controle do cluster, por isso é necessário uma redundância de nós masters em sistemas distribuídos. Como falei todo nó master entra como seguidor e se ele não encontrar um lider ele se candidata e o nó que tiver maior número de votos será o lider. Se o node master cair, os outros masters novamente entram em estado de candidatos e elegem um novo lider. O lider o estado real do cluster, por isso ele precisa saber de tudo que se passa com os seguidores.
Não é necessário entender como funciona a eleição, somente o número de nodes masters para se ter uma redundância caso o lider fique offline.
A fórmula de tolerância é (N-1)/2 falhas e precisa de um quorum de (N/2)+1. Quorum é a quantidade mínima de nodes para garantir a maioria.
| Nodes | Quorum | Tolerância Falha |
|---|---|---|
| 1 | (1/2)+1 = 1.5 | (1-1)/2 = 0 |
| 2 | (2/2)+1 = 2 | (2-1)/2 = 0.5 |
| 3 | (3/2)+1 = 2.5 | (3-1)/2 = 1 |
| 4 | (4/2)+1 = 3 | (4-1)/2 = 1.5 |
| 5 | (5/2)+1 = 3.5 | (5-1)/2 = 2 |
| 6 | (6/2)+1 = 4 | (6-1)/2 = 2.5 |
| 7 | (7/2)+1 = 4.5 | (7-1)/2 = 3 |
*Podemos observar que reprecisa ser impar a partir de 3 para ter pelo menos 1 redundância. Trabalhar com pares é perde de tempo e recurso.
Estudos mostram que replicação de dados consomem muita rede e processamento. Logo, 3 é suficiente, 5 é uma boa escolha, 7 começa a piorar e 9 piora o desempenho. Reza a lenda que quem tem 1 não tem nenhum, então no mínimo 3 por favor.
Criando o cluster
Para o nosso lab prepare um terminal para cada máquina (master, worker1 worker2). Confira se o docker esta funcionando com o comando docker container ls
confira os ips das máquinas
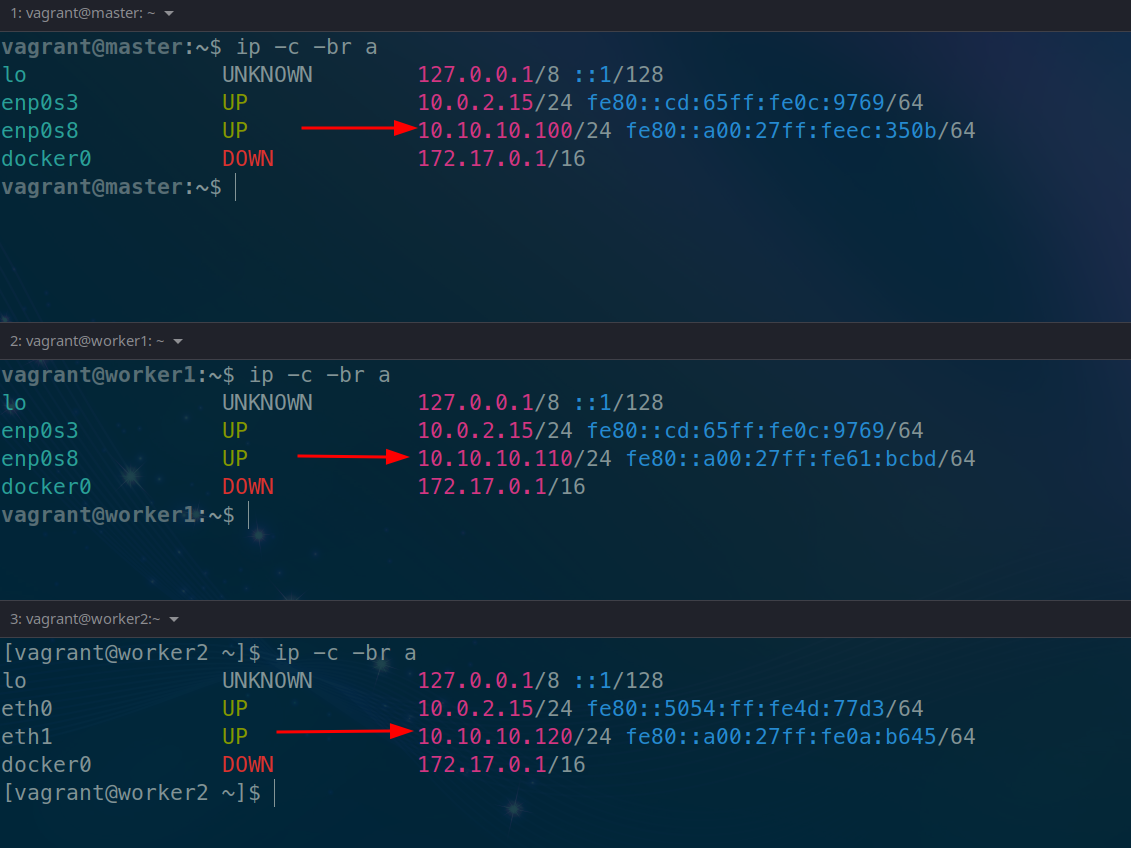
Criar o cluster bastar iniá-lo na máquina master. Lembrando que vc deve passar o ip que nela está.
# O advertise significa que ele irá acusar o endereço passado para se comunicar com o cluster.
vagrant@master:~$ docker swarm init --advertise-addr 10.10.10.100
Swarm initialized: current node (jdmwyhbti8s3fnmd17lw79rhw) is now a manager.
To add a worker to this swarm, run the following command:
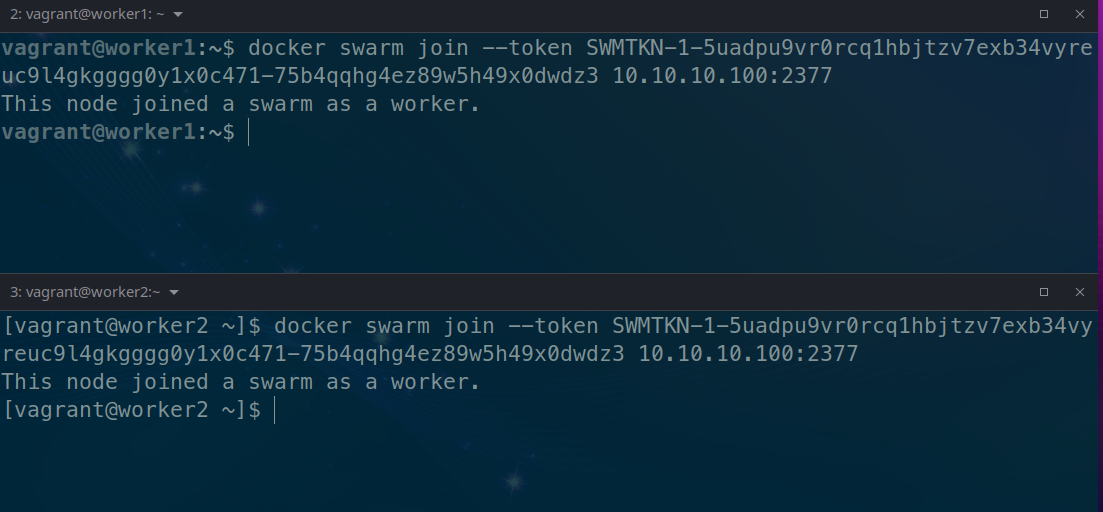
# Observe que ele já deu o comando para entrada dos nodes workers
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-75b4qqhg4ez89w5h49x0dwdz3 10.10.10.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
vagrant@master:~$
É possível utilizar o hostname da máquina para iniciar o cluster? Sim, mas não é boa prática, pois se o dns falhar gera um problema. O jeito mais seguro é o ip.
Executando o comando nos nodes acima nos nodes para entrada do cluster
Conferindo os nodes no master...
vagrant@master:~$ docker node ls
# Observe que existe o leader status e availability
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
Desligando a máquina para conferir se o status muda
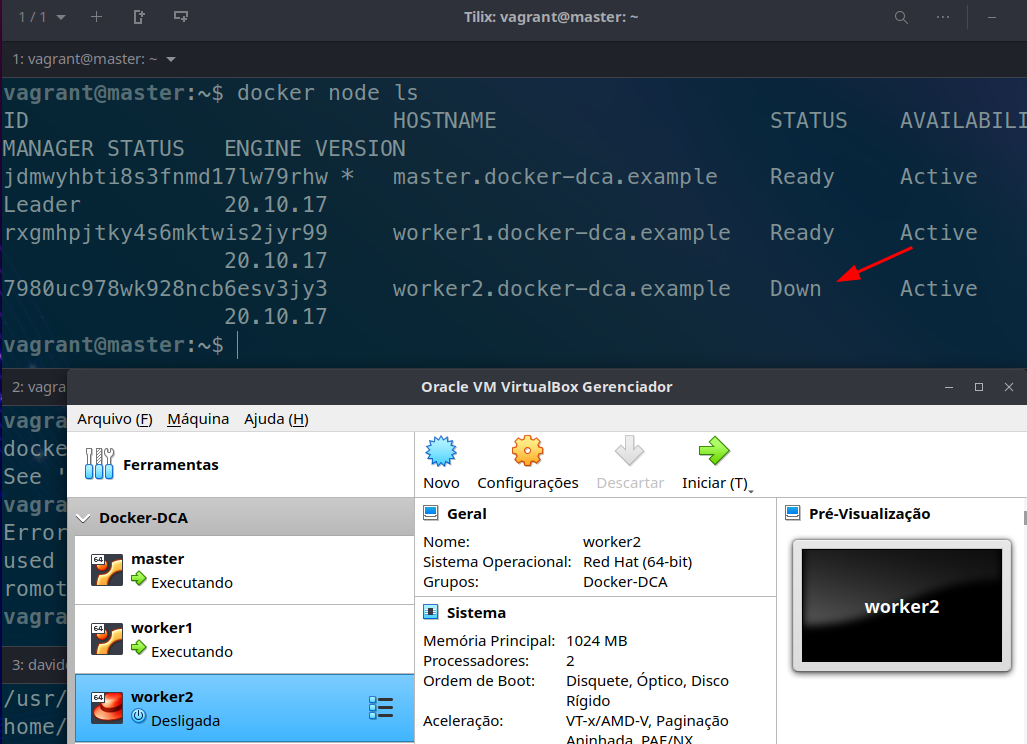
Os comando
docker nodesão limitados aos masters.
Um worker node pode ser promovido a master caso queira e demitido também.
vagrant@master:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
# com o comando promote e passando o hostname da maquina
vagrant@master:~$ docker node promote worker1.docker-dca.example
Node worker1.docker-dca.example promoted to a manager in the swarm.
vagrant@master:~$ docker node ls
# Veja que ele atingiu o estado de Reachable (alcançavel)
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active Reachable 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
# Agora demitindo voltando o nó para worker com o comando demote
vagrant@master:~$ docker node demote worker1.docker-dca.example
Manager worker1.docker-dca.example demoted in the swarm.
vagrant@master:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
vagrant@master:~$
Faça alguns teste promovendo todo mundo para master e derrubando um para ver a eleição de um novo lider.
Logo em seguida desligue mais uma máquina e veja que ele não consegue eleger com duas acontecendo o problema do slip brain onde uma máquina sozinha não tem a maioria não sabe se ela caiu ou a outra e perde o controle do cluster.
o comando para pegar o token caso vc não se lembre
vagrant@master:~$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-7wzw0dvnf6rboj7jiev31rnm3 10.10.10.100:2377
vagrant@master:~$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-75b4qqhg4ez89w5h49x0dwdz3 10.10.10.100:2377
Portas Utilizadas
Algumas portas precisam estar disponíveis
| Porta | Protocolo | Uso |
|---|---|---|
| 2377 | tcp | Comunicações de gerencia do cluster |
| 7946 | tcp e udp | Comunicação entre nodes |
| 4789 | udp | Tráfego de rede overlay |