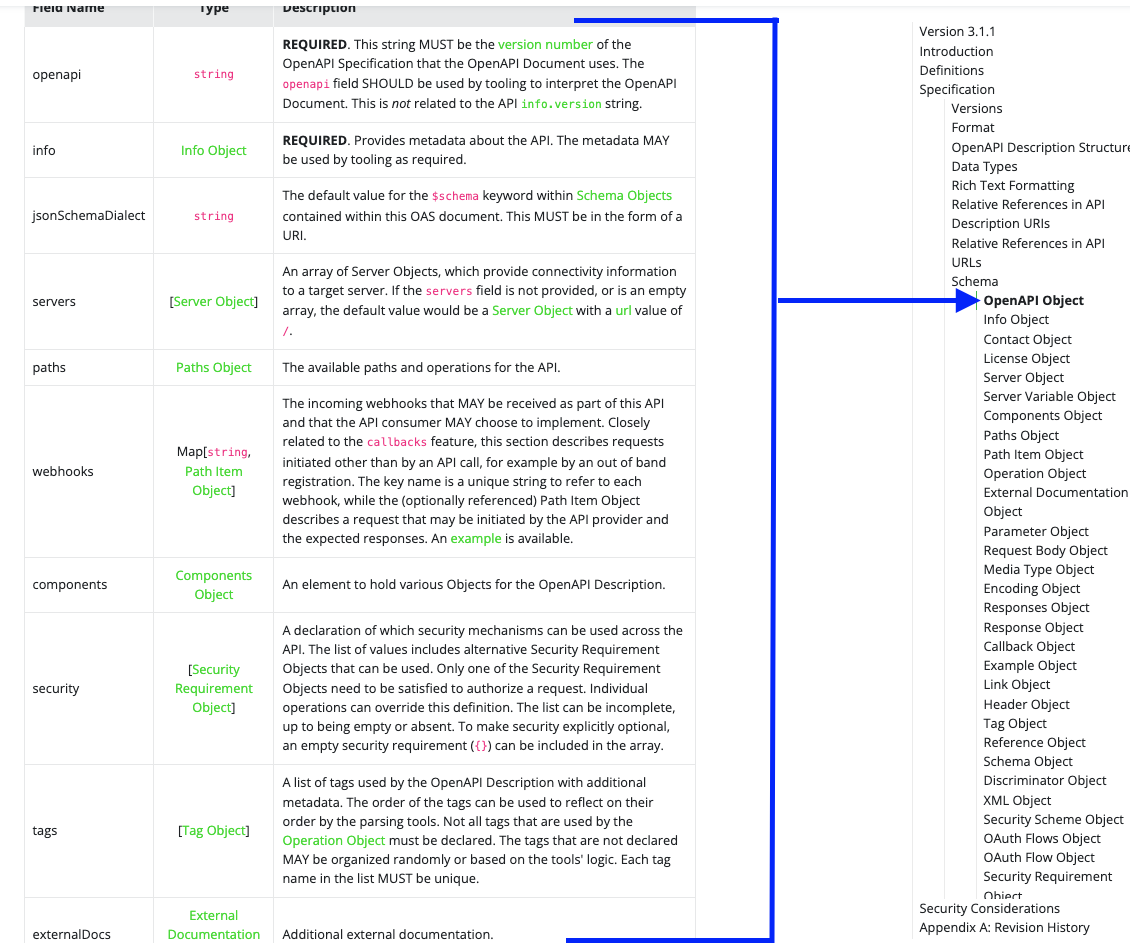
Specification
The git repository, the learning documentation and the examples are very helpful to start this journey.
It is important to have knowledge of YAML and JSON to understand the specifications.
Let's move on to the simplest definition of an API.
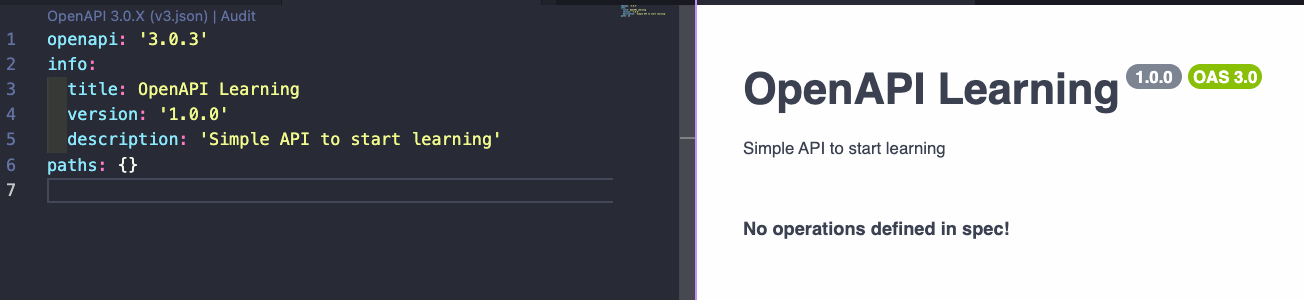
Not all fields are required but it is good practice to declare at least the fields below in info.
openapi: '3.0.3'
info:
title: OpenAPI Learning
version: '1.0.0'
description: 'Simple API to start learning'
paths: {}
In the repository, inside the versions folder, we can see very rich documentation about the API definition object, that is, the structure that is expected from the yaml file we are going to create. We can also see this same documentation on the swagger website https://swagger.io/specification/. During the learning process it is necessary to be well familiar with this page.
This is the top level of the specification and in each of these types we can see how each of these objects works.
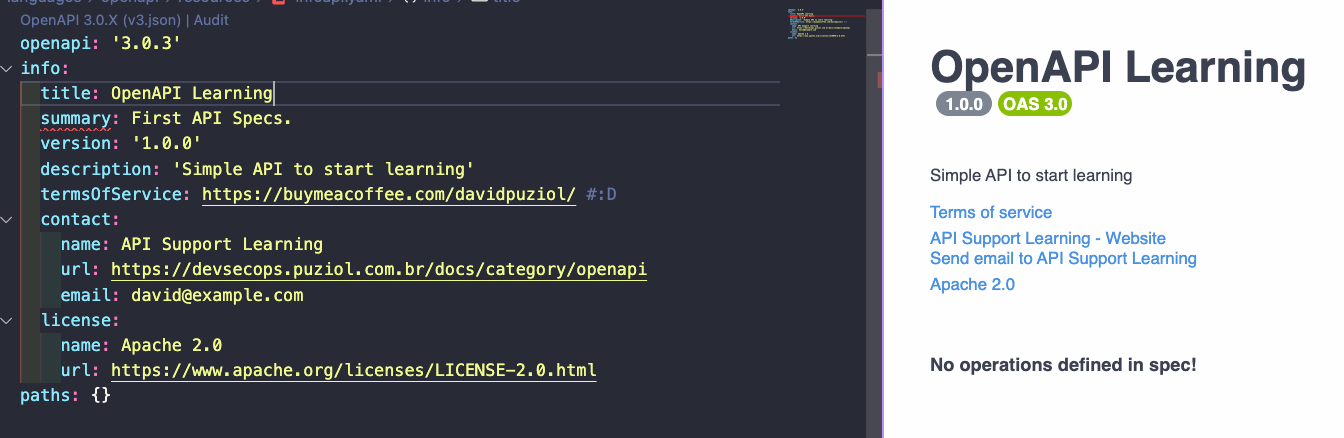
info (Required)
Provides metadata about the API. It is good practice to have good information for API documentation. Let's fill in the maximum we have to see what we can do. Inside the info Object we have two more objects (contact and license).
openapi: '3.0.3'
info:
title: OpenAPI Learning # Required
summary: First API Specs.
version: '1.0.0' # Required
description: 'Simple API to start learning'
# Terms of service also expects a URL
termsOfService: https://buymeacoffee.com/davidpuziol/ #:D
contact: # Contact object
name: API Support Learning
url: https://devsecops.puziol.com.br/docs/category/openapi
email: [email protected]
license: # License object
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0.html
paths: {}
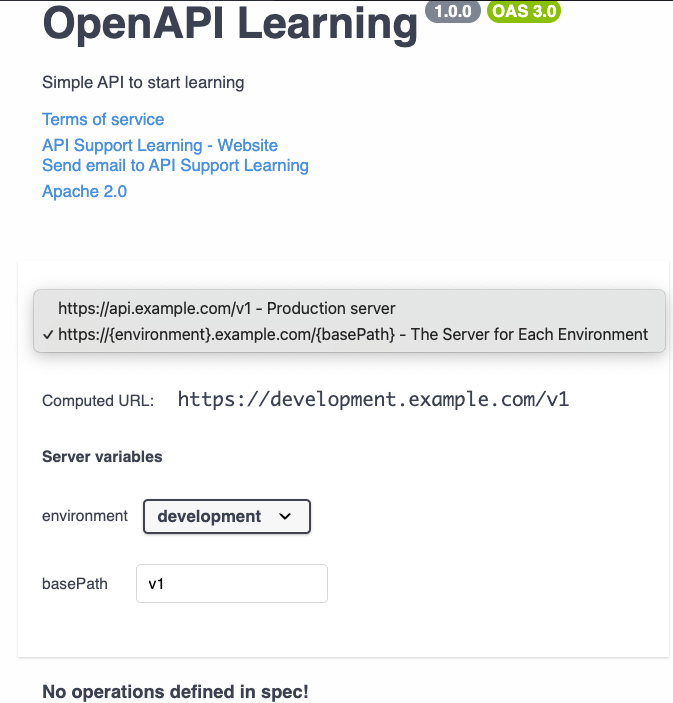
servers (Optional)
It is a way to provide end users with information about where the API is available. Each server object inside has url (required), description and variables.
openapi: '3.0.3'
### INFO
info:
title: OpenAPI Learning
summary: First API Specs.
version: '1.0.0'
description: 'Simple API to start learning'
termsOfService: https://buymeacoffee.com/davidpuziol/ #:D
contact:
name: API Support Learning
url: https://devsecops.puziol.com.br/docs/category/openapi
email: [email protected]
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0.html
### SERVERS
servers:
- url: https://development.example.com/v1
description: Development server
- url: https://staging.example.com/v1
description: Staging server
- url: https://api.example.com/v1
description: Production server
paths: {}

It is possible to define variables but it is less usual. If we were to do the same previous example we could do it like this.
servers:
- url: https://api.example.com/v1
description: Production server
- url: https://{environment}.example.com/{basePath}
description: The Server for Each Environment
variables:
environment:
description: This value select api to specific environment at example.com`
default: development
enum:
- 'development'
- 'staging'
basePath:
default: v1
paths (Required)
We arrived at the API and where do we go? It is necessary to provide the paths (endpoints).
Even if empty the path needs to be defined so we have paths: {} to satisfy the OpenAPI schema.
This is where everything happens, so it is necessary to dedicate more time to learning. The object itself is a matrix of path items type objects.
paths:
/: # Path items type object that has many definitions inside
/products: # path item
# Any case that has product/1 product/2 will fall here
/product/{productId}: # path item
Note that it is NOT an array of objects, but a matrix, if it were an array it would be like the example below. It is not an array because an array is positional and a matrix is not.
# Just to understand the difference
path:
- /: # Empty object associated with the "/" key
- /products: # Empty object associated with the "/products" key
- /product/{productId}: # Empty object associated with the "/product/productID" key
Now let's go to what actually defines each of the paths which is the path item object.
Path Items
The Path Item is summarized to the object that will define a path. In each path we have its description, a reference id, parameters and all the verbs it expects to receive, etc.
path:
/products: # Path Object
# All these are path items objects
$ref: "" # Expects a string
summary: ""
description: ""
get: {} # Expects an Operation Object inside #<<<<<<
put: {} # Expects an Operation Object inside
post: {} # Expects an Operation Object inside
delete: {} # Expects an Operation Object inside
options: {} # Expects an Operation Object inside
head: {} # Expects an Operation Object inside
patch: {} # Expects an Operation Object inside
trace: {} # Expects an Operation Object inside
servers: {} # Expects a server object inside
parameters: {} # Expects a Parameter Reference inside
An operation object needs a response, we are not going into details about this yet, we will just build a path with the minimum necessary for an operation and later we will go deeper into the operation object.
##info:
# Removed to keep only what matters for now
## ...
paths:
/v1/customers:
get:
responses: # Inside an operation object we have the possible responses
'200':
description: List of Customers
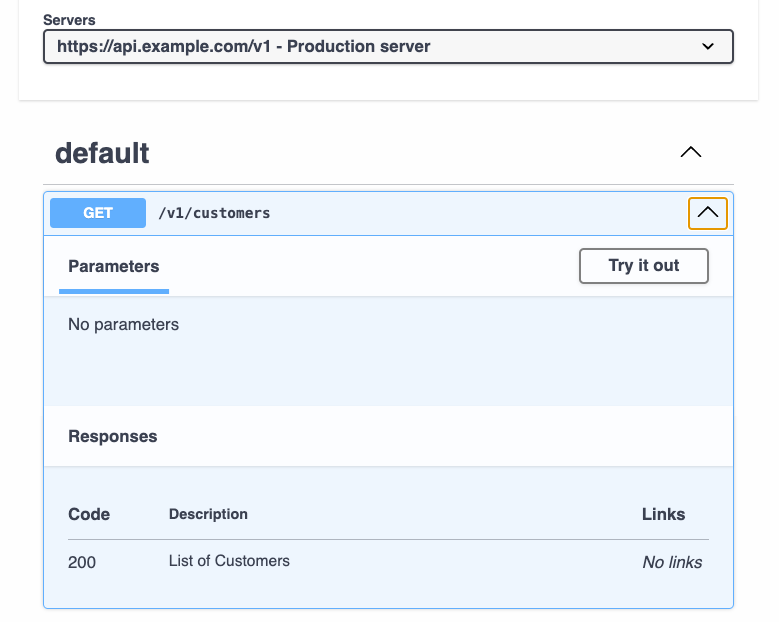
We can have several responses for the same operation. We are not going into details about the data yet. The responses are based on the codes presented previously.
If you noticed we are using /v1/customer now. This is a convention. We could declare /customer, but if one day we want to have two versions of this same path it will be much more laborious to change, so always try to use /version/path.
Why is using /v1 a common convention?
- Explicit version control: Adding the version (v1, v2, etc.) to the API path makes it clear to consumers which version they are using. This helps avoid breaking changes (changes that break compatibility) when new versions are released.
- Ease of transition: When a new version of the API is released, the old one can continue active (/v1) while the new one (/v2) is gradually adopted by clients.
- Decoupling of version and implementation: The backend can change without affecting API consumers, as long as it maintains the corresponding version in the endpoint.
- Widely used standard: Many frameworks, tools and documentation assume that an API has a version in the paths. This facilitates integration and familiarity for developers.
- Separation of responsibility: Maintaining explicit versions allows different versions to be managed by different teams or even on separate infrastructures.
- It is useful if the API is going to evolve rapidly.
There are other techniques to solve this case, but does it hurt? No? so keep it!