Protocolo HTTP (HyperText Transfer Protocol)
HTTP (HyperText Transfer Protocol) es el protocolo que define cómo se formatean y transmiten los mensajes entre clientes y servidores en la web. Es la base para la comunicación de datos en Internet y funciona sobre el modelo de request-response. HTTP fue creado por Tim Berners-Lee en 1989. La solución propuesta por Berners-Lee fue un sistema de hipertexto distribuido globalmente, que llamó World Wide Web. HTTP se desarrolló como un protocolo de comunicación para permitir la transferencia de documentos de hipertexto entre servidores y clientes en la Web. La primera especificación de HTTP, conocida como HTTP/0.9, fue un protocolo simple que permitía solo la solicitud y respuesta de documentos de hipertexto. En 1996, se lanzó la versión HTTP/1.0, introduciendo mejoras significativas en relación a HTTP/0.9.
Basado en texto: Los mensajes se envían en texto plano, lo que facilita la comprensión y depuración.Modelo cliente-servidor: El cliente (generalmente un navegador o una aplicación) envía una solicitud al servidor, que responde con los datos solicitados (ej.: páginas HTML, imágenes, etc.).stateless (sin estado): Cada solicitud es independiente y el servidor no mantiene información sobre solicitudes anteriores. Si es necesario mantener estado, se usan cookies, sesiones u otras técnicas.Protocolo de la capa de aplicación del modelo OSI. HTTP generalmente usa TCP como transporte, pero puede combinarse con otros.Extensible: Soporta encabezados personalizados, métodos adicionales y otras extensiones.
Un poco de la evolución de HTTP solo para conocimiento rápido.
-
De HTTP/1.0 a HTTP/1.1: 1.0 mejoró la versión 0.9 permitiendo la transferencia de diversos tipos de contenido, como imágenes y videos, además de texto. Además, introdujo la capacidad de enviar información adicional en forma de encabezados de metadatos, mejorando la comunicación entre cliente y servidor, pero tenía un problema de rendimiento. La versión 1.1 fue lanzada en 1997 introduciendo la conexión persistente, que permitía múltiples solicitudes y respuestas en la misma conexión, disminuyendo la latencia y mejorando el rendimiento. -
HTTP/2.0 (lanzado en 2015): Enfocada principalmente en mejoras de rendimiento y eficiencia, como la multiplexación de flujos y la compresión de encabezados, pero también ayudó en la adopción de conexiones seguras a través de TLS (Transport Security Layer). -
HTTP/3.0- Fue formalmente estandarizado y lanzado en junio de 2022. Hoy, en 2024 la mayoría de navegadores web ya ofrecen soporte para HTTP/3. El principal cambio es la sustitución del protocolo TCP en la capa de transporte por el protocolo QUIC (Quick UDP Internet Connections). QUIC no permite más la transmisión de texto puro, solamente cifrados, siendo necesario el uso de TLS 1.3 forzando el uso dehttps://.
Para entender mejor QUIC es necesario un conocimiento sobre los protocolos de transporte TCP y UDP. TCP envía un paquete de datos y también recibe la confirmación de la recepción de esos paquetes mientras el protocolo UDP simplemente hace el envío sin preocuparse si la otra parte recibió o no y en caso de error finge que nada pasó. TCP se enfoca en la confiabilidad e integridad mientras UDP en la velocidad y la latencia.
Cuando enviamos archivos usamos TCP para garantizar la integridad de los archivos, pues no queremos un archivo al que le falten pedazos.
Cuando queremos velocidad y la latencia es un factor, como streaming de videos, voip, etc, terminamos usando UDP y aceptando algunas pérdidas para mejorar la calidad de la experiencia y fluidez.
QUIC, que está basado en el protocolo UDP para garantizar la latencia, pero promete garantizar la confiabilidad y la seguridad de las conexiones. Añade una capa extra a UDP con funcionalidades como retransmisión de paquetes, control de congestión y otras características de TCP, pero manteniendo la velocidad. Con esto, un paquete enviado a través de QUIC será siempre recibido por el otro extremo, tarde o temprano.
Un ejemplo del flujo de QUIC.
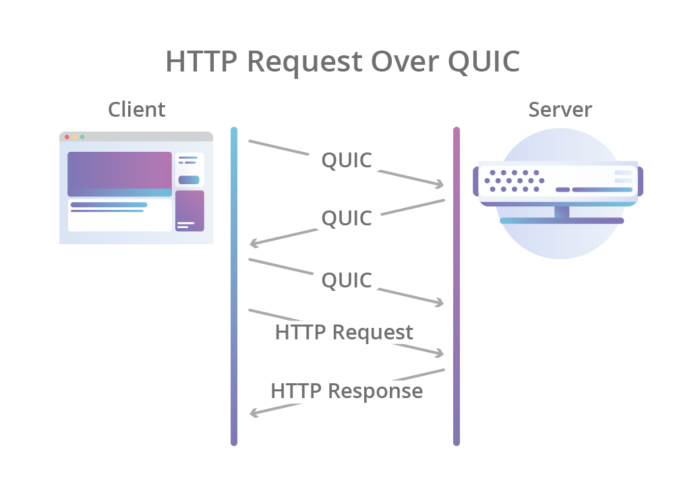
Request vs Response
Vamos a mostrar una estructura de request y otra de response para entender cómo funciona.
Estructura de una Solicitud HTTP
-
Línea de solicitud: Contiene el método HTTP, el recurso solicitado y la versión del protocolo.
GET /index.html HTTP/1.1 -
Encabezados: Información adicional, como el tipo de contenido esperado o datos de autenticación.
Host: www.example.com
User-Agent: Mozilla/5.0 -
Cuerpo de la solicitud: Usado en métodos como POST o PUT para enviar datos (ej.: formularios, JSON).
Estructura de una Respuesta HTTP
-
Línea de estado: Contiene la versión del protocolo, el código de estado y una descripción textual. 200 es éxito, y hablaremos más sobre estos status posteriormente.
HTTP/1.1 200 OK -
Encabezados: Información como tipo de contenido, tamaño de la respuesta o configuraciones de cache.
Content-Type: text/html
Content-Length: 123 -
Cuerpo de la respuesta: El contenido solicitado (ej.: una página HTML, imagen o datos JSON).
Métodos HTTP
Vimos arriba el GET, pero existen otros métodos entonces vamos a conocer un poco de ellos.
Los métodos se usan para definir una acción sobre un recurso. La mayoría de las veces cuando estamos navegando en las páginas de la web estamos usando el método GET.
-
GET: Recupera datos de un recurso sin modificar el servidor.GET /products -
POST: Envía datos al servidor para crear un recurso.POST /users con datos { "name": "Alice" } -
PUT: Actualiza o crea un recurso en el servidor.PUT /users/1 -
DELETE: Elimina un recurso en el servidor.DELETE /users/1 -
Menos usados pero soportados
HEAD: Igual al GET, pero solo retorna los encabezados.OPTIONS: Retorna métodos disponibles para un recurso.PATCH: Actualiza parcialmente un recurso.TRACE: Usado para realizar un loopback de diagnóstico, es decir, permite que el cliente (como el navegador o una herramienta) reciba de vuelta lo que fue enviado en la solicitud HTTP. Este método es útil para fines de depuración y para verificar cómo los datos de la solicitud están siendo procesados y manipulados a lo largo del camino, hasta llegar al servidor.CONNECT: Establece un túnel de comunicación con un servidor, permitiendo que el cliente envíe datos de forma cifrada (en el caso de HTTPS) o de manera transparente, sin intervención en el contenido de la comunicación.
GET, HEAD, OPTIONS y TRACE son considerados safe methods pues no causan alteración en el servidor.
Se espera que PUT y DELETE sean métodos idempotentes, pero debe ser aplicado por los desarrolladores. POST no es idempotente.
No todos los métodos necesitamos pasar parámetros, es decir, pasar un body. Solicitar una página url simple no necesitamos pasar nada, solo pedir.
| METHOD | Request Body | Response Body | Safe | Idempotent | Cachable |
|---|---|---|---|---|---|
| GET | No | Yes | Yes | Yes | Yes |
| HEAD | No | No | Yes | Yes | Yes |
| POST | Yes | Yes | No | No | Yes |
| PUT | Yes | Yes | No | Yes | No |
| DELETE | No | Yes | No | Yes | No |
| CONNECT | Yes | Yes | No | No | No |
| OPTIONS | Optional | Yes | Yes | Yes | No |
| TRACE | No | Yes | Yes | Yes | No |
| PATCH | Yes | Yes | No | No | Yes |
Códigos de Estado HTTP
También vimos el 200 en la respuesta como un status de éxito.
Los códigos de estado indican el resultado de una solicitud. Están divididos en 5 categorías principales, cada una representando un tipo de respuesta. Vamos a explorar todos los principales códigos y sus significados:
No es necesario memorizar todo esto, lo mantendré aquí para que quede como consulta.
1xx: Informativos- Indican que la solicitud fue recibida y está siendo procesada.- 100 Continue: El servidor recibió los encabezados y el cliente puede continuar enviando el cuerpo de la solicitud.
- 101 Switching Protocols: El servidor acepta cambiar el protocolo de comunicación, como de HTTP a WebSocket.
- 102 Processing (WebDAV): El servidor recibió la solicitud, pero aún está siendo procesada.
2xx: Éxito- Indican que la solicitud fue exitosa.- 200 OK: La solicitud fue exitosa, y el contenido es retornado (o confirmada la acción).
- 201 Created: Un recurso fue creado en el servidor.
- 202 Accepted: La solicitud fue aceptada, pero aún está siendo procesada.
- 203 Non-Authoritative Information: La respuesta es válida, pero fue obtenida de un servidor intermediario.
- 204 No Content: Solicitud exitosa, pero sin contenido para retornar.
- 205 Reset Content: Solicitud exitosa, el cliente debe resetear la visualización.
- 206 Partial Content: Parte del contenido fue entregado (usado en descargas parciales).
- 207 Multi-Status (WebDAV): Múltiples respuestas para diferentes subitems de una solicitud.
3xx: Redirecciones- Indican que es necesario seguir otra URL.- 300 Multiple Choices: Existen múltiples opciones para el recurso solicitado.
- 301 Moved Permanently: El recurso fue movido a una nueva URL permanentemente.
- 302 Found: El recurso fue temporalmente movido a otra URL.
- 303 See Other: El cliente debe usar otra URL para acceder al recurso.
- 304 Not Modified: El recurso no fue modificado desde el último acceso (usado en cache).
- 307 Temporary Redirect: Redirección temporal, con el mismo método de solicitud.
- 308 Permanent Redirect: Redirección permanente, con el mismo método de solicitud.
4xx: Errores del cliente- Indican problemas con la solicitud hecha por el cliente.- 400 Bad Request: La solicitud está malformada o es inválida.
- 401 Unauthorized: El cliente necesita autenticarse.
- 402 Payment Required: Reservado para futuras implementaciones relacionadas a pagos.
- 403 Forbidden: El cliente no tiene permiso para acceder al recurso.
- 404 Not Found: El recurso solicitado no fue encontrado.
- 405 Method Not Allowed: El método HTTP usado no está permitido para el recurso.
- 406 Not Acceptable: El recurso no está disponible en el formato solicitado.
- 407 Proxy Authentication Required: El cliente debe autenticarse en el proxy.
- 408 Request Timeout: El cliente tardó mucho en enviar la solicitud.
- 409 Conflict: Conflicto en el estado del recurso (ejemplo: versiones conflictivas).
- 410 Gone: El recurso solicitado ya no está disponible y no será restaurado.
- 411 Length Required: El encabezado Content-Length es obligatorio.
- 412 Precondition Failed: Una precondición en el encabezado falló.
- 413 Payload Too Large: El tamaño del payload excede el límite permitido.
- 414 URI Too Long: La URI es muy larga para ser procesada.
- 415 Unsupported Media Type: El tipo de medio no es soportado.
- 416 Range Not Satisfiable: El cliente solicitó un intervalo de datos que no puede ser entregado.
- 417 Expectation Failed: El servidor no pudo atender el campo Expect de la solicitud.
- 418 I'm a Teapot: Estándar de broma del protocolo HTTP.
- 421 Misdirected Request: El servidor no está configurado para responder.
- 422 Unprocessable Entity (WebDAV): El servidor entiende el contenido, pero no puede procesarlo.
- 423 Locked (WebDAV): El recurso está bloqueado.
- 424 Failed Dependency (WebDAV): Una dependencia falló.
- 425 Too Early: El servidor se niega a procesar una solicitud que puede ser repetida.
- 426 Upgrade Required: El cliente debe cambiar a otro protocolo.
- 428 Precondition Required: El servidor exige que condiciones sean enviadas en la solicitud.
- 429 Too Many Requests: El cliente excedió el límite de solicitudes.
- 431 Request Header Fields Too Large: Los campos del encabezado son muy grandes.
- 451 Unavailable For Legal Reasons: El recurso fue bloqueado por razones legales.
5xx: Errores del servidor- Indican problemas en el lado del servidor.- 500 Internal Server Error: El servidor encontró un error inesperado.
- 501 Not Implemented: El servidor no soporta la funcionalidad solicitada.
- 502 Bad Gateway: El servidor recibió una respuesta inválida de un servidor upstream.
- 503 Service Unavailable: El servidor está temporalmente indisponible.
- 504 Gateway Timeout: El servidor no recibió una respuesta a tiempo de otro servidor.
- 505 HTTP Version Not Supported: La versión HTTP no es soportada.
- 506 Variant Also Negotiates: Error de configuración en el servidor.
- 507 Insufficient Storage (WebDAV): Espacio insuficiente en el servidor.
- 508 Loop Detected (WebDAV): Loop infinito en una solicitud.
- 510 Not Extended: Extensiones necesarias no fueron atendidas.
- 511 Network Authentication Required: El cliente necesita autenticarse para acceder a la red.
Vamos a hacer una experiencia usando telnet para abrir una conexión y después colocar lo que queremos.
telnet google.com 80
Trying 142.251.135.142...
Connected to google.com.
Escape character is '^]'.
GET /about/ # Digitado
HTTP/1.0 301 Moved Permanently # Respuesta y redirección
Location: https://about.google/
Content-Type: text/html; charset=UTF-8
X-Content-Type-Options: nosniff
Date: Thu, 02 Jan 2025 01:05:38 GMT
Expires: Thu, 02 Jan 2025 01:35:38 GMT
Cache-Control: public, max-age=1800
Server: sffe
Content-Length: 218
X-XSS-Protection: 0
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="https://about.google/">here</A>.
</BODY></HTML>
Connection closed by foreign host.
Vamos a intentar google.com y solicitar el / es decir la página principal. Si usamos el puerto 80 redireccionará al puerto 443 automáticamente.
telnet google.com 80
Trying 142.251.135.142...
Connected to google.com.
Escape character is '^]'.
GET / # Digitamos esto y de aquí en adelante tenemos la respuesta
HTTP/1.0 200 OK
#...
Al final de cuentas el navegador facilita esto para nosotros de forma que no lo vemos.
Aunque los códigos de estado HTTP son un estándar ampliamente aceptado y recomendado, en la práctica, muchas implementaciones de APIs y servidores no utilizan o siguen estas especificaciones de forma rigurosa. Esto ocurre por varios motivos:
- Muchos desarrolladores tienden a usar solo los códigos más comunes como 200 OK, 400 Bad Request, 404 Not Found, y 500 Internal Server Error, ignorando otros más específicos.
- No todos los desarrolladores están familiarizados con toda la gama de status disponibles. Esto lleva a implementaciones simplificadas o incluso inadecuadas.
- Algunas organizaciones o frameworks crean sus propios estándares de status o incluso encapsulan las respuestas, retornando siempre un 200 OK con un campo "status" en el cuerpo de la respuesta para indicar errores. Aunque funcione, esto va en contra de las prácticas RESTful.
- Para aplicaciones pequeñas o sin muchos requisitos, usar una gama completa de códigos de estado puede ser visto como un "overkill".
- Algunos frameworks o bibliotecas no ofrecen soporte fácil para toda la gama de códigos HTTP, lo que lleva a los desarrolladores a adaptar las implementaciones.
- En algunos casos, los desarrolladores eligen ignorar estándares para simplificar el desarrollo o por falta de tiempo.
¿Cómo resolver esto?
- Promover el entendimiento sobre la importancia de los status HTTP y crear guías internas sobre buenas prácticas de APIs.
- Revisiones de código garantizando que los status correctos sean usados de acuerdo con los estándares.
- Herramientas como linters y frameworks modernos pueden ayudar a estandarizar.
Header y Content
Un header es un conjunto de información adicional enviada al inicio de una solicitud o respuesta HTTP. Está compuesto por pares de clave-valor y sirve para transmitir metadatos, como información sobre:
El cliente o servidor. El formato del contenido. Reglas de autenticación. Configuraciones de cache, entre otros.
El content son los datos de hecho.
POST /api/users HTTP/1.1
Host: api.example.com
Authorization: Bearer abc123
Content-Type: application/json
Content-Length: 47
{
"username": "david puziol",
"email": "[email protected]"
}
¿Qué parte es Header y cuál es Content?
- Header
Host: api.example.com
Authorization: Bearer abc123
Content-Type: application/json
Content-Length: 47
- Content
{
"username": "david puziol",
"email": "[email protected]"
}
Siempre existen headers en una solicitud especificándolo o no. Muchos headers son inyectados automáticamente. Podemos usar los headers para pasar tráfico de valores que no son los datos reales, pero a veces necesarios además de aquellos que ya están definidos por defecto.
Algunos Headers que verás por ahí.
-
Host: Permite que el servidor sepa qué dominio/proceso atender, en caso de estar hospedando varios.
-
Connection: Define qué debe ocurrir con la conexión después de la solicitud/respuesta. Economiza recursos de red y mejora el rendimiento al permitir múltiples solicitudes/respuestas en la misma conexión.
- Valores comunes:
- keep-alive: Mantiene la conexión abierta para reutilización, pero el cliente y el servidor necesitan soportar.
- close: Cierra la conexión después de la respuesta.
En REST, cada solicitud es independiente (sin estado), pero eso no significa que la conexión física de red necesite ser abierta y cerrada a cada solicitud. REST se concentra en cómo las solicitudes son estructuradas y en los datos que están siendo transferidos, y no en la conexión física. La conexión persistente con keep-alive es una optimización de red, y no afecta los principios de diseño de REST, que están basados en la separación entre cliente y servidor.
- Valores comunes:
-
User-Agent: Informa al servidor qué cliente (navegador, aplicación o biblioteca) está haciendo la solicitud que permite al servidor adaptar el contenido para diferentes clientes y registrar información analítica sobre el tráfico. Valores que solemos ver son:
- Mozilla/5.0 (Windows NT 10.0; Win64; x64)
- AppleWebKit/537.36 (KHTML, like Gecko)
- Chrome/91.0.4472.124 Safari/537.36
-
Accept: Especifica los tipos de contenido que el cliente acepta en la respuesta (application/json es un ejemplo). Se usa principalmente cuando el servidor puede devolver la respuesta en diferentes formatos.
-
Accept-Encoding: Indica los métodos de compresión que el cliente acepta para economizar ancho de banda (gzip, deflate, br).
-
Accept-Language: El servidor puede usar esta información para personalizar la respuesta (en-US).
-
Content-Type: Especifica el tipo de datos enviados en el cuerpo de la solicitud o respuesta (application/json, text/html, etc).
-
Content-Length: Indica el tamaño (en bytes) del cuerpo de la solicitud o respuesta. Es calculado automáticamente por la mayoría de los clientes y servidores para saber cuándo el cuerpo del mensaje termina y evitar errores de lectura.
-
Authorization: Contiene las credenciales para autenticar el cliente en el servidor. Se usa en solicitudes que exigen login o tokens (Bearer abc123)
-
Cookie: Envía cookies almacenadas en el cliente al servidor para información como sesiones de login o preferencias del usuario (Cookie: session_id=xyz123; theme=dark)