Desenvolvimento com Kafka
Além dos conceitos iniciais, para trabalhar com Kafka devemos nos aprofundar em como ele funciona. Será uma visão abrangente para que possamos entender melhor como utilizá-lo.
Etapas na Produção de Mensagens
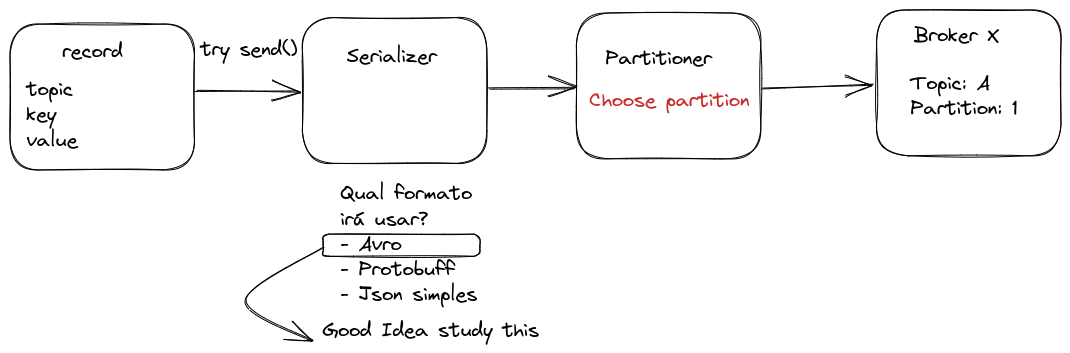
Assim que for escolhido o tópico, já tivermos um valor, definirmos se vamos ou não utilizar uma chave (opcional para garantir a ordem), será necessário que o objeto passe por um processo de serialização da mensagem que nada mais é que transformar a estrutura em uma sequência de bytes.
Em muitos sistemas de streaming, o JSON é frequentemente utilizado como formato para mensagens devido à sua simplicidade e legibilidade. No entanto, para aplicações que exigem maior controle sobre tipos de dados, o Apache Avro oferece vantagens significativas. Diferentemente do JSON convencional, o AVRO implementa um sistema de esquemas fortemente tipados que acompanha os dados serializados. Isso elimina ambiguidades comuns em JSON, onde, por exemplo, um valor booleano como true poderia ser interpretado incorretamente como uma string "true" pelo consumidor, causando comportamentos inesperados e difíceis de depurar. O Avro também proporciona melhor desempenho, compactação mais eficiente e suporta evolução de esquemas, tornando-o uma escolha superior para sistemas de produção que precisam de confiabilidade e eficiência na transmissão de dados.
Não é necessário se preocupar nesse momento com definir replicas para o tópico e quantidade de partição, etc pois isso está em um momento de criação dos tópicos e não no envio da mensagem.
É possível configurar para que o kafka crie tópicos automaticamente com uma especficação default, uma mensagem seja produzida para um tópico e ele não exista. Porém EU não considero que isso seja uma boa prática, mas depende muito do objetivo do projeto.
Garantia de entrega
Existem 3 formatos de entrega da mensagem:
-
Enviar uma mensagem que pode ser perdida no caminho.
- Ex: Localização do motorista do uber. Você pode perder uma ou outra pois a mensagem é enviada a cada 2 segundos, logo se recebermos 8 de 10 tá ótimo.
- Neste caso o
ACK=0. Envia-se a mensagem e não precisa de confirmação da entrega. - Mais velocidade ao custo perdas.
-
Enviar uma mensagem que pode ser lida mais de uma vez que não faz diferença.
- ex: Temperatura da cidade
- Neste caso o
ACK=1. Pelo menos uma confirmação espera receber, mesmo que seja mais que uma. - Velocidade moderada com garantia de entrega.
-
Garantia que recebeu somente 1 vez.
- ex: deposito ou saque bancário.
- Neste caso o
ACK=-1. O produtor envia a mensagem e aguarda confirmação de que foi replicada em todos os brokers que possuem réplicas da partição. Somente após todas as réplicas confirmarem o recebimento, a mensagem é considerada "entregue" - Garantia total ao custo de velocidade e perfomance.
Trabalhe com as opções de garantia com bom senso!
Idempotência
Existe um parâmetro chamado Idempotent que pode ser ON ou OFF no produtor para garantir exatamente uma entrega da mesma mensagem.
O kafka consegue descartar mensagens repetidas utilizando o timestamp e garantir a ordem correta.
Consumer group
O Kafka oferece um mecanismo elegante para processamento paralelo através de grupos de consumidores (consumer groups). Quando múltiplos consumidores pertencem ao mesmo grupo e leem o mesmo tópico, o Kafka automaticamente distribui as partições entre eles:
- Com um tópico de 3 partições e um grupo de 3 consumidores: cada consumidor processa exatamente 1 partição.
- Com um tópico de 3 partições e um grupo de 2 consumidores: um consumidor processa 2 partições e o outro processa 1 partição.
- Com um tópico de 2 partições e um grupo de 3 consumidores: apenas 2 consumidores ficam ativos processando 1 partição cada, enquanto o terceiro permanece em estado ocioso
A configuração de um consumidor no Kafka é notavelmente simples. Basta especificar o grupo de consumidores ao qual o consumidor pertence, e o Kafka automaticamente:
- Atribui partições apropriadas ao consumidor Gerencia a assinatura dos tópicos
- Mantém o controle dos offsets consumidos
O Kafka mantém alta disponibilidade através de rebalanceamento automático. Se um consumidor falhar, o Kafka redistribui suas partições entre os consumidores restantes e se um novo consumidor é adicionado, o Kafka reequilibra as atribuições de partições. Este processo é transparente e não requer intervenção manual.
Para obter máxima eficiência, o ideal é dimensionar o número de consumidores para corresponder ao número de partições, evitando tanto consumidores ociosos quanto sobrecarregados.
Segurança
É possível criptografar todas as mensagens em trânsito entre producer <--> Kafka <--> consumer, mas, por padrão, os dados são armazenados nas partições sem criptografia, exatamente como foram produzidos. O Kafka garante apenas a criptografia no transporte, mas as mensagens são descriptografadas ao chegar no destino.
A partir da versão 2.8.0, o Kafka introduziu o Tiered Storage e adicionou suporte à criptografia de dados em repouso (Encryption at Rest) por meio da integração com Key Management Systems (KMS), geralmente usado em clusters Kafka as a Service.
Se estiver usando um cluster Kafka self-managed, existem outras abordagens para garantir a segurança dos dados em repouso:
-
Criptografia no nível da aplicação (End-to-End Encryption): O produtor já envia a mensagem criptografada, e apenas o consumidor com a chave correta pode descriptografá-la. Como a mensagem chega criptografada, também será armazenada dessa forma. Essa é a abordagem mais segura e fácil de implementar.
-
Criptografia no nível do disco: Configurar LUKS (Linux Unified Key Setup) para criptografar o disco onde os logs do Kafka são armazenados, garantindo que os dados fiquem protegidos mesmo se o disco for acessado diretamente.
Autenticação e Autorização
O Fluxo de segurança tem duas etapas:
1️. Autenticação: O cliente (produtor/consumidor) prova sua identidade (via SASL, TLS, etc.). 2️. Autorização: O Kafka verifica o que o usuário pode fazer (via ACLs ou RBAC).
Autenticação
O Apache Kafka oferece diversos mecanismos para autenticação que servem tanto para usuários humanos quanto service accounts (contas de serviço).
- PLAIN: Nome de usuário e senha
- OAuth/OAUTHBEARER: Suporte para OAuth 2.0
- É muito comum em grandes empresas uso de SSO para usuários que pode ser feito com serviços como o Okta, AD, Keycloack, Auth0
- SSL/TLS: Autenticação baseada em certificados
- SCRAM: Autenticação com desafio-resposta
- GSSAPI: Integração com Kerberos
Para service accounts, que são utilizadas em aplicações, geralmente utiliza-se API tokens estáticos nas aplicações internas. Para uso externo podemos criar certificados específicos para service accounts de terceiros, mas depende muito do cenário, conhecimento da equipe e segurança interna do controle desses api tokens e geração dos certificados.
Autorização
A autorização (Permissões) para uma conta pode ser controlada através de ACLs (Access Control Lists) ou RBAC (Role-Based Access Control), dependendo da necessidade e da distribuição do Kafka que estamos utilizando.
Quando usar ACLs?
- Se estiver usando Apache Kafka puro (self-managed).
- Se precisar de controle de acesso granular por usuário ou serviço. -Se quiser um modelo baseado em permissões individuais em vez de funções.
Quando usar RBAC (Role-Based Access Control)?
O RBAC é um modelo de controle baseado em funções, disponível em distribuições empresariais do Kafka, como o Confluent Kafka. Em vez de definir permissões para cada usuário individualmente, você atribui funções que já possuem permissões predefinidas.
- Se estiver usando Confluent Kafka ou outra distribuição empresarial que suporte RBAC.
- Se quiser um modelo mais escalável, agrupando usuários por função.
- Se precisar integrar o Kafka com um IAM corporativo (como LDAP, Okta, Active Directory).
Com RBAC, você pode definir permissões globais para administração, produção, consumo e operações de cluster, o que facilita o gerenciamento em ambientes com muitos usuários.
Explicarei com mais detalhes mais pra frente sobre como dar essas permissões.
Compatibilidade de Dados
O Kafka, em sua essência, apenas transfere dados no formato de bytes. Ele não realiza nenhuma validação ou verificação desses dados no nível do cluster. Na verdade, o Kafka sequer sabe que tipo de informação está sendo enviada ou recebida.

Devido à natureza desacoplada do Kafka, produtores e consumidores não se comunicam diretamente. Em vez disso, a troca de informações acontece por meio dos tópicos do Kafka. No entanto, o consumidor ainda precisa saber qual é o formato dos dados enviados pelo produtor para poder desserializá-los corretamente. Agora, imagine se o produtor começasse a enviar dados inválidos ou alterasse o tipo de dado sem aviso. Isso faria com que os consumidores parem de consumir ou até quebrem se não existir um tratamento erro. Para evitar esse problema, é necessário um mecanismo que garanta um tipo de dado comum e padronizado entre produtor e consumidor.
É aqui que entra o **Schema Registry**. Ele é um serviço que funciona fora do cluster Kafka, sendo responsável pela distribuição e gestão dos schemas de dados. Ele armazena uma cópia dos esquemas em seu cache local, garantindo que tanto produtores quanto consumidores sigam a mesma estrutura.
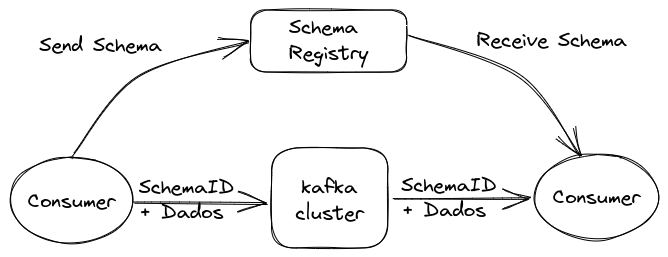
Com o Schema Registry em funcionamento, o produtor, antes de enviar os dados para o Kafka, verifica se o esquema correspondente já está registrado. Se não estiver, ele o cadastra no Schema Registry e armazena em cache. Após obter o esquema correto, o produtor serializa os dados de acordo com ele e os envia ao Kafka em formato binário, incluindo um ID único do esquema. Quando o consumidor recebe essa mensagem, ele consulta o Schema Registry para recuperar o esquema correspondente ao ID e realiza a desserialização dos dados. Se houver uma incompatibilidade, o Schema Registry retornará um erro, informando que o esquema esperado foi violado.
Que tipo de formato de serialização de dados devemos usar com Schema Registry? Alguns pontos importantes devem ser considerados ao escolher o formato adequado:
- Formato binário:
- É mais eficiente, reduzindo o uso de armazenamento.
- Evita problemas de precisão numérica comuns em formatos de texto, como JSON.
- Uso de esquemas para validar estrutura de dados.
- Permite garantir que os dados escritos estejam dentro do formato esperado, evitando incompatibilidades.
IDL (Interface Description Language) define padrões de mensagem
| Nome | Binario | IDL | DESENVOLVEDOR | OBSERVAÇÃO |
|---|---|---|---|---|
| JSON | NO | YES | Não tipado | |
| YAML | NO | NO | Não tipado | |
| XML | NO | YES | W3C | Muito Verboso |
| Kryo | NO | YES | Esoteric Software | Só funciona em JVM |
| AVRO | YES | YES | Apache | Padrão da Confluent e maior curva de aprendizagem |
| Protocol Buffer | YES | YES | Fácil de usar | |
| Thrift | YES | YES | Quase o mesmo que protocol buffer e mais difícil de usar |
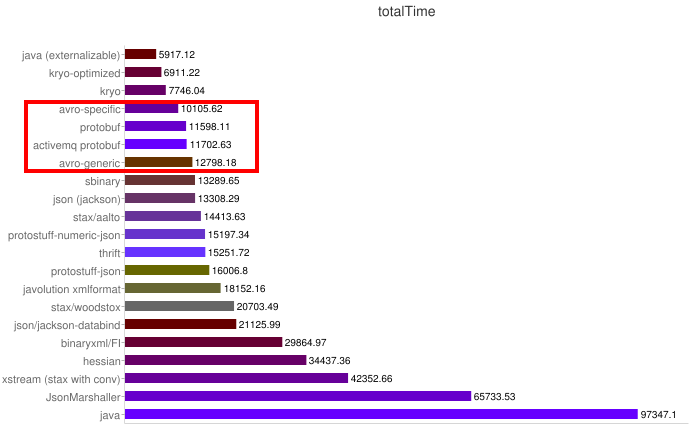
Alguns benchmarks:
Velocidade
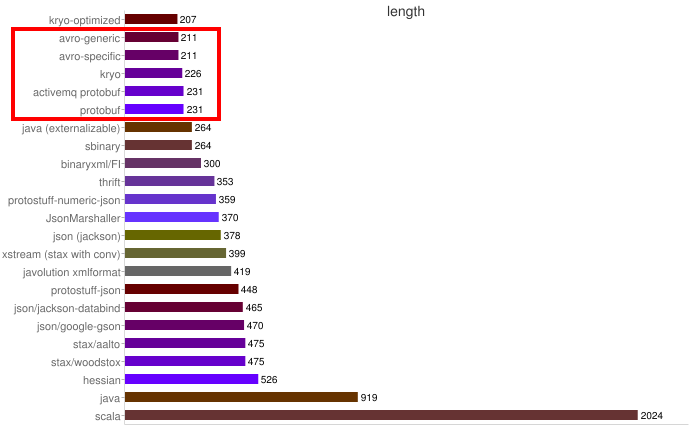
Tamanho
AVRO
Um exemplo de um schema AVRO:
{
"namespace": "pnda.entity",
"type": "record",
"name": "event",
"fields": [
{"name": "timestamp", "type": "long"},
{"name": "src", "type": "string"},
{"name": "host_ip", "type": "string"},
{"name": "rawdata", "type": "bytes"}
]
}
Características:
- Os formatos de dados são descritos escrevendo Avro Schemas , que estão em JSON.
- Os dados podem ser usados de forma genérica como Generic Records ou com código compilado.
- Os dados salvos em arquivos ou transmitidos por uma rede geralmente contêm o próprio esquema.
Prós
- Formato binário eficiente que reduz o tamanho dos registros.
- Os esquemas do leitor e do gravador são conhecidos, permitindo grandes alterações no formato dos dados.
- Linguagem muito expressiva para escrever esquemas.
- Nenhuma recompilação é necessária para suportar novos formatos de dados.
Contras
- O formato Avro Schema é complexo e requer estudo para aprender. Procure no site que em algum momento eu falarei sobre isso.
- As bibliotecas Avro para serialização e desserialização são mais complexas de aprender.
Útil quando:
- É muito importante minimizar o tamanho dos dados.
- Os formatos de dados estão em constante evolução ou até mesmo algo que os usuários podem usar.
- São necessárias soluções genéricas para problemas como armazenamento de dados ou sistemas de consulta de dados.
Protocol Buffer
Caracteristicas:
- Os formatos de dados são descritos escrevendo arquivos proto em um formato personalizado.
- Um compilador protobuf gera código na linguagem de programação escolhida.
- Você cria, serializa e desserializa seus dados usando o código gerado.
Prós:
- Formato binário muito eficiente que reduz bytes.
- Representação JSON padrão.
- Código gerado fortemente tipado para acelerar o desenvolvimento.
Contras:
- Requer recompilação quando os formatos mudam.
- É necessária uma disciplina rigorosa para manter a compatibilidade com versões anteriores quando os formatos mudam.
Útil quando:
- É muito importante minimizar o tamanho dos dados
- Os formatos de dados não mudam com muita frequência.
Eu particulamente gosto mais do AVRO. Apesar de dar mais trabalho, não é necessário um compilador.