Controle de Execução
Até agora conseguimos escrever pipelines que possuem um início e fim e param a execução se algo falhar, inclusive os jobs dependentes. Este é o comportamente padrão e faz sentido, mas às vezes queremos continuar a execução mesmo se uma etapa falhar ou se um conjunto de etapas falharem.
Um exemplo clássico é quando aplicamos um lint para ver se o código está bem identado. Se não passar no lint ele vai falhar, mas o código está funcionando e poderíamos continuar a execução para procurar mais erros durante o desenvolvimento e depois acertamos tudo.
Poderíamos somar isso com análise de vulnerabilidade e depois com análise de código. Poderia falhar nas 3 etapas e passar nos testes, gerar o build, mas não queremos fazer o deploy. Daí em diante com os erros gerados podemos criar novas tasks para que os desenvolvedores acertem os problemas e tentar novamente.
Se temos vários ambientes, de desenvolvimento de staging e produção não precisamos executar todo o pipeline quando for para produção se ele vier mergeado da branch de staging onde fizeram todos os possíveis testes, seria perda de tempo. Só precisamos fazer o deploy no ambiente.
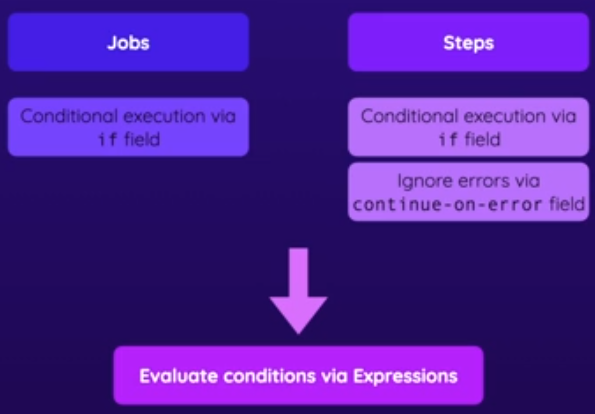
Podemos colocar condições nos jobs e nos steps, mas somente nos steps podemos ignorar caso aconteça um erro, um job precisa finalizar com sucesso ignorando erros de steps.
Expressões são usadas para criar uma condição.
Voltemos para aplicação em node usando o fluxo abaixo com 4 jobs.
name: Website Deployment
on:
push:
branches:
- main
jobs:
lint:
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache
uses: actions/cache@v4
with:
path: ~/.npm
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
run: npm ci
- name: Lint code
run: npm run lint
test:
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache
uses: actions/cache@v4
with:
path: ~/.npm
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
run: npm ci
- name: Test code
run: npm run test
- name: Upload test report
uses: actions/upload-artifact@v4
with:
name: test-report
path: test.json
build:
needs: test
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache
uses: actions/cache@v4
with:
path: ~/.npm
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
run: npm ci
- name: Build website
id: build-website
run: npm run build
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: dist-files
path: dist
deploy:
needs: build
runs-on: ubuntu-latest
steps:
- name: Get build artifacts
uses: actions/download-artifact@v4
with:
name: dist-files
- name: Output contents
run: ls
- name: Deploy
run: echo "Deploying..."
Temos 4 steps usando o cache sendo que:
- Os jobs lint e test rodam em paralelo pois não tem dependência, mas vão usar o mesmo cache, será? Como se não tem dependência?
- O test é um pre requisito para build, mas o lint não. Test gera um relatório como artefato e também faz o upload deste único arquivo.
- O build é um pré requisito para deploy, afinal ele faz o download do artefato gerado pelo build.
Vamos colocar algumas condições.
-
Só queremos que faça o upload se o teste falhar para fazer análise. Se tudo correr bem não precisamos dele. Para isso precisamor dar uma olhada no contexto de steps.
test:
runs-on: ubuntu-latest
steps:
...
- name: Test code
id: test-code # precisamos criar uma referência para ele
run: npm run test
- name: Upload test report
uses: actions/upload-artifact@v4
# Usamos o outcome ou invés do conclusion pois queremos fazer o if antes de aplicar um continue-on-error no step anterior
# if: steps.test-code.outcome == 'failure'
# Mesmo com a condição comentada acima o github continuará com o comportamento padrão de que se uma step falhar ele irá parar o job
# A função especial failure resolve o problema falaremos a seguir
if: failure() && steps.test-code.outcome == 'failure'
with:
name: test-report
path: test.json
Existem 4 funções especiais que mudam o comportamento padrão do workflow e devem ser logicamente somadas a condição para mudar o comportamente padrão do workflow.

- Failure() Sempre retorna true se qualquer step ou job anterior falhar
- success() retorna true se nenhum step anterior falhar.
- always() Sempre retorna true forçando a execução mesmo se o workflow for cancelado.
- cancelled() retorna true se o WORKFLOW for cancelado.
Quando adicionamos o failure() && ele somará a lógica se o step que apontamos anteriormente falhou então dá true e irá executar.
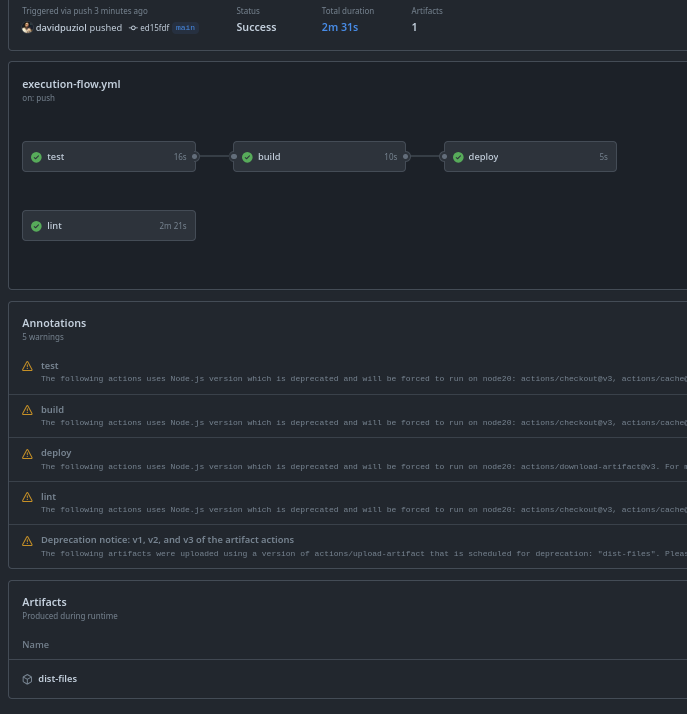
Vamos executar um workflow com o teste sem falha e outro com falha e ver o report. Na primeira imagem podemos observar que não temos o report do test como artefato e tudo passou normalmente.
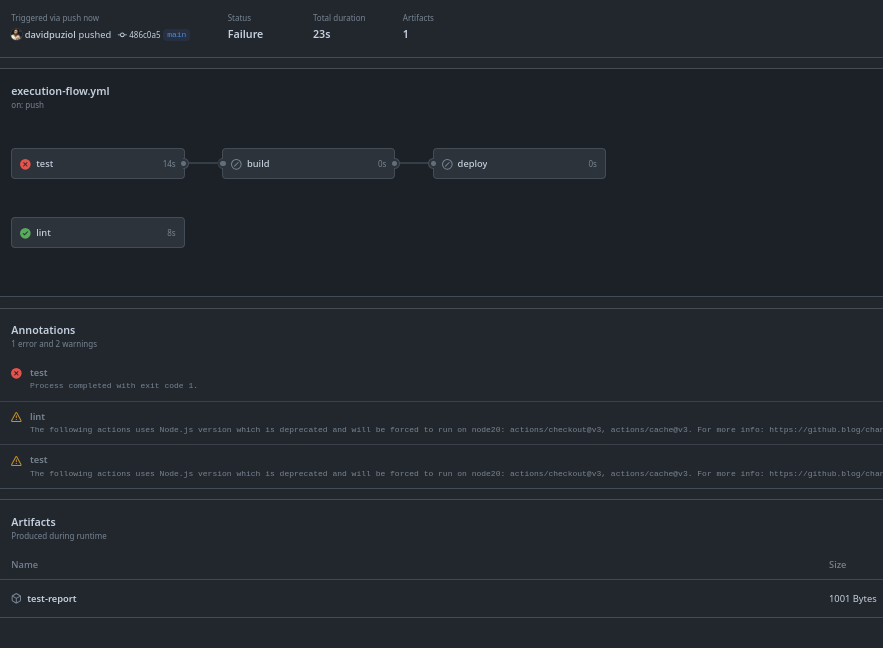
Agora forçando um erro no test ele não executou o build como esperado mas subiu o report do test como artefato
If
If também pode ser usado para jobs.
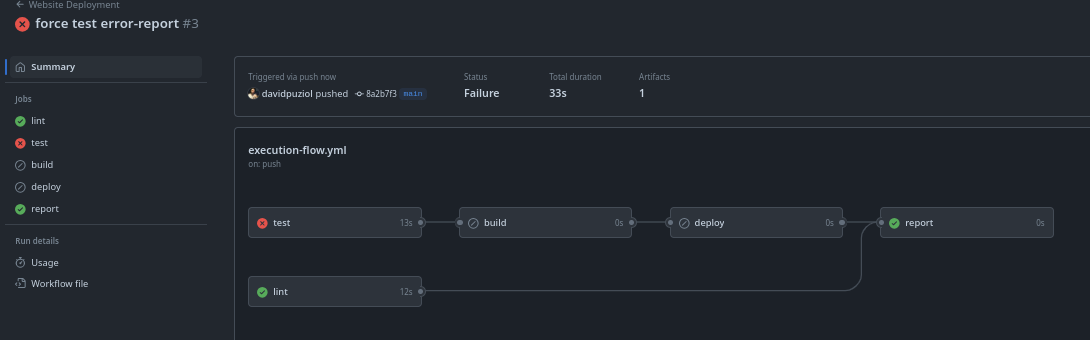
Se quisermos criar um último job que somente execute se algum outro job falhar e fizermos isso...
jobs:
lint:
...
test:
...
build:
needs: [test]
deploy:
needs: [build]
report:
if: failure()
runs-on: ubuntu-latest
steps:
- name: Output Info
run: |
echo "Faça alguma coisa quando falhar"
Ele irá fazer um skip de primeira pois irá rodar em paralelo com lint e test já identificando que ninguém falhou logo no início. Para que funcione precisaria colocar o needs para lint e deploy. No caso do deploy ele tem dependência de build e de test, logo qualquer um que falhar, falha o deploy.
jobs:
lint:
...
test:
...
build:
needs: [test]
deploy:
needs: [build]
report:
needs: [lint, deploy]
if: failure()
runs-on: ubuntu-latest
steps:
- name: Output Info
run: |
echo "Faça alguma coisa quando falhar, imprimir o contexto do github"
echo "${{ toJSON(github) }}"
Agora vamos melhorar o cache. Ao invés de fazer o cache de ~/.npm para ganhar velocidade no npm ci podemos fazer o cache de node_modules e caso cache seja restaurado nem precisamos executar o comando npm ci para instalar as dependencias.
Na documentação do action cache temos isso.

name: Website Deployment
on:
push:
branches:
- main
jobs:
lint:
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache # Para referenciar esse step
uses: actions/cache@v4
with:
path: node_modules # Mudamos a pasta
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
# Se não deu match com um cache então executa
# steps.cache.outputs.cache-hit é convertido em string por isso 'true'
# todos os blocos idênticos nos jobs subsequentes foram já alterados
if: steps.cache.outputs.cache-hit != 'true'
run: npm ci
- name: Lint code
run: npm run lint
test:
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache
uses: actions/cache@v4
with:
path: node_modules
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
if: steps.cache.outputs.cache-hit != 'true'
run: npm ci
- name: Test code
id: test-code
run: npm run test
- name: Upload test report
uses: actions/upload-artifact@v4
if: failure() && steps.test-code.outcome == 'failure'
with:
name: test-report
path: test.json
build:
needs: test
runs-on: ubuntu-latest
steps:
- name: Get code
uses: actions/checkout@v4
- name: Cache dependencies
id: cache
uses: actions/cache@v4
with:
path: node_modules
key: deps-node-modules-${{ hashFiles('**/package-lock.json') }}
- name: Install dependencies
if: steps.cache.outputs.cache-hit != 'true'
run: npm ci
- name: Build website
id: build-website
run: npm run build
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: dist-files
path: dist
deploy:
needs: build
runs-on: ubuntu-latest
steps:
- name: Get build artifacts
uses: actions/download-artifact@v4
with:
name: dist-files
- name: Output contents
run: ls
- name: Deploy
run: echo "Deploying..."
report:
needs: [lint, deploy]
if: failure()
runs-on: ubuntu-latest
steps:
- name: Output Info
run: |
echo "Faça alguma coisa quando falhar, imprimir o contexto do github"
echo "${{ github }}"
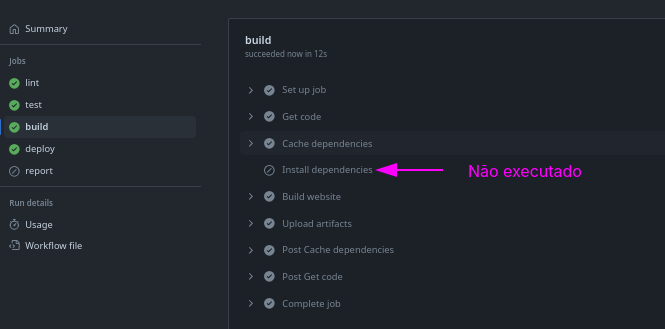
Também podemos observar que report não foi executado, pois nenhum job falhou.
Ignorar Erros com continue-on-error
Usar o containue-on-error simplesmente seta como success um step ou job mesmo se este falhar. Se fizessemos isso aqui mesmo se o teste falhar, será executado o build e o deploy inclusive o upload do artefato de erro.
test:
steps:
...
- name: Test code
id: test-code
run: npm run test
continue-on-error: true
- name: Upload test report
uses: actions/upload-artifact@v4
if: steps.test-code.outcome == 'failure'
with:
name: test-report
path: test.json
...
Matrix
O uso de uma matriz permite que você rode um job várias vezes (em paralelo) com diferentes entrada.
Um bom exemplo para esse cenário seria uma bateria de teste de versão para um mesmo build, ou compilar várias vezes um mesmo binário para diferentes plataformas.
name: Matrix Demo
on: push
jobs:
build:
# continue-on-error: true
strategy:
matrix:
node-version: [12,14,16]
operating-systems: [ubuntu-latest, windows-latest]
runs-on: ${{ matrix.operating-systems}}
steps:
- name: Get code
uses: actions/checkout@v4
- name: Install NodeJS
uses: actions/setup-node@v4
with:
node-version: ${{ matrix.node-version }}
- name: Install dependencies
run: npm ci
- name: Build website
run: npm run build
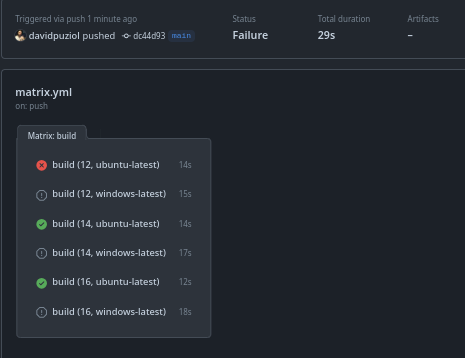
Nesse caso ele tentou as possíveis combinações entre os valores gerando 6 jobs ao mesmo tempo. Caso qualquer um deles falhar a matrix sera cancelada e ignorada.
Se quiser que continue mesmo assim podemos usar o continue-on-error e teremos essa saida.
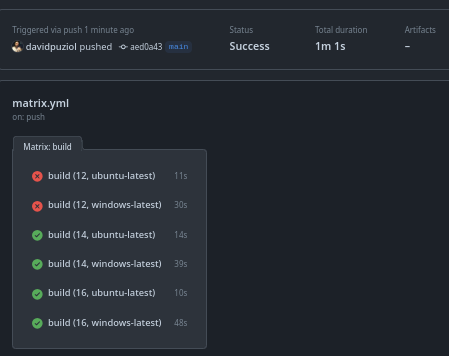

Poderíamos somente uma combinação específica no caso ubuntu-latest e versão 18 sem o windows.
...
jobs:
build:
strategy:
matrix:
# windows com 12 14 16
# linux com 12 14 e 16
node-version: [12,14,16]
operating-systems: [ubuntu-latest, windows-latest]
include:
# somado ao linux 18
- node-version: 18
operating-systems: ubuntu-latest
# retirado windows 12
exclude:
- node-version: 12
operating-systems: windows-latest
# total
# windows 14 16
# linux 12 14 16 18 # <<<<<<
...
Reaproveitamento de Workflow
Na verdade quando usando actions estamos reaproveitando um job, mas podemos reaproveitar um workflow inteiro.
Vamos criar um workflow em que o evento seja workflow_call.
.github/worfkflows/deploy.yaml
name: Deploy
on:
workflow_call:
inputs:
artifact-name:
description: Nome do artefato que sera deployado
required: false
# se não for passado nenhum input será usado o nome dist por isso o required ficou em false
default: dist
type: string
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Get build artifacts
uses: actions/download-artifact@v4
with:
name: ${{ inputs.artifact-name }}
- name: List Files
run: ls
- name: Deploying
run: echo "Deploying...."
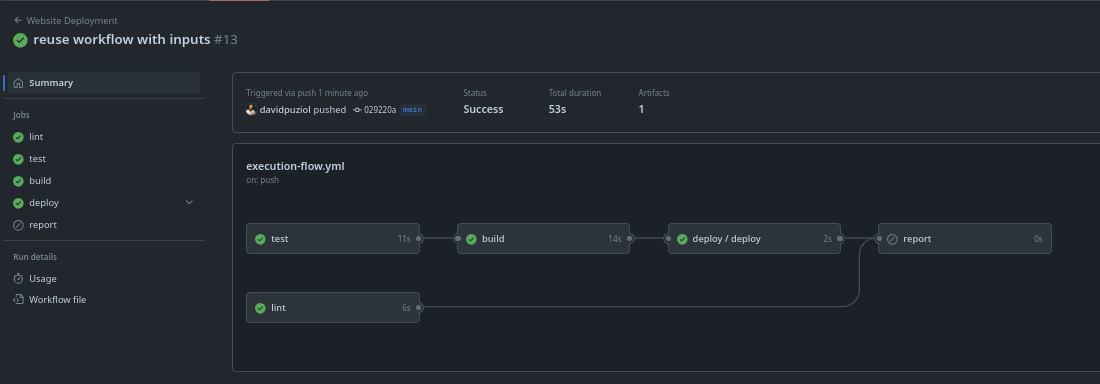
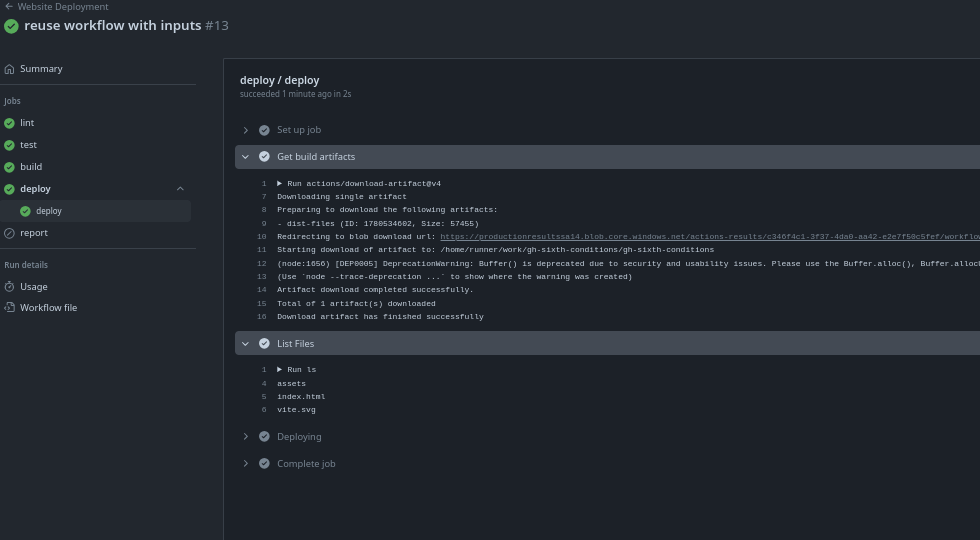
Agora podemos usar esse workflow no nosso workflow principal chamando este workflow no meio do processo.
name: Website Deployment
on:
push:
branches:
- main
jobs:
lint:
...
test:
...
build:
...
deploy:
# observe que não temos steps pois estamos chamando um workflow inteiro.
needs: build
uses: ./.github/workflows/deploy.yaml
with:
artifact-name: dist-files
report:
...
Também é possível passar secrets para dentro de workflows reutilizáveis.
Assim como temos os inputs, temos os outputs.