Ecossistema Kafka
Kafka Connectors
O Kafka Connect é um framework para integração de dados que facilita a movimentação de informações entre o Kafka e sistemas externos, como bancos de dados, serviços de armazenamento e outras fontes de dados. Ele simplifica a importação e exportação de dados sem a necessidade de escrever código personalizado para consumir ou produzir mensagens.
O Kafka Connect usa conectores para se comunicar com diferentes sistemas. Existem dois tipos principais:
-
Source Connector (Conector de Origem) → Captura dados de fontes externas (bancos de dados, APIs, sistemas de mensageria) e os publica em tópicos do Kafka.
-
Sink Connector (Conector de Destino) → Consome dados de tópicos do Kafka e os envia para destinos como bancos de dados, sistemas de análise e armazenamento distribuído.
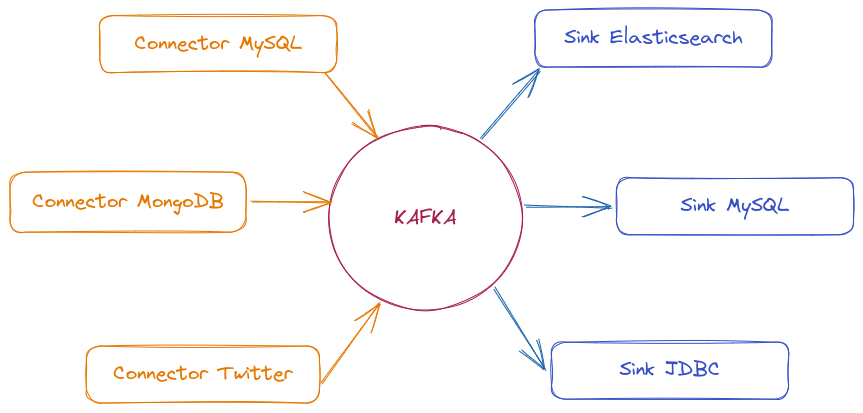
Há muitos conectores disponíveis para mover dados entre Kafka e outros sistemas de dados populares, como S3, JDBC, Couchbase, S3, Golden Gate, Cassandra, MongoDB, Elasticsearch, Hadoop e muitos mais.
Vantagens:
- Facilidade de integração → Permite conectar diferentes sistemas com mínima configuração.
- Escalável e tolerante a falhas → Pode rodar como um processo único ou em modo distribuído.
- Interface REST → Permite gerenciar conectores via API REST sem necessidade de mexer no código.
- Gerenciamento automático de offsets → Kafka Connect gerencia os deslocamentos automaticamente, evitando problemas de reprocessamento de mensagens.
- Processamento de dados em lote e streaming → Pode lidar tanto com fluxos contínuos quanto com cargas em lote.
O Kafka Connect não faz parte do cluster Kafka . Ele é um serviço separado que facilita a integração de dados, mas roda independentemente do Kafka.
Nem todos os conectores são gratuitos, Alguns são open-source, mas outros são mantidos por empresas e exigem licenciamento.
Podemos conferir esta lista para encontrar o que precisamos.
Kafka Rest Proxy
O Kafka REST Proxy é um serviço que permite interagir com o Kafka por meio de uma API REST, facilitando a produção e o consumo de mensagens sem a necessidade de utilizar bibliotecas ou drivers específicos do Kafka.
Quando usar isso?
- Se a sua aplicação não possui um cliente Kafka compatível, o REST Proxy permite enviar e consumir mensagens via HTTP.
- Ideal para sistemas que já utilizam APIs REST e não querem adicionar dependências específicas do Kafka.
- Quando não há necessidade de gerenciar um Producer/Consumer manualmente dentro do código.
Em vez de usar uma biblioteca Kafka, você pode enviar mensagens para um tópico simplesmente fazendo uma requisição HTTP:
curl -X POST "http://localhost:8082/topics/meu-topico" \
-H "Content-Type: application/vnd.kafka.json.v2+json" \
--data '{"records":[{"value":{"id":1, "mensagem":"Olá DevSecOps!"}}]}'
## E para consumir
curl -X GET "http://localhost:8082/consumers/meu-grupo/instances/minha-instancia/records"
Vantagens:
- Não precisa gerenciar conexões ou configurar consumidores/produtores complexos.
- Funciona com qualquer linguagem que suporte requisições HTTP. -É mais fácil testar e enviar mensagens manualmente via curl ou Postman.
Desvantagens
- Maior latência pois as requisições HTTP têm mais overhead do que conexões nativas Kafka.
- Não permite ajustes avançados como particionamento manual e configurações específicas de consumidores.
- Pode não ser ideal para sistemas de alto throughput.
Kafka Streams
Kafka Streams é uma poderosa biblioteca Java para processamento e transformação de dados em tempo real.
Para utilizar Kafka Streams, é necessário um consumer desenvolvido em Java. Ele consome os dados, aplica as transformações desejadas e os republica no formato adequado.
O Kafka Streams atua simultaneamente como consumer e producer.
- Garantia de entrega "Exactly Once", evitando mensagens duplicadas.
- Escalável e tolerante a falhas.
- Capacidade de agregação: permite operações como cálculos de média, soma e contagem.
- Processamento em tempo real
KSQL (Kafka SQL)
KSQL é uma linguagem baseada em SQL para processar e consultar dados diretamente nos tópicos do Kafka, sem a necessidade de escrever código Java ou outra linguagem de programação.
- Consultas em tempo real permite filtrar, transformar e agregar dados diretamente nos tópicos do Kafka.
- Evita a necessidade de desenvolver aplicações customizadas para processar mensagens.
- Pode manter o estado de consultas e agregações sem necessidade de bancos de dados externos.
- Funciona bem com formatos como AVRO, JSON e Protobuf, garantindo a consistência dos dados.
KSQL trata os tópicos do Kafka como tabelas ou streams contínuas de dados, permitindo realizar operações como:
Por exemplo se fôssemos filtrar o tópico de pedidos. Imagine que temos as 3 mensagens abaixo no tópico:
{"id": 1, "cliente": "João", "valor": 90}
{"id": 2, "cliente": "Maria", "valor": 150}
{"id": 3, "cliente": "Carlos", "valor": 200}
Executando o comando:
SELECT * FROM pedidos WHERE valor > 100;
Teríamos a seguinte saída:
{"id": 2, "cliente": "Maria", "valor": 150}
{"id": 3, "cliente": "Carlos", "valor": 200}
Se quiser persistir esse resultado em um novo tópico filtrado, poderia criar uma stream derivada:
CREATE STREAM pedidos_filtrados AS
SELECT * FROM pedidos WHERE valor > 100;
Isso cria um novo tópico pedidos_filtrados onde só entram os eventos que passam na regra.
KSQL é poderoso para análises e transformações de dados sem precisar de código Java ou outra linguagem.
Outros exemplos:
SELECT categoria, COUNT(*) FROM vendas GROUP BY categoria;
SELECT pedidos.id, clientes.nome FROM pedidos JOIN clientes ON pedidos.cliente_id = clientes.id;
Isso torna o KSQL uma ferramenta poderosa para análise de dados em tempo real, enriquecimento de eventos e criação de pipelines de dados sem precisar escrever código complexo.
Se o conteúdo da mensagem for criptografado, não seria possível utilizar o KSQL.
Cruise Control (Balanceamento Inteligente de Partições)
Um cluster típico pode ficar carregado de forma desigual ao longo do tempo. Partições que lidam com grandes quantidades de tráfego de mensagens podem não ser distribuídas uniformemente entre os brokers disponíveis. Para rebalancear o cluster, os administradores devem monitorar a carga nos brokers e reatribuir manualmente partições ocupadas a brokers com capacidade extra.
O Cruise Control é uma ferramenta desenvolvida pelo LinkedIn para gerenciar automaticamente a carga e o balanceamento de partições no Apache Kafka. Ele permite otimizar a distribuição de dados entre os brokers, evitando gargalos e garantindo um desempenho mais estável do cluster.
Ele constrói um modelo de carga de trabalho de utilização de recursos para o cluster — com base na carga de CPU, disco e rede — e gera propostas de otimização (que você pode aprovar ou rejeitar) para atribuições de partição mais balanceadas. Um conjunto de metas de otimização configuráveis é usado para calcular essas propostas.
Podemos ser bem específicos ao gerar propostas de otimização.
- O modo Full rebalanceia partições em todos os brokers.
- Podemos fazer rebalanceamento sempre que adicionarmos ou removermos um broker para acomodar as alterações.
Ao aprovar uma proposta de otimização o Cruise Control irá aplicá-la no cluster.
Principais Funcionalidades do Cruise Control:
- Analisa constantemente o consumo de CPU, memória, disco e rede nos brokers.
- Redistribui partições entre os brokers para otimizar a carga.
- Permite testar novas distribuições antes de aplicá-las.
- Você pode executar ajustes sob demanda ou deixar o Cruise Control fazer isso de forma autônoma.
- Se um broker falhar ou for removido, o Cruise Control redistribui as partições sem impacto significativo.
- Interface para integração com outros sistemas, permitindo automação.
O Cruise Control coleta métricas de uso dos brokers e utiliza algoritmos de otimização para tomar decisões sobre o balanceamento de partições. Ele trabalha com três componentes principais:
1️. Monitor de Métricas → Coleta dados dos brokers via JMX e Kafka Metrics Reporter. 2️. Analisador de Carga → Processa as métricas coletadas e identifica padrões de uso. 3️. Executor de Ações → Realoca partições com base nas análises para manter um balanceamento eficiente.
A comunicação com o Cruise Control é feita por meio de APIs REST, permitindo que você visualize o estado do cluster e execute rebalanceamentos sob demanda.