Requests
A request to a path is associated with the action it will execute which will be an Operation Object. Just to recap, these are the methods we have in OpenAPI, but so far we've only used Get, however for the same path we have several possible methods.
path:
/products: # Path Object
# All of these are path items objects
$ref: "" # Expects a string
summary: ""
description: ""
get: {} # Expects an Operation Object inside #<<<<<<
put: {} # Expects an Operation Object inside
post: {} # Expects an Operation Object inside
delete: {} # Expects an Operation Object inside
options: {} # Expects an Operation Object inside
head: {} # Expects an Operation Object inside
patch: {} # Expects an Operation Object inside
trace: {} # Expects an Operation Object inside
servers: {} # Expects a server object inside
parameters: {} # Expects a Parameter Reference inside
In the get method that will define an operation object we have only used parameters and responses so far.
path:
#...
/v1/customers/{Id}:
get: # Operation Object for the path above.
parameters: # <<<
- $ref: '#/components/parameters/Id'
responses: # <<<
'200':
description: Found Customer
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
For the same path we can define an operation object for each method, however it is not possible to define two different gets. A get can generate multiple responses.
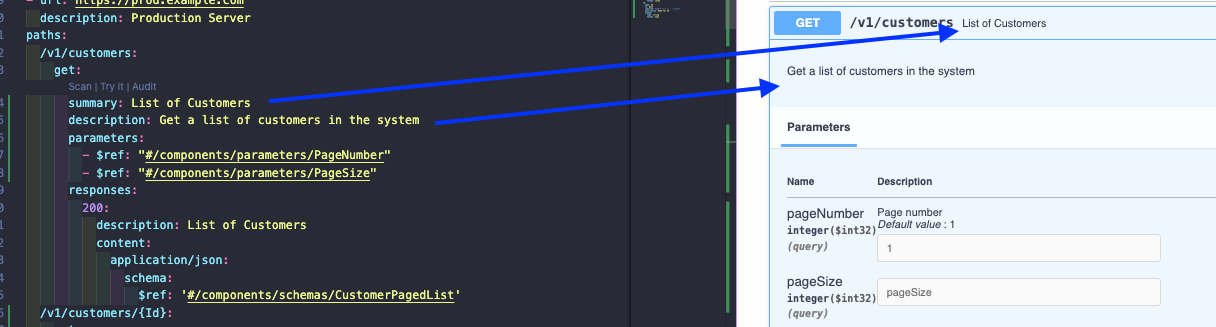
Summary and Description
We always need to think about who will use our API, so it is good practice to clarify as much as possible about everything.
In all operations objects we have summary and description which are worth specifying to be shown in the API.
Knowing that the summary has a short space be direct and be more detailed in the description.
Tags
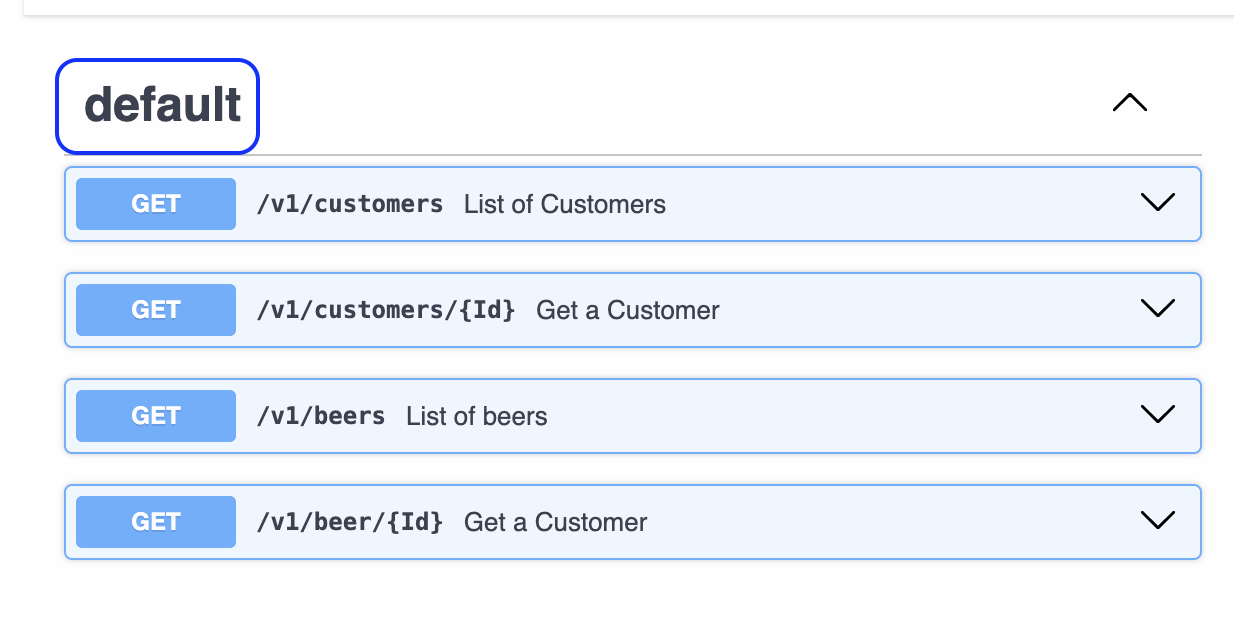
It is not possible to create tags globally for all methods within a path. It is necessary to create tags inside each of the methods. We can have a list of tags.
When we don't define a tag everything stays in default.
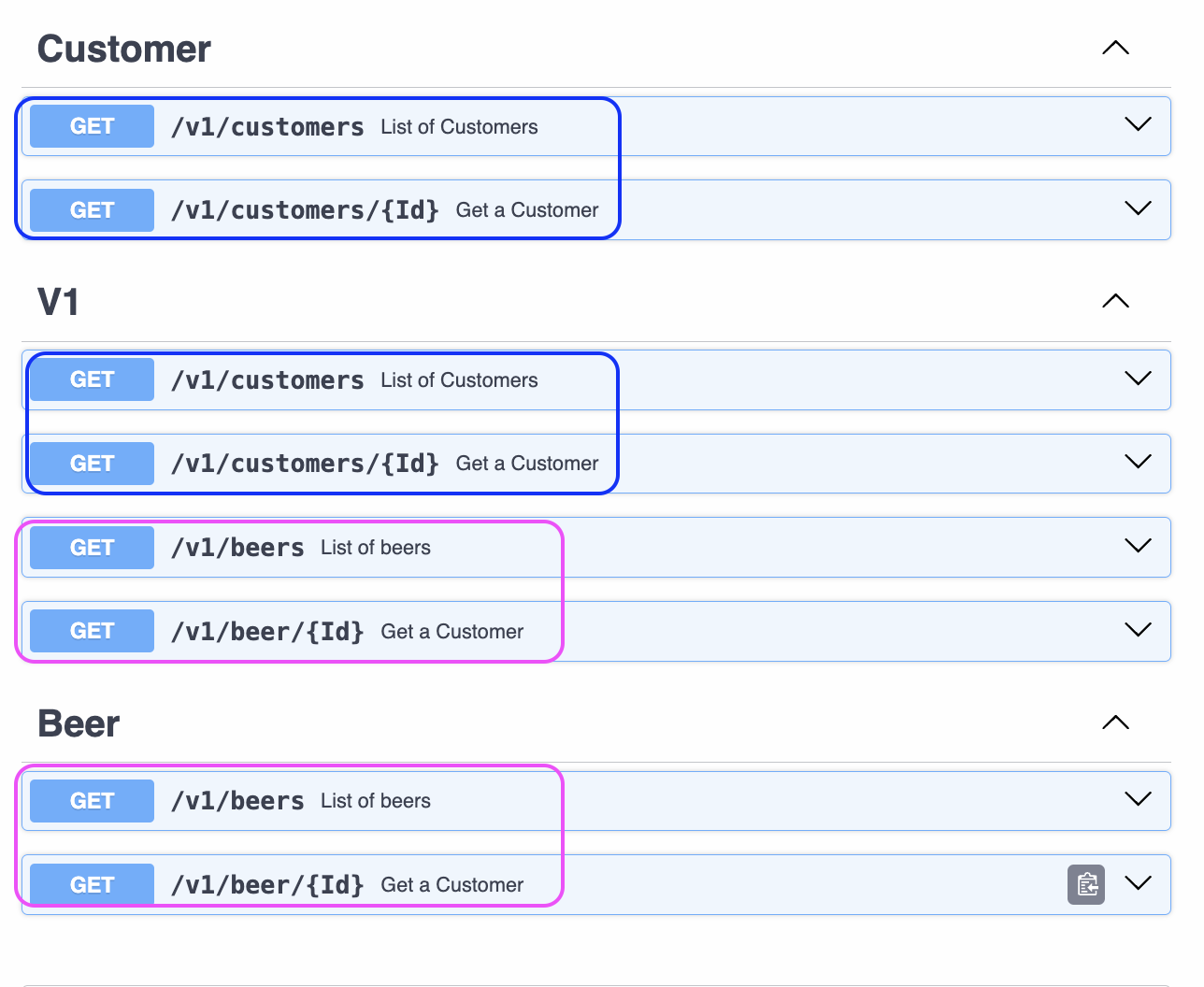
Once a tag name appears a visual grouping will be made. If an operation participates in two tags it will appear in two groups even if it needs to be repeated. This way it is more flexible than declaring tags globally.
openapi: 3.0.2
info:
# ...
paths:
/v1/customers:
get:
summary: List of Customers
description: Get a list of customers in the system
tags:
- Customer
- V1
# ...
/v1/customers/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
tags:
- Customer
- V1
# ...
/v1/beers:
get:
summary: List of beers
description: Get a list of beers in the system
tags:
- Beer
- V1
# ...
/v1/beer/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
tags:
- Beer
- V1
# ...
OperationId (optional)
In OpenAPI, the operationId is a unique identifier for an operation. It is used to differentiate each operation on an endpoint and is often used by code generation tools to create functions or methods corresponding to that operation. It mainly serves as a bridge between the OpenAPI specification and the generated code or tools that consume the API, such as SDKs or integration systems.
- Code Generation: Tools like Swagger Codegen or OpenAPI Generator use the operationId to name functions/methods in generated SDKs.
- If operationId is getUserById, the generated code may contain a method like getUserById().
- Ease of Navigation: Allows large APIs to have a unique reference for each operation, facilitating mapping between specification and code.
- Ensuring each operation is unique avoids conflicts in implementations and documentation.
- Naming should reflect the action the operation performs.
- Follow a pattern to name operationId, such as verbResource (e.g., createUser, deleteOrder).
Although operationId is optional, adding it is highly recommended, especially for projects that use documentation or code generation tools.
If you are not using tools that directly depend on operationId, there is no immediate technical impact on API functionality. The API will continue to work normally, as long as you correctly implement the endpoints and routing in the backend.
-
If the operationId in the specification does not correspond to how the endpoint is handled in the code, it can cause confusion for other developers or teams consulting the documentation. Someone looking at the specification may expect there to be a method called getUserById, but in the code you handled it as fetchUser.
-
If in the future you decide to use code generation or create SDKs based on the API, the inconsistency between operationId and code may generate poorly named methods or cause need for rework.
-
Some documentation or testing tools may use operationId to uniquely identify operations. If it does not correspond to the code logic, it can hinder automation.
Let's define our operationsID to later generate code with this API.
openapi: 3.0.2
info:
# ...
paths:
/v1/customers:
get:
summary: List of Customers
description: Get a list of customers in the system
operationId: listCustomersV1 #<<<<
tags:
- Customer
# ...
/v1/customers/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
operationId: getCustomerById #<<<<
tags:
- Customer
# ...
/v1/beers:
get:
summary: List of beers
description: Get a list of beers in the system
operationId: listBeers #<<<<
tags:
- Beer
# ...
/v1/beer/{Id}:
get:
summary: Get a Customer
description: Get a single customer by its ID value
operationId: getBeerById #<<<<
tags:
- Beer
# ...
# ...
Request Body
Technically what we have available in each operation object is this.
- tags
- description
- externalDocs (Can also be used at API level)
# At API level
externalDocs:
description: Learn more about this API
url: https://example.com/docs/api
path:
/v1/user
get:
# Method level
ExternalDocs:
description: Learn more about this endpoint
url: https://example.com/docs/api/v1/user
- operationId
- parameters
- requestBody (Our next learning)
- responses
- callbacks
- deprecate
- security
- servers
The HTTP GET method can have a body but this practice is highly discouraged and uncommon as well as HEAD and OPTIONS. Review the methods table and see that these methods serve only to retrieve data and not to modify data.
Many server implementations, proxies and HTTP libraries ignore or reject a body in GET requests.
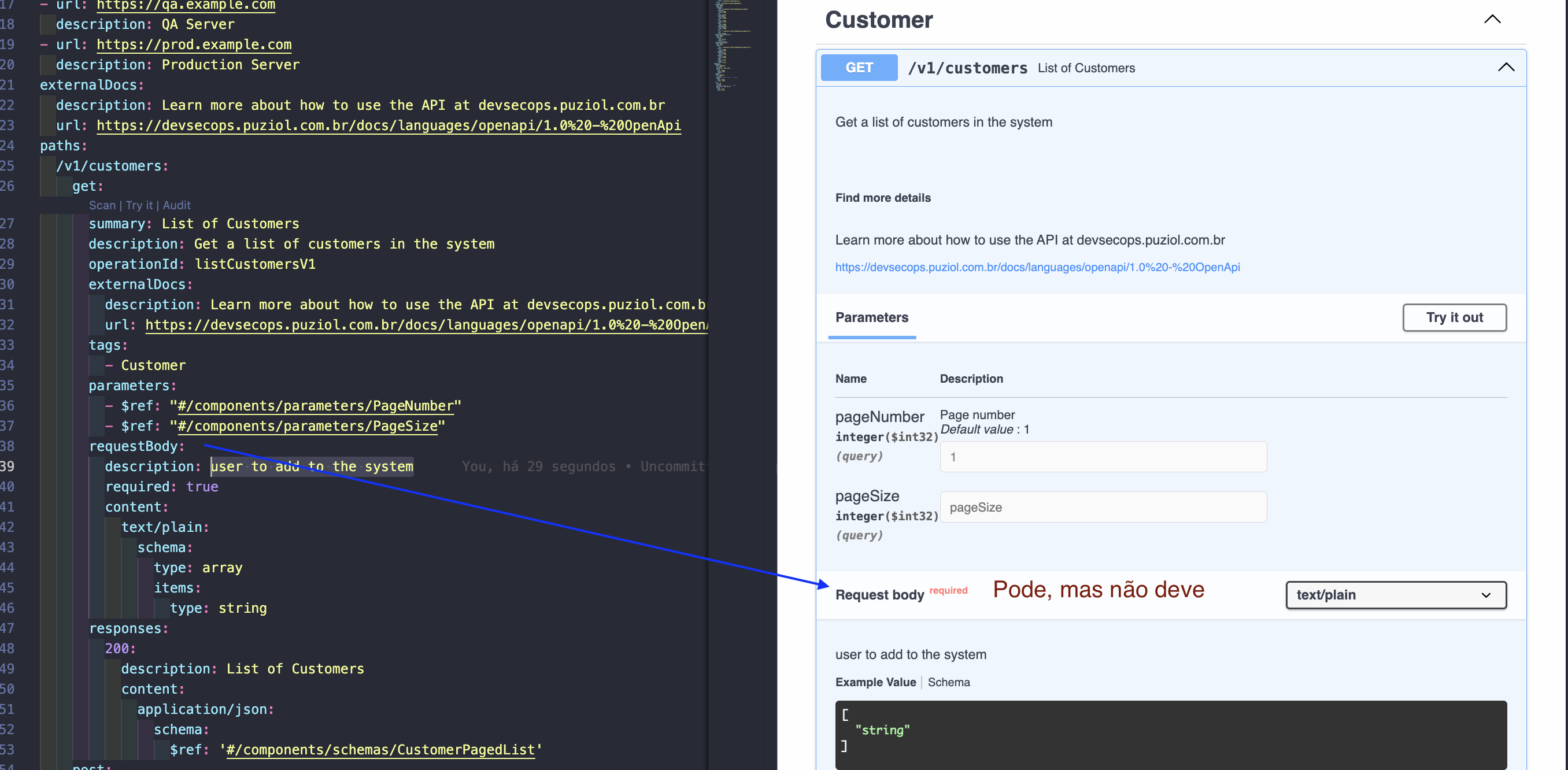
But let's do a validation outside this vscode plugin to test.
# Let's use the openapi-generator tool just to test quickly what I said above.
openapi-generator validate -i infoapi.yaml
Validating spec (infoapi.yaml)
No validation issues detected. # Passes but should not be used
Creating a POST
Now let's build a POST method that will use a requestBody.
paths:
/v1/customers:
get:
#....
post:
summary: New Customer
description: Create a new customer
operationId: newCustomer
tags:
- Customer
requestBody: # The Body we will need.
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
201:
description: New Customer Created
# We could return something, but this is the simplest case.
Going back to HTTP Status Codes, 201 means that a resource was created on the server.
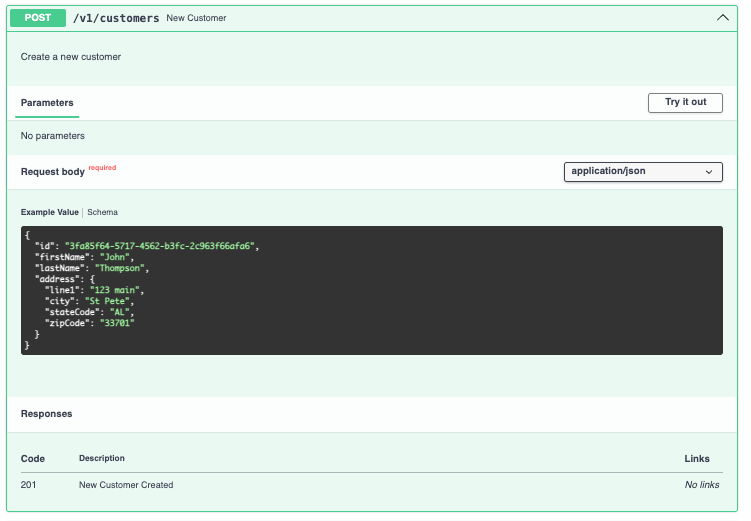
In this case we are not expecting any parameters, we are expecting directly the json with everything we need inside to create a customer.
It is completely normal for a POST method to use both requestBody and parameters (query or path). Each element has a different purpose and its use depends on the API design. The requestBody is used to send more complex data in the request body and generally used to create or update resources. Examples: JSON, XML, Yaml, or other structured formats.
The situation happening above is that the id is being passed inside the customer object, but who should create the Id is the system, but we'll fix that soon.
Another thing we should keep in mind is that RESTful is a commonly accepted standard. Following standards depends on your will. The idea is to follow right?
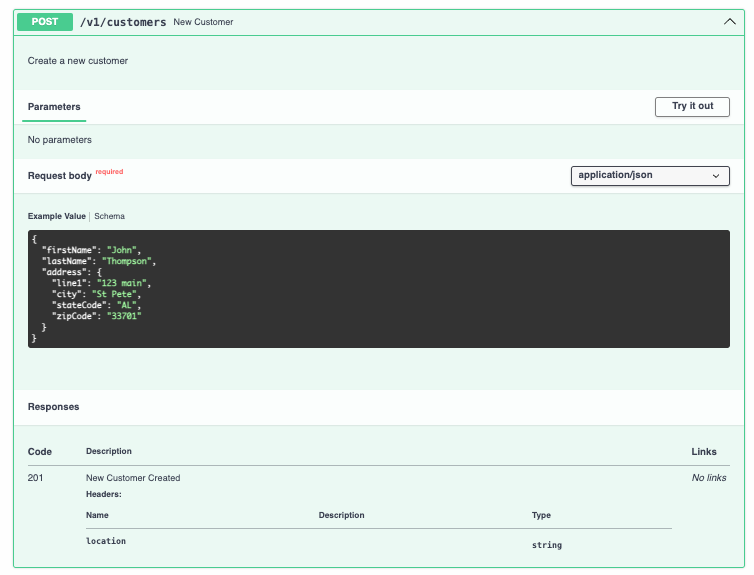
It is standard to return the location of the resource in the header when it is created on the server so let's implement it.
post:
summary: New Customer
description: Create a new customer
operationId: newCustomer
tags:
- Customer
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
201:
description: New Customer Created
##### Return in header
headers:
location:
schema:
description: Location of the created resource
type: string
format: uri
example: http://example.com/v1/customers/{assignedIdValue}
# other:
# schema:
# description:
# type: string
#####
Each status can have:
- description (string) REQUIRED
- headers (header object)
- content (Content if necessary to return)
- links
An interesting thing is we are talking about response, but the request can also and generally has headers. An example is Content-Type (application/json) and Bearer Token (authentication).
We can create custom headers as we saw above in the case of location.
To solve the Id problem we can work with readOnly and define that this field is not used in the request.
components:
schemas:
Customer:
type: object
properties:
id:
type: string
format: uuid
readOnly: true #<<<<
firstName:
maxLength: 100
minLength: 2
type: string
example: John
lastName:
maxLength: 100
minLength: 2
type: string
example: Thompson
address:
$ref: '#/components/schemas/Address'
description: customer object
Using this same schema in the request (post) and in the response (get) we see the omission of id when it is a request.
|  |
| --------- | --------- |
|
| --------- | --------- |
The writeOnly does exactly the opposite. For example a password that is expected in the request and we don't return in the response.
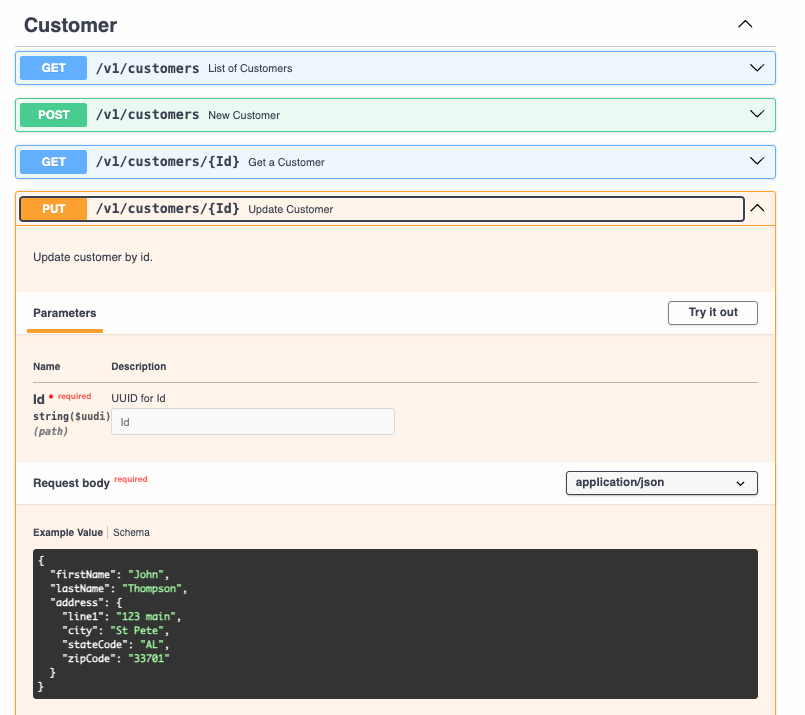
Creating a PUT
Basically PUT will do an update of an existing resource. This time we will use the path /v1/customers/{Id} because we want to pass the Id of the customer that will be updated.
info:
#...
path:
#...
/v1/customers/{Id}:
get:
#...
put:
summary: Update Customer
description: Update customer by id.
tags:
- Customer
operationId: UpdateCustomerById
parameters:
# This parameter is in components and is of type path
# It was used in previous examples
- $ref: '#/components/parameters/Id'
requestBody:
required: true
content:
application/json:
schema:
# Remember it is readOnly for Id that's why we are passing in the path
$ref: '#/components/schemas/Customer'
responses:
204: # No Content: Successful request, but no content to return.
description: Customer Updated
#...
#...
Creating a DELETE
This operation will be practically the same as PUT the difference is we will return the function that will be executed on the server will be another.
An important thing is that we are returning 200 because it is expected that if a resource is deleted there would be nothing to return.
path:
#...
/v1/customers/{Id}:
get:
#...
put:
#...
delete:
summary: Delete Customer
description: Delete customer by id.
tags:
- Customer
operationId: deleteCustomerById
parameters:
- $ref: '#/components/parameters/Id'
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
responses:
200:
description: Customer Deleted
#...
#...

Using Multiple Status
Not always will we have success status. Asking to delete or update a resource by a non-existent id will result in failure.
OpenAPI serves as documentation and from it we can generate code that respects this documentation, however who actually implements the return values is who developed the endpoint.
Let's imagine this scenario.
paths:
/users:
get:
responses:
"404":
description: User not found
Will this be the description that will come back in the message? It should be if whoever implemented the function respects the openapi documentation. However, if whoever implemented had done this...
app.get('/users', (req, res) => {
const user = findUser(req.query.id);
if (!user) {
res.status(404).json({ error: 'User not found in the system' });
}
});
For error 404 the message User not found in the system would come.
The status are the expected values that the function returns and the type of content, header, etc. It is good to clarify this to understand OpenAPI does not process anything, but serves as reference and from this reference we create standards both for who will develop and who will consume.
Let's put new status that could exist which we will be exercising other types of status.
The possible status will appear in the documentation.

openapi: 3.0.2
info:
###...
paths:
/v1/customers:
get:
###...
responses:
200:
description: List of Customers
content:
application/json:
schema:
$ref: '#/components/schemas/CustomerPagedList'
# We don't need more here for now it will deliver an empty list or not
post:
###...
responses:
201:
description: New Customer Created
headers:
location:
schema:
description: Location of the created resource
type: string
format: uri
400:
description: Bad Request
# The schema was not respected
409:
description: Conflict
# Trying to include a user that already exists
/v1/customers/{Id}:
get:
###...
responses:
200:
description: Found Customer
content:
application/json:
schema:
$ref: '#/components/schemas/Customer'
404:
description: Not found
put:
###...
responses:
204:
description: Customer Updated
400:
description: Bad Request
404:
description: Not found
409:
description: Conflict
delete:
###...
responses:
200:
description: Customer Deleted
404:
# If the passed id is not found
description: Not found
###..
components:
###...
###...