Protocolo HTTP (HyperText Transfer Protocol)
O HTTP (HyperText Transfer Protocol) é o protocolo que define como as mensagens são formatadas e transmitidas entre clientes e servidores na web. É a base para a comunicação de dados na Internet e funciona sobre o modelo de request response. O HTTP foi criado por Tim Berners-Lee em 1989. A solução proposta por Berners-Lee foi um sistema de hipertexto distribuído globalmente, que ele chamou de World Wide Web. O HTTP foi desenvolvido como um protocolo de comunicação para permitir a transferência de documentos de hipertexto entre servidores e clientes na Web. A primeira especificação do HTTP, conhecida como HTTP/0.9, foi um protocolo simples que permitia apenas a solicitação e resposta de documentos de hipertexto. Em 1996, a versão HTTP/1.0 foi lançada, introduzindo melhorias significativas em relação ao HTTP/0.9.
Baseado em texto: As mensagens são enviadas em texto simples, o que facilita o entendimento e depuração.Modelo client-server: O cliente (geralmente um navegador ou uma aplicação) envia uma requisição ao servidor, que responde com os dados solicitados (ex.: páginas HTML, imagens, etc.).stateless (sem estado): Cada requisição é independente e o servidor não mantém informações sobre requisições anteriores. Se for necessário manter estado, usa-se cookies, sessões ou outras técnicas.Protocolo da camada de aplicação do modelo OSI. O HTTP geralmente usa o TCP como transporte, mas pode ser combinado com outros.Extensível: Suporta cabeçalhos personalizados, métodos adicionais e outras extensões.
Um pouco da evolução do HTTP só para conhecimento rápido.
-
De HTTP/1.0 para HTTP/1.1: 1.0 melhorou a versão 0.9 permitindo a transferência de diversos tipos de conteúdo, como imagens e vídeos, além de texto. Além disso, introduziu a capacidade de enviar informações adicionais na forma de cabeçalhos de metadados, melhorando a comunicação entre cliente e servidor, mas tinha um problema com desempenho. A versão 1.1 foi lancáda em 1997 introduzindo a conexão persistente, que permitia múltiplas solicitações e respostas na mesma conexão, diminuindo a latência e melhorando o desempenho. -
HTTP/2.0 (lançado em 2015): Focada principalmente em melhorias de desempenho e eficiência, como a multiplexação de fluxos e a compressão de cabeçalhos, mas também ajudou na adoção de conexões segurças através do TLS (Transport Security Layer). -
O HTTP/3.0- Foi formalmente padronizado e lançado em junho de 2022. Hoje, em 2024 a maioria navegadores web já oferecem suporte ao HTTP/3. A principal mudança é a substituição do protocolo TCP na camada de transporte pelo protocolo QUIC (Quick UDP Internet Connections). O QUIC não permite mais a transmissão de texto puro, somente criptografados, sendo necessário o uso do TLS 1.3 forçando o uso dohttps://.
Para entender melhor o QUIC é necessário um conhecimento sobre os protocolos de transporte TCP e UDP. O TCP envia um pacote de dados e também recebe a confirmação do recebimento desses pacotes enquanto o protocolo o UDP simplesmente faz o envio sem se preocupar se a outra parte recebeu ou não e em caso de erro finge que nada aconteceu. O TCP é focado na confiabilidade e integridade enquanto o UDP na velocidade e na latência.
Quando enviamos arquivos usamos o TCP para garantir a integridade do arquivos, pois não queremos um arquivo faltando pedaços.
Quando queremos velocidade e a latência é um fator, como streamming de videos, voip, etc, acabamos usando o UDP e aceitando algumas perdas para melhorar a qualidade da experiência e fluidez.
O QUIC, que é baseado no protocolo UDP para garantir a latência, mas promete garantir a confiabilidade e a segurança das conexões. Ele adiciona uma camada extra ao UDP com funcionalidades como retransmissão de pacotes, controle de congestionamento e outras características do TCP, mas mantendo a velocidade. Com isso, um pacote enviado através do QUIC será sempre recebido pela outra ponta, cedo ou tarde.
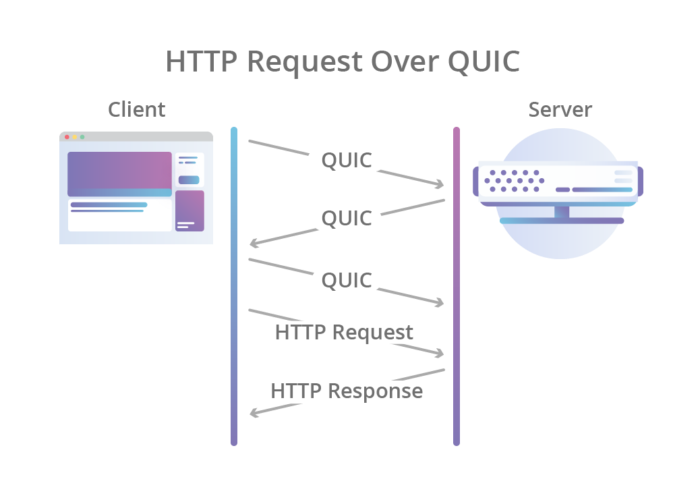
Um exemplo do fluxo do QUIC.
Request vs Response
Vamos mostrar uma estrutura de request e outra de response para entender como funciona.
Estrutura de uma Requisição HTTP
-
Linha de requisição: Contém o método HTTP, o recurso solicitado e a versão do protocolo.
GET /index.html HTTP/1.1 -
Cabeçalhos: Informações adicionais, como o tipo de conteúdo esperado ou dados de autenticação.
Host: www.example.com
User-Agent: Mozilla/5.0 -
Corpo da requisição: Usado em métodos como POST ou PUT para enviar dados (ex.: formulários, JSON).
Estrutura de uma Resposta HTTP
-
Linha de status: Contém a versão do protocolo, o código de status e uma descrição textual. 200 é sucesso, e falaremos mais sobre esses status posteriormente.
HTTP/1.1 200 OK -
Cabeçalhos: Informações como tipo de conteúdo, tamanho da resposta ou configurações de cache.
Content-Type: text/html
Content-Length: 123 -
Corpo da resposta: O conteúdo solicitado (ex.: uma página HTML, imagem ou dados JSON).
Métodos HTTP
Vimos acima o GET, mas outros métodos existem então vamos conhecer um pouco deles.
Os métodos são usados para definir uma ação em cima de um recurso. A maioria das vezes quando estamos navegando nas páginas da web estamos usando o método GET.
-
GET: Recupera dados de um recurso sem modificar o servidor.GET /products -
POST: Envia dados ao servidor para criar um recurso.POST /users com dados { "name": "Alice" } -
PUT: Atualiza ou cria um recurso no servidor.PUT /users/1 -
DELETE: Remove um recurso no servidor.DELETE /users/1 -
Menos usados mas suportados
HEAD: Igual ao GET, mas só retorna os cabeçalhos.OPTIONS: Retorna métodos disponíveis para um recurso.PATCH: Atualiza parcialmente um recurso.TRACE: Usado para realizar um loopback de diagnóstico, ou seja, ele permite que o cliente (como o navegador ou uma ferramenta) receba de volta o que foi enviado na requisição HTTP. Esse método é útil para fins de depuração e para verificar como os dados da requisição estão sendo processados e manipulados ao longo do caminho, até chegar ao servidor.CONNECT: Estabelece um túnel de comunicação com um servidor, permitindo que o cliente envie dados de forma criptografada (no caso de HTTPS) ou de maneira transparente, sem intervenção no conteúdo da comunicação.
GET, HEAD, OPTIONS e TRACE são considerados safe methods pois não causam alteração no servidor.
Espera-se que o PUT e DELETE sejam métodos idempotentes, mas deve ser aplicados pelos desenvolvedores. POST não é idempotente.
Nem todos os métodos precisamos passar parâmetros, ou seja, passar um body. Requisitar uma página url simples não precisamos passar nada, apenas pedir.
| METHOD | Request Body | Response Body | Safe | Idempotent | Cachable |
|---|---|---|---|---|---|
| GET | No | Yes | Yes | Yes | Yes |
| HEAD | No | No | Yes | Yes | Yes |
| POST | Yes | Yes | No | No | Yes |
| PUT | Yes | Yes | No | Yes | No |
| DELETE | No | Yes | No | Yes | No |
| CONNECT | Yes | Yes | No | No | No |
| OPTIONS | Optional | Yes | Yes | Yes | No |
| TRACE | No | Yes | Yes | Yes | No |
| PATCH | Yes | Yes | No | No | Yes |
Códigos de Status HTTP
Também vimos o 200 na resposta como um status de sucesso.
Os códigos de status indicam o resultado de uma requisição. São divididos em 5 categorias principais, cada uma representando um tipo de resposta. Vamos explorar todos os principais códigos e seus significados:
Não é necessário gravar tudo isso, vou manter aqui para ficar como consulta.
1xx: Informativos- Indicam que a requisição foi recebida e está sendo processada.- 100 Continue: O servidor recebeu os cabeçalhos e o cliente pode continuar enviando o corpo da requisição.
- 101 Switching Protocols: O servidor aceita mudar o protocolo de comunicação, como de HTTP para WebSocket.
- 102 Processing (WebDAV): O servidor recebeu a requisição, mas ela ainda está sendo processada.
2xx: Sucesso- Indicam que a requisição foi bem-sucedida.- 200 OK: A requisição foi bem-sucedida, e o conteúdo é retornado (ou confirmada a ação).
- 201 Created: Um recurso foi criado no servidor.
- 202 Accepted: A requisição foi aceita, mas ainda está sendo processada.
- 203 Non-Authoritative Information: Resposta é válida, mas foi obtida de um servidor intermediário.
- 204 No Content: Requisição bem-sucedida, mas sem conteúdo para retornar.
- 205 Reset Content: Requisição bem-sucedida, o cliente deve resetar a exibição.
- 206 Partial Content: Parte do conteúdo foi entregue (usado em downloads parciais).
- 207 Multi-Status (WebDAV): Múltiplas respostas para diferentes subitens de uma requisição.
3xx: Redirecionamentos- Indicam que é necessário seguir outra URL.- 300 Multiple Choices: Existem múltiplas opções para o recurso solicitado.
- 301 Moved Permanently: O recurso foi movido para uma nova URL permanentemente.
- 302 Found: O recurso foi temporariamente movido para outra URL.
- 303 See Other: O cliente deve usar outra URL para acessar o recurso.
- 304 Not Modified: O recurso não foi modificado desde o último acesso (usado em cache).
- 307 Temporary Redirect: Redirecionamento temporário, com o mesmo método de requisição.
- 308 Permanent Redirect: Redirecionamento permanente, com o mesmo método de requisição.
4xx: Erros do cliente- Indicam problemas com a requisição feita pelo cliente.- 400 Bad Request: A requisição está malformada ou inválida.
- 401 Unauthorized: O cliente precisa se autenticar.
- 402 Payment Required: Reservado para futuras implementações relacionadas a pagamentos.
- 403 Forbidden: O cliente não tem permissão para acessar o recurso.
- 404 Not Found: O recurso solicitado não foi encontrado.
- 405 Method Not Allowed: O método HTTP usado não é permitido para o recurso.
- 406 Not Acceptable: O recurso não está disponível no formato solicitado.
- 407 Proxy Authentication Required: O cliente deve autenticar no proxy.
- 408 Request Timeout: O cliente demorou muito para enviar a requisição.
- 409 Conflict: Conflito no estado do recurso (exemplo: versões conflitantes).
- 410 Gone: O recurso solicitado não está mais disponível e não será restaurado.
- 411 Length Required: O cabeçalho Content-Length é obrigatório.
- 412 Precondition Failed: Uma pré-condição no cabeçalho foi falhada.
- 413 Payload Too Large: O tamanho do payload excede o limite permitido.
- 414 URI Too Long: A URI é muito longa para ser processada.
- 415 Unsupported Media Type: O tipo de mídia não é suportado.
- 416 Range Not Satisfiable: O cliente solicitou um intervalo de dados que não pode ser entregue.
- 417 Expectation Failed: O servidor não conseguiu atender ao campo Expect da requisição.
- 418 I'm a Teapot: Padrão de brincadeira do protocolo HTTP.
- 421 Misdirected Request: O servidor não está configurado para responder.
- 422 Unprocessable Entity (WebDAV): O servidor entende o conteúdo, mas não pode processá-lo.
- 423 Locked (WebDAV): O recurso está bloqueado.
- 424 Failed Dependency (WebDAV): Uma dependência falhou.
- 425 Too Early: O servidor se recusa a processar uma requisição que pode ser repetida.
- 426 Upgrade Required: O cliente deve mudar para outro protocolo.
- 428 Precondition Required: O servidor exige que condições sejam enviadas na requisição.
- 429 Too Many Requests: O cliente excedeu o limite de requisições.
- 431 Request Header Fields Too Large: Os campos do cabeçalho são muito grandes.
- 451 Unavailable For Legal Reasons: O recurso foi bloqueado por razões legais.
5xx: Erros do servidor- Indicam problemas no lado do servidor.- 500 Internal Server Error: O servidor encontrou um erro inesperado.
- 501 Not Implemented: O servidor não suporta a funcionalidade requisitada.
- 502 Bad Gateway: O servidor recebeu uma resposta inválida de um servidor upstream.
- 503 Service Unavailable: O servidor está temporariamente indisponível.
- 504 Gateway Timeout: O servidor não recebeu uma resposta a tempo de outro servidor.
- 505 HTTP Version Not Supported: A versão HTTP não é suportada.
- 506 Variant Also Negotiates: Erro de configuração no servidor.
- 507 Insufficient Storage (WebDAV): Espaço insuficiente no servidor.
- 508 Loop Detected (WebDAV): Loop infinito em uma requisição.
- 510 Not Extended: Extensões necessárias não foram atendidas.
- 511 Network Authentication Required: O cliente precisa se autenticar para acessar a rede.
Vamos fazer uma experiencia usando o telnet para abrir uma conexão e depois colocar o que queremos.
telnet google.com 80
Trying 142.251.135.142...
Connected to google.com.
Escape character is '^]'.
GET /about/ # Digitado
HTTP/1.0 301 Moved Permanently # Resposta e redirecionamento
Location: https://about.google/
Content-Type: text/html; charset=UTF-8
X-Content-Type-Options: nosniff
Date: Thu, 02 Jan 2025 01:05:38 GMT
Expires: Thu, 02 Jan 2025 01:35:38 GMT
Cache-Control: public, max-age=1800
Server: sffe
Content-Length: 218
X-XSS-Protection: 0
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="https://about.google/">here</A>.
</BODY></HTML>
Connection closed by foreign host.
Vamos tentar o google.com e requisitar o / ou seja a página principal. Se usarmos a porta 80 ele irá redirecionar para a porta 443 automaticamente.
telnet google.com 80
Trying 142.251.135.142...
Connected to google.com.
Escape character is '^]'.
GET / # Digitamos isso e daqui para frente temos a resposta
HTTP/1.0 200 OK
#...
No fim das contas o navegador facilita isso para nós de forma que não vemos.
Embora os códigos de status HTTP sejam um padrão amplamente aceito e recomendado, na prática, muitas implementações de APIs e servidores não utilizam ou seguem essas especificações de forma rigorosa. Isso acontece por vários motivos:
- Muitos desenvolvedores tendem a usar apenas os códigos mais comuns como 200 OK, 400 Bad Request, 404 Not Found, e 500 Internal Server Error, ignorando outros mais específicos.
- Nem todos os desenvolvedores estão familiarizados com toda a gama de status disponíveis. Isso leva a implementações simplificadas ou mesmo inadequadas.
- Algumas organizações ou frameworks criam seus próprios padrões de status ou até encapsulam as respostas, retornando sempre um 200 OK com um campo "status" no corpo da resposta para indicar erros. Embora funcione, isso vai contra as práticas RESTful.
- Para aplicações pequenas ou sem muitos requisitos, usar uma gama completa de códigos de status pode ser visto como um "overkill".
- Alguns frameworks ou bibliotecas não oferecem suporte fácil para toda a gama de códigos HTTP, o que leva desenvolvedores a adaptar as implementações.
- Em alguns casos, os desenvolvedores escolhem ignorar padrões para simplificar o desenvolvimento ou por falta de tempo.
Como resolver isso?
- Promover o entendimento sobre a importância dos status HTTP e criar guias interno sobre boas práticas de APIs.
- Revisões de código garantindo que os status corretos sejam usados de acordo com os padrões.
- Ferramentas como linters e frameworks modernos podem ajudar a padronizar.
Header e Content
Um header é um conjunto de informações adicionais enviadas no início de uma requisição ou resposta HTTP. Ele é composto por pares de chave-valor e serve para transmitir metadados, como informações sobre:
O cliente ou servidor. O formato do conteúdo. Regras de autenticação. Configurações de cache, entre outros.
O content são dados de fato.
POST /api/users HTTP/1.1
Host: api.example.com
Authorization: Bearer abc123
Content-Type: application/json
Content-Length: 47
{
"username": "david puziol",
"email": "[email protected]"
}
Qual parte é Header qual é Content?
- Header
Host: api.example.com
Authorization: Bearer abc123
Content-Type: application/json
Content-Length: 47
- Content
{
"username": "david puziol",
"email": "[email protected]"
}
Sempre existem headers em uma requisição você específicando ou não. Muitos headers são injetados automaticamente. Podemos usar os headers para passar trafegar valores que não são os dados reais, mas as vezes necessários além daqueles que já são definidos por default.
Alguns Headers que irá ver por ai.
-
Host: Permite que o servidor saiba qual domínio/processo atender, caso esteja hospedando vários.
-
Connection: Define o que deve acontecer com a conexão após a requisição/resposta. Economiza recursos de rede e melhora a performance ao permitir múltiplas requisições/respostas na mesma conexão.
- Valores comuns:
- keep-alive: Mantém a conexão aberta para reutilização, mas o cliente e o servidor precisa suportar.
- close: Fecha a conexão após a resposta.
Em REST, cada requisição é independente (sem estado), mas isso não significa que a conexão física de rede precisa ser aberta e fechada a cada requisição. O REST se concentra em como as requisições são estruturadas e nos dados que estão sendo transferidos, e não na conexão física. A conexão persistente com keep-alive é uma otimização de rede, e não afeta os princípios de design do REST, que são baseados na separação entre cliente e servidor.
- Valores comuns:
-
User-Agent: Informa ao servidor qual cliente (navegador, aplicativo ou biblioteca) está fazendo a requisição que permite o servidor adaptar o conteúdo para diferentes clientes e registre informações analíticas sobre o tráfego. Valores que costumamo ver são:
- Mozilla/5.0 (Windows NT 10.0; Win64; x64)
- AppleWebKit/537.36 (KHTML, like Gecko)
- Chrome/91.0.4472.124 Safari/537.36
-
Accept: Especifica os tipos de conteúdo que o cliente aceita na resposta (application/json é um exemplo). É usado principalmente quando o servidor pode devolver a resposta em diferentes formatos.
-
Accept-Encoding: Indica os métodos de compressão que o cliente aceita para economizar largura de banda (gzip, deflate, br).
-
Accept-Language: O servidor pode usar essa informação para personalizar a resposta (en-US).
-
Content-Type: Especifica o tipo de dados enviados no corpo da requisição ou resposta (application/json, text/html, etc).
-
Content-Length: Indica o tamanho (em bytes) do corpo da requisição ou resposta. É Calculado automaticamente pela maioria dos clientes e servidores para saber quando o corpo da mensagem termina e evitar erros de leitura.
-
Authorization: Contém as credenciais para autenticar o cliente no servidor. É usado requisições que exigem login ou tokens (Bearer abc123)
-
Cookie: Envia cookies armazenados no cliente para o servidor para informações como sessões de login ou preferências do usuário (Cookie: session_id=xyz123; theme=dark)