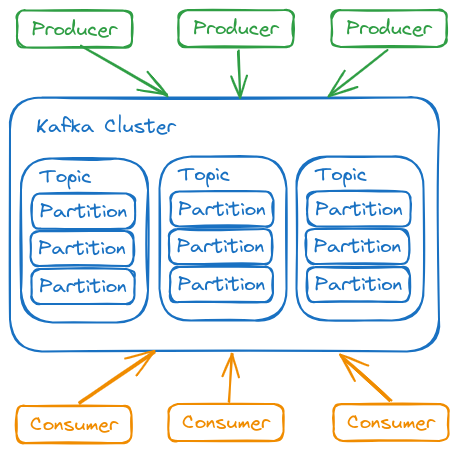
Arquitetura
O Kafka é um sistema distribuído composto por servidores e clientes que se comunicam por meio de um protocolo de rede TCP de alto desempenho.
Pode ser implantado em hardware bare-metal, máquinas virtuais, contêineres locais ou em ambientes de nuvem.
Servidores
O Kafka é executado como um cluster de um ou mais servidores que podem abranger vários datacenters ou regiões de nuvem. Alguns desses servidores formam a camada de armazenamento, chamados de brokers. Outros servidores executam o Kafka Connect, que importa e exporta continuamente dados como fluxos de eventos, integrando o Kafka a sistemas existentes, como bancos de dados e outros clusters Kafka. Para garantir alta disponibilidade e confiabilidade, um cluster Kafka é altamente escalável e tolerante a falhas: se um servidor falhar, os demais assumem sua carga de trabalho, garantindo a continuidade das operações sem perda de dados.
Clientes
Os clientes permitem que aplicativos e microsserviços distribuídos leiam, gravem e processem fluxos de eventos de maneira paralela, escalável e tolerante a falhas, mesmo diante de problemas de rede ou falhas de máquina. O Kafka inclui alguns clientes nativos e conta com diversas implementações fornecidas pela comunidade.
Os clientes estão disponíveis para Java e Scala, incluindo a biblioteca Kafka Streams, além de suporte para Go, Python, C/C++ e outras linguagens, bem como APIs REST.
Componentes do Ecossitema
- Kafka Brokers
- Cada nó do Kafka é chamado de broker. Um cluster Kafka possui vários brokers.
- É possível instalar múltiplos brokers na mesma instância alterando apenas a porta ou em servidores diferentes utilizando a mesma porta, mas com IPs distinto.
- Atribui um número sequencial (offset) às mensagens.
- Armazena as mensagens em disco.
- As mensagens não precisam ser consumidas imediatamente.
- Permite recuperação de falhas dos consumidores (softwares que reagem a um evento).
- kafka client API
- kafka connect
- kafka streams
- kafka ksql
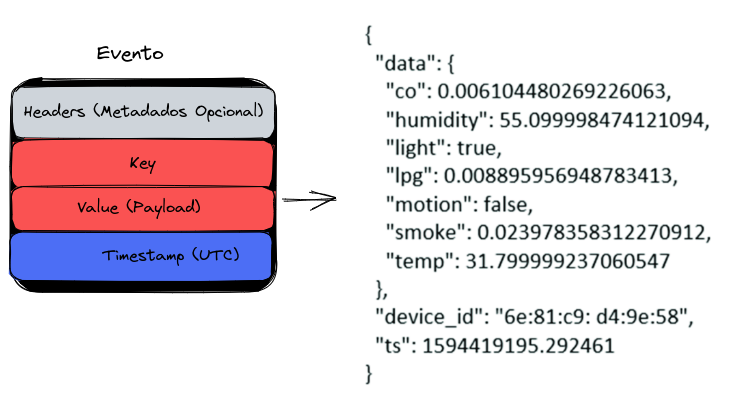
Evento
Um evento registra o fato de que "algo aconteceu" no mundo ou na sua empresa. Ao ler ou gravar dados no Kafka, isso é feito na forma de eventos. Conceitualmente, um evento possui:
- Uma chave
- Um valor
- Um timestamp
- É uma boa prática utilizar sempre o horário em UTC ao produzir eventos (producers), deixando o ajuste da data/hora correto para os consumidores, se necessário.
- Cabeçalhos de metadados opcionais.
O evento é o dado em si, e muitas vezes conhecido como payload
Veja um exemplo de evento:
- Chave do evento: "Alice"
- Valor do evento: "Fiz um pagamento de $ 200 para Bob"
- Carimbo de data/hora do evento: "25 de junho de 2020 às 14h06"
Os eventos são organizados e armazenados de forma durável em tópicos, assim como em um fórum da Internet. Quem tiver permissão pode ler os eventos a qualquer momento.
Muitas regras podem ser definidas para um tópico, mas geralmente a relação é N para N.
A key serve para separar o contexto. É possível criar um evento para um tópico que vários consumers assinam.
Um determinado consumidor pode optar por ler apenas mensagens de um tópico com uma key específica e descartar o restante. Por exemplo, um tópico TEMPERATURA, onde a key representa o nome da cidade.
Tópico
Um tópico pode ter zero, um ou muitos produtores que gravam eventos nele, bem como zero, um ou muitos consumidores que assinam esses eventos.
Não há limite para o número de tópicos. Eles podem ser criados conforme necessário.
Os eventos de um tópico podem ser lidos quantas vezes forem necessárias. Diferentemente dos sistemas tradicionais de mensagens, os eventos não são excluídos após o consumo. Em vez disso, o tempo de retenção dos eventos é configurável por tópico. Após esse período, eventos antigos são descartados.
O desempenho do Kafka é praticamente constante, independentemente do volume de dados armazenados. Portanto, manter dados por longos períodos é viável.
Em muitos casos, um evento precisa ser processado por múltiplos consumidores. Por exemplo, um evento pode registrar um depósito na conta do cliente e, simultaneamente, gerar uma notificação informando o recebimento do valor. Para garantir que todos os consumidores processam a mensagem antes de ser descartada, é possível configurar o tópico para retenção condicional.
Um tópico funciona como um grande log. O Kafka mantém eventos por um período configurável (por padrão, 1 semana), podendo ser ajustado para mais tempo ou até mesmo indefinidamente.
No caso do tópico TEMPERATURA, onde a key representa uma cidade, podemos recuperar apenas o último valor da cidade sem precisar processar todo o histórico. Esse recurso é chamado de compact log. O Kafka armazena todos os dados, mas os consumidores podem recuperar apenas o evento mais recente.
Partições de um Tópico
Os tópicos são divididos em partições, o que significa que seus eventos são distribuídos entre múltiplos brokers. Isso melhora a escalabilidade, pois permite que os clientes leiam e gravem dados simultaneamente em diferentes brokers.
Quando um novo evento é publicado em um tópico, ele é anexado a uma de suas partições. Eventos com a mesma key são sempre gravados na mesma partição, garantindo que qualquer consumidor lerá os eventos na mesma ordem em que foram produzidos.
Mensagens sem key são distribuídas em partições de forma round robin.
Cada partição funciona como uma fila FIFO. Como eventos com a mesma key sempre são escritos na mesma partição, isso garante a ordem de processamento. Cada evento possui um offset, que identifica sua posição dentro da partição.
Existe o offset 0 1 2 3 .. em todas as partições de todos os tópicos. Por causa desses offset separado, o kafka consegue guardar qual próxima mensagem cada consumer deve receber na ordem correta. Se um consumidor falhar, o kafka sabe de onde ele parou.
A quantidade de partições de um tópico deve ser definida no momento da criação e varia conforme o volume de eventos esperados. Quanto mais partições, maior a capacidade de processamento paralelo.
Cada partição pode ter réplicas para garantir alta disponibilidade. O fator de replicação define quantas cópias de uma partição serão mantidas em diferentes brokers. Se um broker falhar, uma réplica assume automaticamente.
A leitura ocorre sempre a partir da partição líder, enquanto as réplicas apenas sincronizam os dados.
Se um broker que contém uma partição líder falhar, uma réplica é promovida a líder automaticamente.
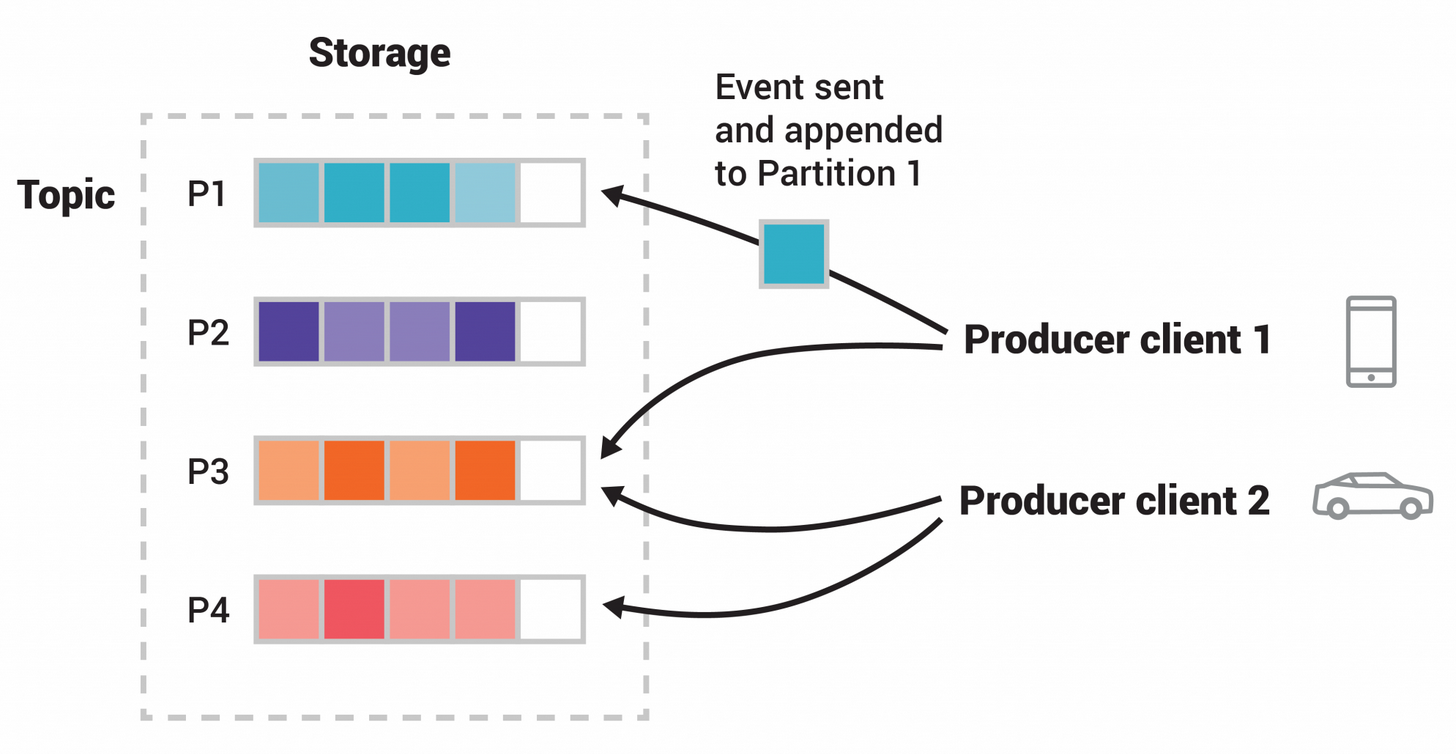
- Um tópico com 4 partições
- Produtores publicam independente um do outro
- Quadrados iguais indicam eventos com o mesmo ID por isso são gravados na mesma partição.
É possível definir um fator de replicação para cada tópico. Se o fator for 1, a partição será criada em apenas um broker e, caso esse broker falhe, os dados serão perdidos. Em um cluster de 3 nodes, por exemplo, um fator de replicação de 3 garantiria cópias em todos os brokers, aumentando a resiliência do sistema.
Para garantir disponibilidade em dados críticos, recomenda-se ao menos 2 réplicas por tópico.
Cada partição tem um líder e réplicas (followers). Sempre se lê a partir da partição líder, enquanto as réplicas apenas sincronizam dados. Se um broker com uma partição líder falhar, uma réplica é promovida a líder. Ter mais partições não acelera a leitura – nesse caso, aumentar o número de consumidores é a abordagem correta.
Segmentos de uma partição de um tópico
Cada partição é dividida em segmentos, que são arquivos físicos onde os eventos são armazenados. Essa divisão permite gerenciar a retenção de dados de maneira eficiente.
Productores e Consumidores
Os produtores são os aplicativos clientes que publicam (gravam) eventos no Kafka
Os consumidores são aqueles que assinam (leem e processam) esses eventos.
Nada impede que um produtor também seja um consumidor. Um evento pode gerar outros eventos.
No Kafka, produtores e consumidores são totalmente desacoplados e agnósticos um do outro, o que é um elemento de design chave para alcançar a alta escalabilidade pelo qual Kafka é conhecido.
Por exemplo, os produtores nunca precisam esperar pelos consumidores. O Kafka oferece garantias como processamento de eventos exatamente uma vez (exactly-once processing).
Um consumidor fica em execução contínua, ou seja, em um while true, aguardando novas mensagens.
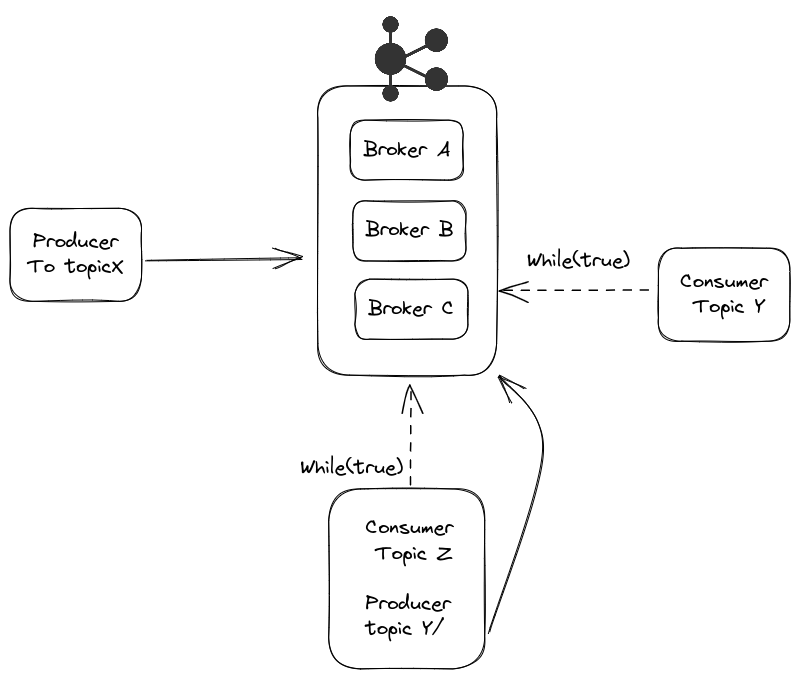
Um consumidor pode assinar múltiplos tópicos simultaneamente. Assim, um único while true pode reagir a eventos de diferentes tópicos.
Brokers no Kafka
Um consumidor pode assinar múltiplos tópicos simultaneamente. Assim, um único while true pode reagir a eventos de diferentes tópicos.
Cada broker armazena partições de tópicos em seu sistema de arquivos local. Essas partições são replicadas entre brokers para garantir alta disponibilidade e tolerância a falhas. Quando uma partição é replicada, um broker é designado como líder para essa partição, enquanto outros brokers mantêm cópias como seguidores (réplicas).
Para coordenar a sincronização entre os brokers e gerenciar a distribuição de partições, o Kafka utiliza o Apache ZooKeeper (nas versões mais antigas) ou o KRaft (Kafka Raft, nas versões mais recentes). Este mecanismo de coordenação:
- Elege líderes para partições
- Gerencia a configuração do cluster
- Monitora o status de cada broker
- Mantém o controle de quais partições estão atribuídas a quais brokers
Esta arquitetura distribuída permite que o Kafka escale horizontalmente, adicionando mais brokers ao cluster para aumentar a capacidade de processamento e armazenamento sem interromper as operações.
Boa Prática
Manipulação de Timestamps
Sempre armazene timestamps em UTC. O UTC (Tempo Universal Coordenado) elimina ambiguidades relacionadas a fusos horários e horário de verão. A responsabilidade de converter para o fuso horário local deve ficar com a camada de apresentação, que exibirá o horário apropriado ao usuário final.
Replicação de Dados
Em ambientes de produção com Apache Kafka, uma configuração padrão recomendada é utilizar um fator de replicação de 3. Isso significa que cada partição de um tópico será replicada em três brokers diferentes dentro do cluster.
Esta estratégia de replicação:
- Garante alta disponibilidade dos dados
- Proporciona tolerância a falhas (o sistema continua operando mesmo com a falha de até dois brokers)
- Balanceia desempenho e confiabilidade
A replicação ocorre no nível das partições, permitindo distribuição eficiente da carga e do armazenamento pelos brokers do clusters.