Requests
Una solicitud a un path está asociada a la acción que ejecutará, que será un Operation Object. Solo para recordar, son los métodos que tenemos en OpenAPI, pero hasta ahora solo usamos Get, aunque para un mismo path tenemos varios métodos posibles.
path:
/products: # Path Object
# Todos estos son path items objects
$ref: "" # Espera un string
summary: ""
description: ""
get: {} # Espera un Operation Object aquí dentro #<<<<<<
put: {} # Espera un Operation Object aquí dentro
post: {} # Espera un Operation Object aquí dentro
delete: {} # Espera un Operation Object aquí dentro
options: {} # Espera un Operation Object aquí dentro
head: {} # Espera un Operation Object aquí dentro
patch: {} # Espera un Operation Object aquí dentro
trace: {} # Espera un Operation Object aquí dentro
servers: {} # Espera un server object aquí dentro
parameters: {} # Espera un Parameter Reference aquí dentro
En el método get que definirá un operation object solo utilizamos parameters y responses hasta ahora.
path:
#...
/v1/customers/{Id}:
get: # Operation Object para el path anterior.
parameters: # <<<
- $ref: '#/components/parameters/Id'
responses: # <<<
'200':
description: Found Customer
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
Para un mismo path podemos definir un operation object para cada método, pero no es posible definir dos gets diferentes. Un get puede generar varias responses.
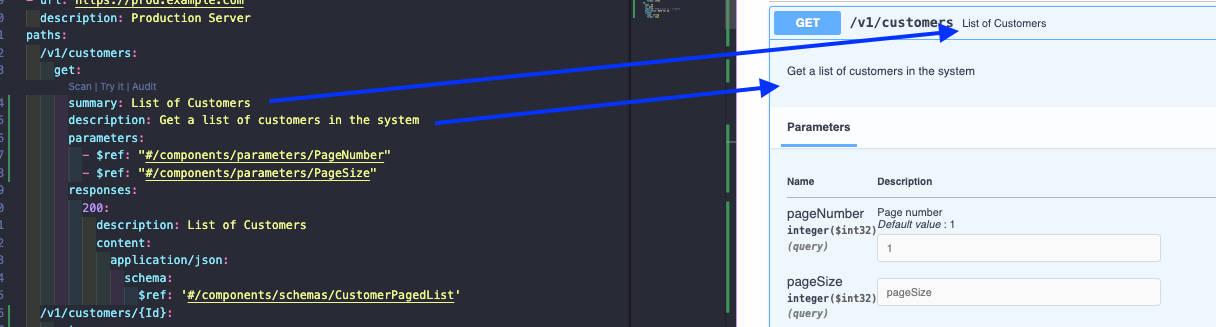
Summary y Description
Siempre necesitamos pensar en quién utilizará nuestra API, por lo que es buena práctica aclarar al máximo cada cosa.
En todos los operations objects tenemos summary y description que vale la pena especificar para que se muestren en la API.
Sabiendo que el summary tiene un espacio corto, sé directo y más detallista en description.
Tags
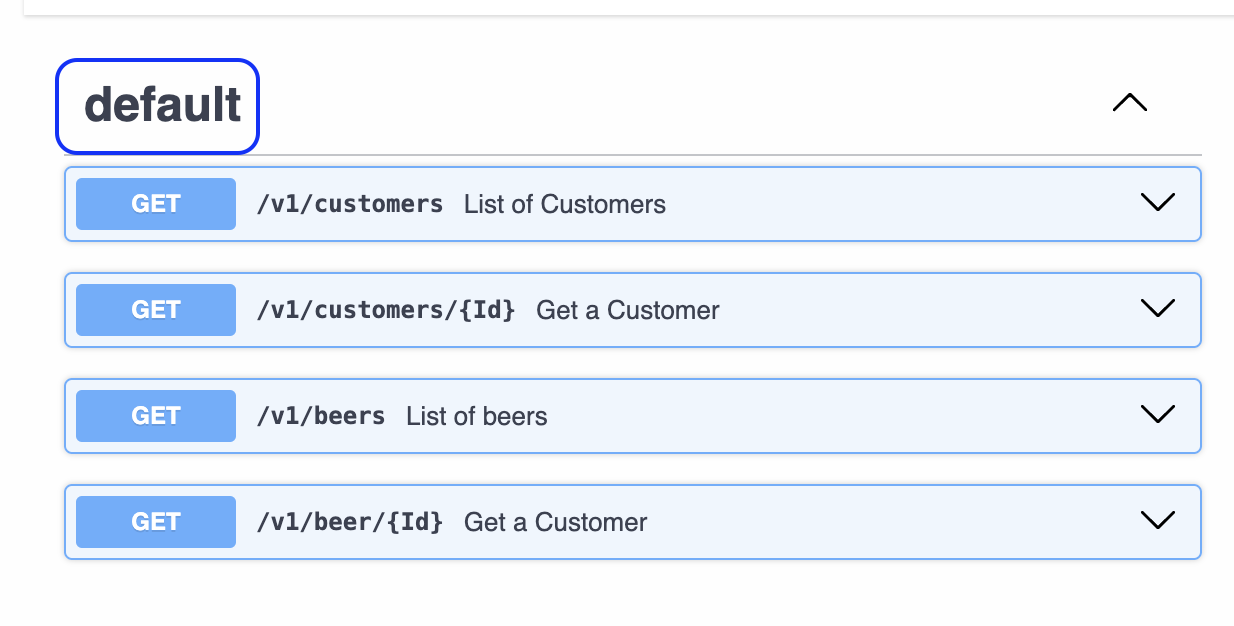
No es posible crear tags globalmente para todos los métodos dentro de un path. Es necesario crear las tags dentro de cada uno de los métodos. Podemos tener una lista de tags.
Cuando no definimos una tag, todos quedan en default.
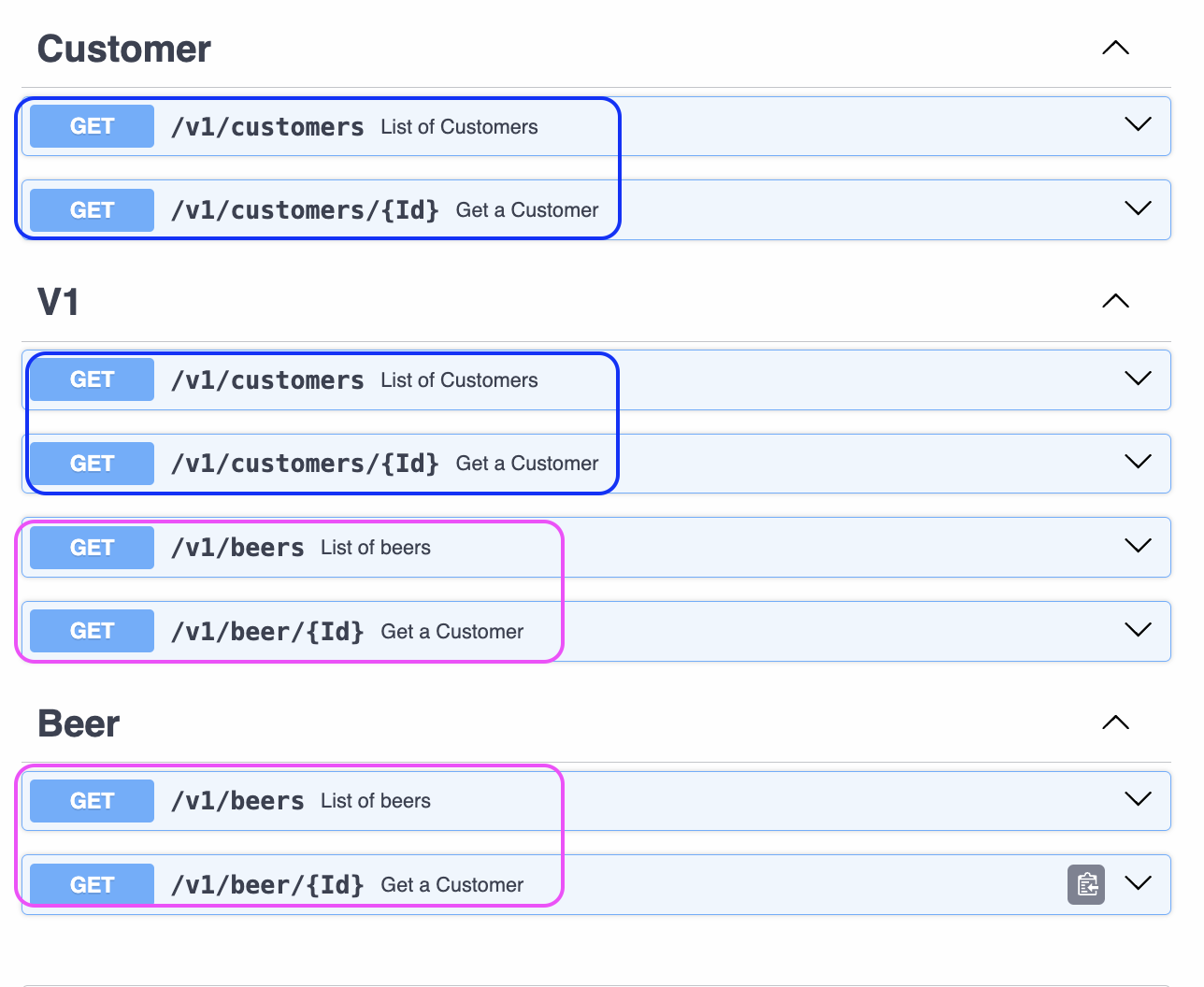
Una vez que aparece un nombre de tag se hará una agrupación visual. Si una operación participa de dos tags aparecerá en dos grupos aunque sea necesario repetir. De esta forma es más flexible que declarar tags globalmente.
openapi: 3.0.2
info:
# ...
paths:
/v1/customers:
get:
summary: List of Customers
description: Get a list of customers in the system
tags:
- Customer
- V1
# ...
/v1/customers/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
tags:
- Customer
- V1
# ...
/v1/beers:
get:
summary: List of beers
description: Get a list of beers in the system
tags:
- Beer
- V1
# ...
/v1/beer/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
tags:
- Beer
- V1
# ...
OperationId (opcional)
En OpenAPI, el operationId es un identificador único para una operación. Se usa para diferenciar cada operación en un endpoint y, a menudo, es utilizado por herramientas generadoras de código para crear funciones o métodos correspondientes a esa operación. Sirve principalmente como puente entre la especificación OpenAPI y el código generado o herramientas que consumen la API, como SDKs o sistemas de integración.
- Generación de Código: Herramientas como Swagger Codegen o OpenAPI Generator utilizan el operationId para nombrar funciones/métodos en los SDKs generados.
- Si operationId es getUserById, el código generado puede contener un método como getUserById().
- Facilidad de Navegación: Permite que APIs grandes tengan una referencia única para cada operación, facilitando el mapeo entre la especificación y el código.
- Garantizar que cada operación sea única evita conflictos en implementaciones y documentaciones.
- La nomenclatura debe reflejar la acción que la operación realiza.
- Sigue un estándar para nombrar operationId, como verboRecurso (ej.: createUser, deleteOrder).
Aunque el operationId es opcional, añadirlo es altamente recomendado, especialmente para proyectos que utilizan herramientas de documentación o generación de código.
Si no estás utilizando herramientas que dependen directamente del operationId, no hay impacto técnico inmediato en el funcionamiento de la API. La API seguirá funcionando normalmente, siempre que implementes correctamente los endpoints y el enrutamiento en el backend.
-
Si el operationId en la especificación no corresponde a la forma en que el endpoint es tratado en el código, puede causar confusión para otros desarrolladores o equipos que consultan la documentación. Alguien mirando la especificación puede esperar que exista un método llamado getUserById, pero en el código lo trataste como fetchUser.
-
Si en el futuro decides usar generación de código o crear SDKs basados en la API, la inconsistencia entre el operationId y el código puede generar métodos mal nombrados o causar necesidad de retrabajo.
-
Algunas herramientas de documentación o prueba pueden usar el operationId para identificar operaciones únicamente. Si no corresponde a la lógica del código, puede dificultar la automatización.
Vamos a definir nuestros operationsID para después generar código con esta API.
openapi: 3.0.2
info:
# ...
paths:
/v1/customers:
get:
summary: List of Customers
description: Get a list of customers in the system
operationId: listCustomersV1 #<<<<
tags:
- Customer
# ...
/v1/customers/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
operationId: getCustomerById #<<<<
tags:
- Customer
# ...
/v1/beers:
get:
summary: List of beers
description: Get a list of beers in the system
operationId: listBeers #<<<<
tags:
- Beer
# ...
/v1/beer/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
operationId: getBeerById #<<<<
tags:
- Beer
# ...
# ...
Request Body
Técnicamente lo que tenemos disponible en cada operation object es esto.
- tags
- description
- externalDocs (También puede ser usado a nivel de la api)
# A nivel de la api
externalDocs:
description: Learn more about this API
url: https://example.com/docs/api
path:
/v1/user
get:
# Nivel de método
ExternalDocs:
description: Learn more about this endpoint
url: https://example.com/docs/api/v1/user
- operationId
- parameters
- requestBody (Nuestro próximo aprendizaje)
- responses
- callbacks
- deprecate
- security
- servers
El método HTTP GET puede tener un body pero esta práctica es altamente desaconsejada e inusual, así como HEAD y OPTIONS. Revisa la tabla de métodos y verás que estos métodos sirven solo para recuperar datos y no para alterar datos.
Muchas implementaciones de servidores, proxies y bibliotecas HTTP ignoran o rechazan un body en solicitudes GET.
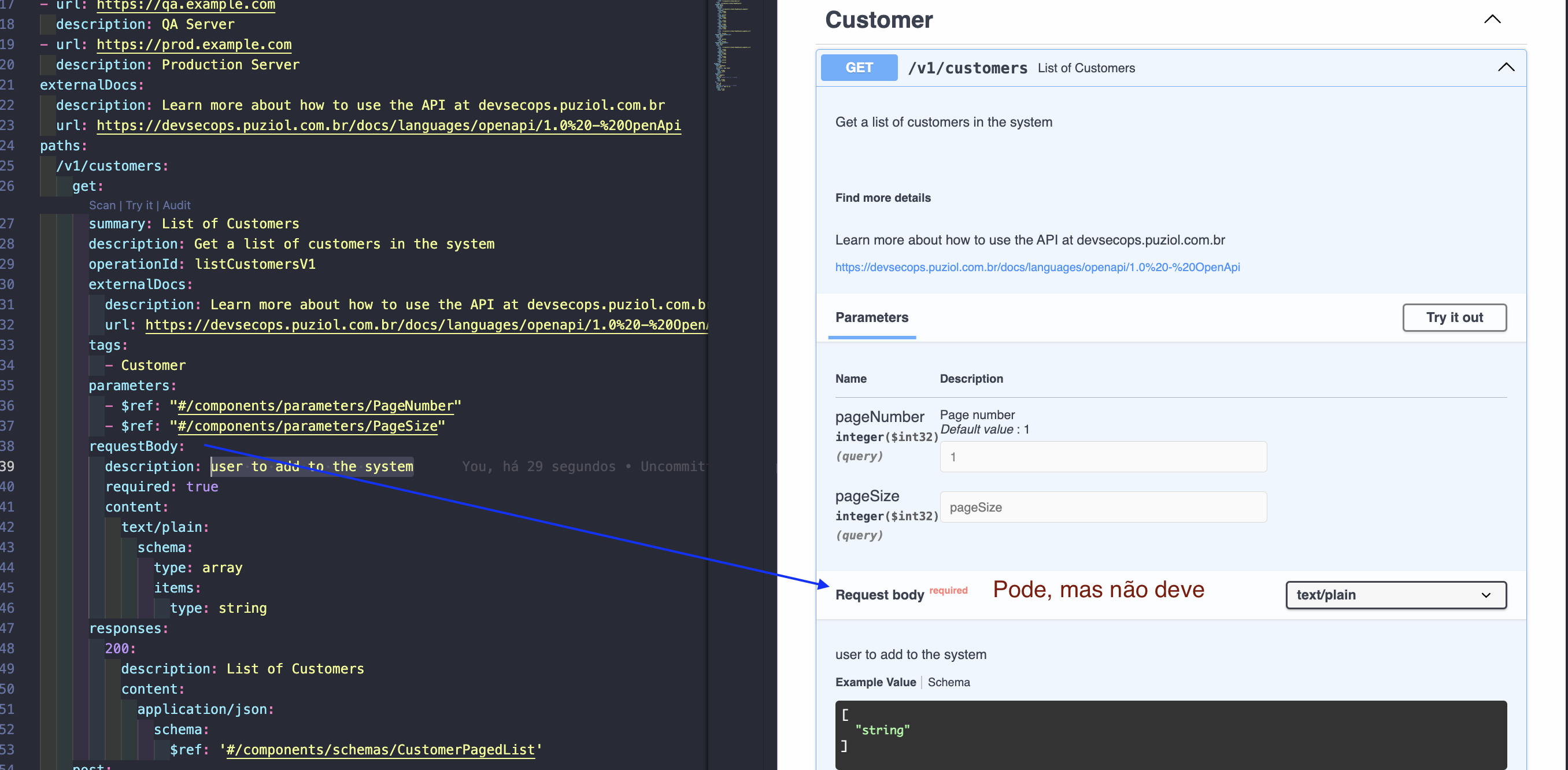
Pero vamos a hacer una validación fuera de este plugin de vscode para probar.
# Vamos a usar la herramienta openapi-generator solo para probar rápidamente lo que dije anteriormente.
openapi-generator validate -i infoapi.yaml
Validating spec (infoapi.yaml)
No validation issues detected. # Pasa pero no es para usar
Creando un POST
Ahora vamos a montar un método POST que usará un requestBody.
paths:
/v1/customers:
get:
#....
post:
summary: New Customer
description: Create a new customer
operationId: newCustomer
tags:
- Customer
requestBody: # El Body que necesitaremos.
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
201:
description: New Customer Created
# Podríamos retornar algo, pero este es el caso más simple.
Volviendo a los Códigos de Estado HTTP, 201 significa que un recurso fue creado en el servidor.
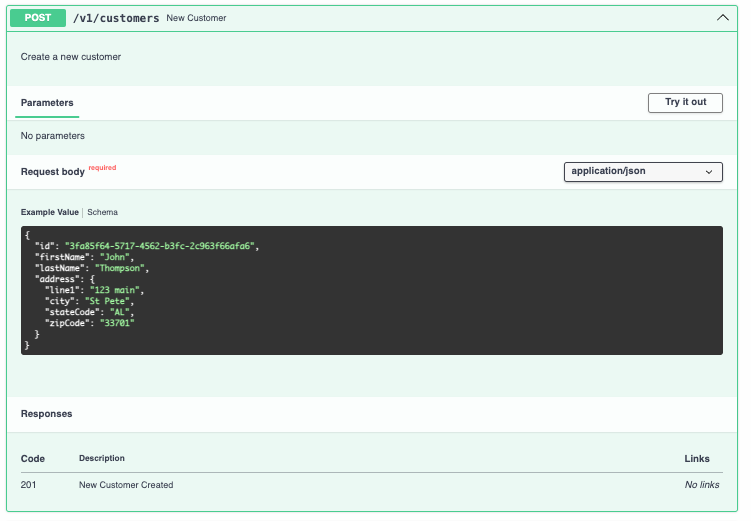
En este caso no estamos esperando ningún parámetro, estamos esperando directamente el json con todo lo que necesitamos dentro para crear un customer.
Es completamente normal que un método POST use tanto el requestBody como parámetros (query o path). Cada elemento tiene un propósito diferente y su utilización depende del diseño de la API. El requestBody se usa para enviar datos más complejos en el cuerpo de la solicitud y generalmente se usa para crear o actualizar recursos. Ejemplos: JSON, XML, Yaml, u otros formatos estructurados.
La situación que está ocurriendo anteriormente es que el id está siendo pasado dentro del objeto customer, pero quien debería crear el Id es el sistema, pero ya vamos a resolver eso.
Otra cosa que debemos tener en cuenta es que RESTful es un estándar comúnmente aceptado. Seguir los estándares depende de tu voluntad. La idea es seguir ¿no?
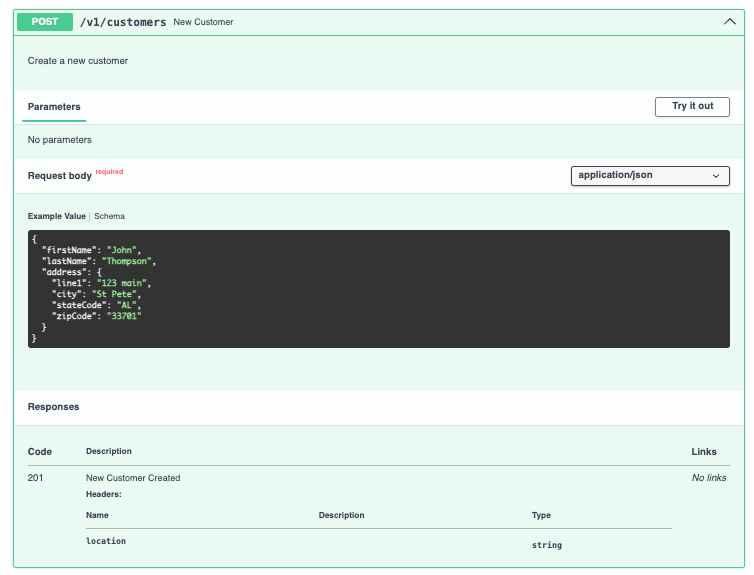
Es estándar devolver la ubicación del recurso en el encabezado cuando se crea en el servidor, entonces vamos a implementarlo.
post:
summary: New Customer
description: Create a new customer
operationId: newCustomer
tags:
- Customer
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
201:
description: New Customer Created
##### Devolución en el encabezado
headers:
location:
schema:
description: Location of the created resource
type: string
format: uri
example: http://example.com/v1/customers/{assignedIdValue}
# otro:
# schema:
# description:
# type: string
#####
Cada status puede tener:
- description (string) REQUIRED
- headers (header object)
- content (Contenido si es necesario devolver)
- links
Una cosa interesante es que estamos hablando de response, pero el request también puede y generalmente tiene headers. Un ejemplo es Content-Type (application/json) y el Bearer Token (authentication).
Podemos crear headers personalizados como vimos anteriormente en el caso del location.
Para resolver el problema del Id podemos trabajar con readOnly y definir que este campo no se usa en el request.
components:
schemas:
Customer:
type: object
properties:
id:
type: string
format: uuid
readOnly: true #<<<<
firstName:
maxLength: 100
minLength: 2
type: string
example: John
lastName:
maxLength: 100
minLength: 2
type: string
example: Thompson
address:
$ref: '#/components/schemas/Address'
description: customer object
Usando este mismo schema en el request (post) y en el response (get) vemos la omisión del id cuando es un request.
|  |
| --------- | --------- |
|
| --------- | --------- |
El writeOnly hace exactamente lo inverso. Por ejemplo, un password que esperamos en el request y no devolvemos en el response.
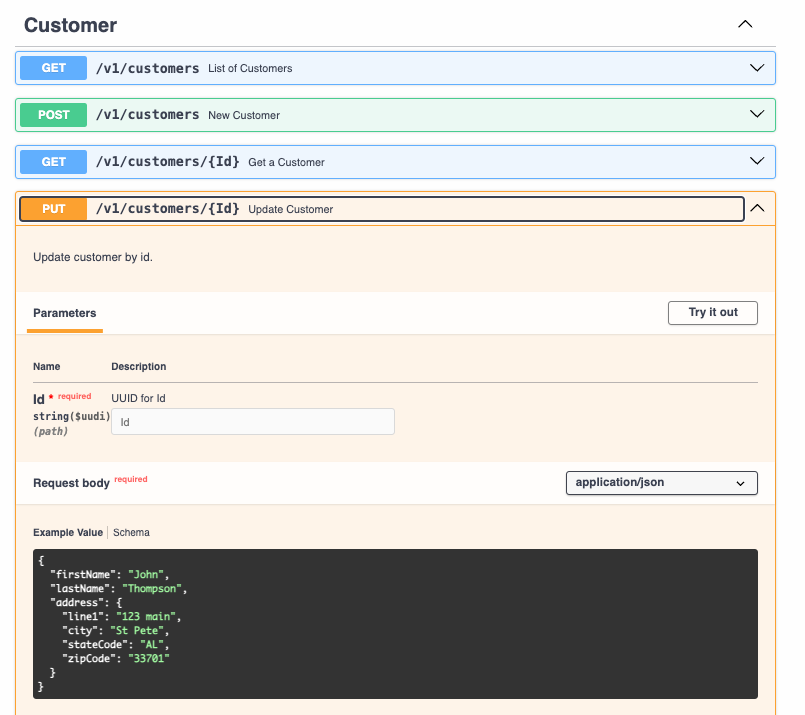
Creando un PUT
Básicamente el PUT hará una actualización de un recurso existente. Esta vez vamos a utilizar el path /v1/customers/{Id} porque queremos pasar el Id del customer que será actualizado.
info:
#...
path:
#...
/v1/customers/{Id}:
get:
#...
put:
summary: Update Customer
description: Update customer by id.
tags:
- Customer
operationId: UpdateCustomerById
parameters:
# Este parámetro está en components y es del tipo path
# Fue usado en ejemplos anteriores
- $ref: '#/components/parameters/Id'
requestBody:
required: true
content:
application/json:
schema:
# Recuerda que es readOnly para Id por eso estamos pasando en el path
$ref: '#/components/schemas/Customer'
responses:
204: # No Content: Solicitud exitosa, pero sin contenido para retornar.
description: Customer Updated
#...
#...
Creando un DELETE
Esta operación será prácticamente la misma del PUT, la diferencia es que la función que se ejecutará en el servidor será otra.
Una cosa importante es que estamos retornando 200 porque se espera que si un recurso es eliminado no habría nada para retornar.
path:
#...
/v1/customers/{Id}:
get:
#...
put:
#...
delete:
summary: Delete Customer
description: Delete customer by id.
tags:
- Customer
operationId: deleteCustomerById
parameters:
- $ref: '#/components/parameters/Id'
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
200:
description: Customer Deleted
#...
#...

Utilizando Varios Status
No siempre tendremos el status de éxito. Pedir eliminar o actualizar un recurso por un id no existente resultará en fallo.
El openapi sirve como documentación y a partir de ella podemos generar código que respete esa documentación, pero quien de hecho implementa los valores de retorno es quien desarrolló el endpoint.
Vamos a imaginar este escenario.
paths:
/users:
get:
responses:
"404":
description: User not found
¿Será esta la descripción que volverá en el mensaje? Debería serlo en caso de que quien implementó la función respete la documentación del openapi. Sin embargo, si quien implementó hubiera hecho esto...
app.get('/users', (req, res) => {
const user = findUser(req.query.id);
if (!user) {
res.status(404).json({ error: 'Usuario no encontrado en el sistema' });
}
});
Para el error 404 vendría el mensaje Usuario no encontrado en el sistema.
Los status son los valores esperados que la función retorne y el tipo de contenido, header, etc. Es bueno aclarar esto para entender que OpenAPI no procesa nada, pero sirve como referencia y a partir de esta referencia creamos estándares tanto para quien va a desarrollar como para quien va a consumir.
Vamos a colocar nuevos status que podrían existir que ya vamos ejercitando otros tipos de status.
Los posibles status aparecerán en la documentación.

openapi: 3.0.2
info:
###...
paths:
/v1/customers:
get:
###...
responses:
200:
description: List of Customers
content:
application/json:
schema:
$ref: '#/components/schemas/CustomerPagedList'
# No necesitamos más aquí por ahora porque entregará una lista vacía o no
post:
###...
responses:
201:
description: New Customer Created
headers:
location:
schema:
description: Location of the created resource
type: string
format: uri
400:
description: Bad Request
# El schema no fue respetado
409:
description: Conflict
# Está queriendo incluir un usuario que ya existe
/v1/customers/{Id}:
get:
###...
responses:
200:
description: Found Customer
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
404:
description: Not found
put:
###...
responses:
204:
description: Customer Updated
400:
description: Bad Request
404:
description: Not found
409:
description: Conflict
delete:
###...
responses:
200:
description: Customer Deleted
404:
# Caso el id pasado no sea encontrado
description: Not found
###..
components:
###...
###...