Fundamentos Básicos
Lo obvio necesita ser dicho. Esta frase parece tonta, pero es muy importante, tanto para IA como si eres un líder de equipo. Si quieres algo bien hecho evita que quien va a ejecutar la tarea pueda considerar algo.
Me acuerdo de un video que vi que la madre le dijo al hijo - Ve a la panadería y cómprame 6 panes, si hay leche trae 2. El hijo aparece en casa solo con 2 panes porque había leche mientras la madre esperaba 6 panes y 2 litros de leche.
Sabiendo esto, la regla de oro para trabajar con LLM es - ¿Qué instrucciones darías para que alguien lo haga?. Con esta pequeña regla ya tenemos grandes posibilidades de obtener una respuesta plausible de un modelo de lenguaje. Esta simple regla tendrá aplicaciones directas tanto en los prompts más simples como en las técnicas más avanzadas.
Comienza Simple
Comienza con lo básico. Haz lo simple bien hecho antes de agregar complejidad.
No compliques más allá de lo necesario. Prompts simples resuelven la mayoría de los problemas.
Precios vs Resultados
Ya debes haber notado: quien quiere reír, tiene que hacer reír.

Empresas ofrecen modelos más baratos y más caros. Los más caros entregan mejor resultado, incluso con prompts simples.
¿Y por qué son más caros?
Más parámetros → Cuanto más "neuronas" tiene el modelo, más conexiones hace y mejor entiende contexto, matices y lógica.
Entrenamiento con más datos y más variados → Modelos grandes fueron entrenados con mucho más información de calidad (libros, códigos, artículos, etc.), entonces saben más cosas.
Ajuste fino con humanos (RLHF) → Ellos son ajustados con feedback humano, o sea, personas corrigen las respuestas hasta que el modelo aprenda a ser más útil, educado y coherente.
La técnica básica sería usar los modelos más avanzados, aunque cueste más caro, y después conseguir a través de mejoras en el prompt conseguir generar un resultado satisfactorio en modelos más baratos para que podamos escalar.
Y recuerda: los modelos caros hoy serán baratos mañana. La evolución abarata lo que era top de línea ayer.
Incluso con modelos más inteligentes, las técnicas básicas continuarán siendo útiles para estructurar bien la conversación con la IA — tanto en lo visual del texto como en la lógica de la interacción.
No exageres. Es pérdida de tiempo A veces gastas un montón de tiempo refinando algo y, cuando lo consigues, percibes que se convirtió en lo normal. Si la IA no lo hace hoy, pronto lo hará. Lo que es sueño hoy es rutina mañana.
Las computadoras están aprendiendo nuestro idioma en vez de que tengamos que aprender el de ellas.
Necesitamos apenas aprender a expresar y comunicar buenas ideas que una programación complicada.
Web vs API
Aunque sean de la misma empresa y usen los mismos modelos, la suscripción paga da acceso solo al uso en app/web, no incluye llamadas vía API (llamadas directamente en el endpoint) que es lo que usamos para hacer automatizaciones.
Ya la API es vendida como infraestructura para desarrolladores crear apps, bots, integraciones etc., y tiene cobro separado por uso (tokens consumidos).
- Infraestructura de API es diferente: Ella necesita garantizar rendimiento para múltiples sistemas integrados. El tráfico y control de costo son otros.
- El Web/app es uso individual: Mientras API es consumo programático (y puede escalar fácil para miles/millones de llamadas).
- Monetización separada: Un usuario puede usar muy poco en el app, pero gastar mucho con API — o lo contrario.
¿Qué es un Token en ese Contexto?
Necesitamos entender sobre tokens cuando vamos a hacer una llamada de API.
Un token es una unidad de texto que el modelo entiende. Puede ser una palabra, parte de una palabra, o hasta símbolos como puntuación.
Vamos a imaginar que tenemos un texto simple "Hola, ¿qué tal?"
Los tokens no son los mismos si variamos los modelos, pues la tokenización depende de cómo el modelo fue entrenado. Cada empresa (OpenAI, Google, Anthropic, Mistral, etc.) puede usar algoritmos diferentes para romper el texto.
En OpenAI podemos usar el sitio https://platform.openai.com/tokenizer para verificar.
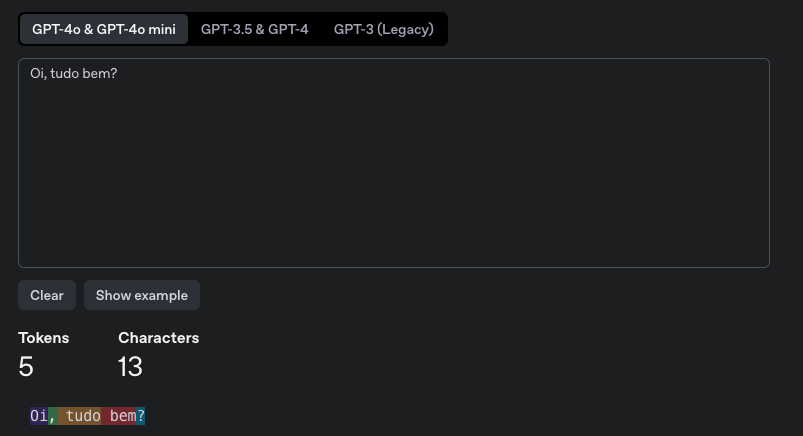
Para el modelo GPT-4o tenemos 5 tokens.
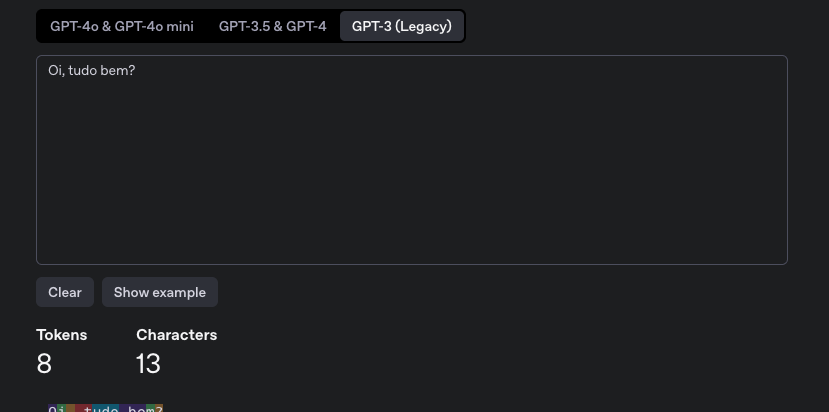
Pero para el modelo GPT-3 tenemos 8 tokens.
En Anthropic es necesaria una llamada en el endpoint pasando la apikey, el modelo y el texto. Tenemos 15 tokens para el modelo Claude 4.
❯ curl https://api.anthropic.com/v1/messages/count_tokens \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data \
'{
"model": "claude-sonnet-4-20250514",
"messages": [
{"role": "user", "content": "Hola, ¿qué tal?"}
]
}'
{"input_tokens":15}
Aquí un ejemplo de cuánto cuesta 1 Millón de Token en Anthropic para 3 modelos cuando escribí esto.
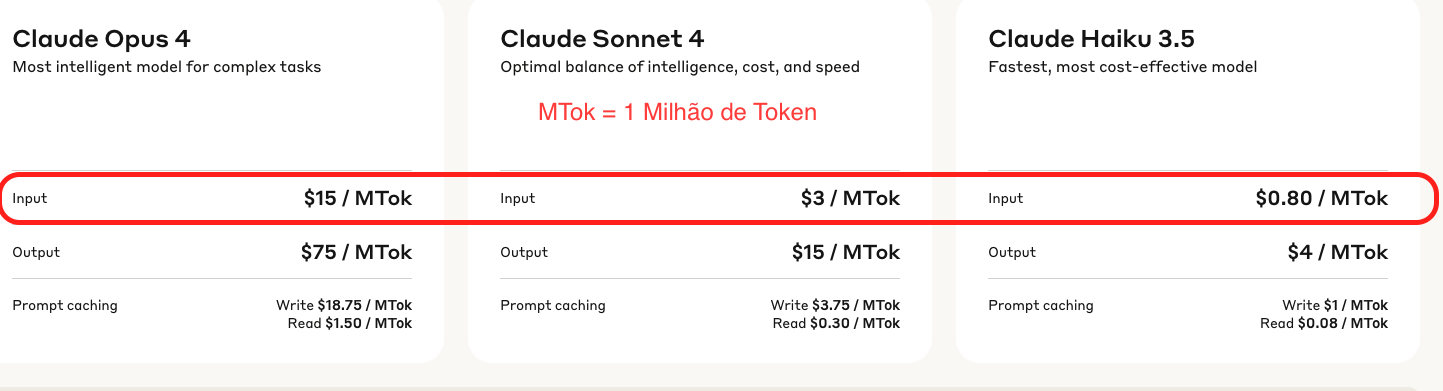
Tomando como base el Claude 3.5, podemos observar que el Claude 4 cuesta 3.75 veces más y el Opus cuesta 18.75 veces más que ese modelo.
La precificación de tokens depende mucho de la empresa detrás del modelo, entonces no sirve de nada hacer una tabla comparativa que va a cambiar el valor.
¿Cómo Consumimos Tokens?
Pagas por cuántos tokens envías (Tu prompt completo) y recibes (respuesta de la IA).
Vamos a hacer una matemática simple para el modelo Claude 3.5 que funciona bajo el paraguas de Anthropic, por lo tanto necesitamos usar la precificación de ellos.
| Tipo | Precio por token |
|---|---|
| Input | $0.80 / 1000000 = $0.0000008 |
| Output | $4.00 / 1000000 = $0.000004 |
Imaginando un ejemplo de (500 input / 300 output tokens)
- Input: 500 × 0.0000008 = $0.0004
- Output: 300 × 0.000004 = $0.0012
- Costo real: $0.0016 (poco más de 0.001 centavo)
La respuesta del modelo puede variar, no se puede predecir totalmente lo que vendrá.
Prompt Caching
Es una técnica para reaprovechar prompts que usas con frecuencia, sin necesidad de pagar el precio completo cada vez.
Normalmente envías un prompt grande tipo:
{
"system": "Eres un asistente técnico que responde como un devsecops senior.",
"user": "Explica qué es kubernetes."
}
Cada vez que envías esto, pagas por el input entero.
Con Prompt Caching guardas ese prompt estándar con un ID, tipo:
POST /v1/prompt_cache
{
"id": "mi_prompt_estandar",
"prompt": {
"system": "...",
"user": "..."
}
}
Y después reutilizas solo el ID.
{
"prompt_id": "mi_prompt_estandar",
"user": "¿Cómo mejorar la seguridad en el cluster?"
}
Hablaremos sobre esto con más detalles en el futuro.
P.R.O.M.P.T Inicial
A la hora de construir un prompt — la conversación con el LLM — es importante seguir un flujo para organizar las ideas.
Lo que viene a seguir resuelve 80% de los casos:
-
P (PERSONA) – ¿Quién debe ser el modelo?
- Ej: "Eres especialista en seguridad de la información."
- LLMs fueron entrenados con mucho contenido. Si no direccionamos, puede no saber de dónde partir.
-
R (GUION) – ¿Cuál es la tarea?
- Ej: "Quiero ayuda para montar una política de seguridad."
-
O (OBJETIVO) – ¿A dónde queremos llegar?
- Ej: "Crear una política clara y aplicable."
-
M (MODELO) – ¿Cómo debe ser el resultado?
- Ej: "En formato de lista con tópicos y explicaciones."
- En las técnicas avanzadas, este punto se vuelve aún más poderoso.
-
P (PANORAMA) – ¿Cuál es el contexto y ejemplos?
- Ej: "Organización con 50 colaboradores, ambiente en nube, etc."
-
T (TRANSFORMAR) – ¿Qué cambiar, mejorar o ajustar?
- Ej: "Ahora cambia Azure por AWS, y agrega un ejemplo práctico."
- No siempre la primera respuesta será perfecta. Puede ser necesario interactuar con la IA o hasta usar self-refinement, como veremos en técnicas futuras.
Proceso
¿Seguiste la estructura arriba y resolvió? Genial. Pero ¿y cuando el prompt exige más razonamiento lógico? Ahí entra el proceso:
-
Define tareas y criterios de éxito. Mucha gente comienza un prompt (o hasta un proyecto entero) sin saber a dónde quiere llegar.
- Desempeño y precisión: ¿Qué tan bien el modelo necesita ir? A veces una respuesta genérica ya resuelve.
- Latencia: ¿Cuál es el tiempo aceptable de respuesta? Modelos mayores piensan más, pero responden mejor. Sin embargo una respuesta corta y práctica puede ser suficiente para el propósito.
- Precio: ¿Cuál es el presupuesto? Evalúa costo por llamada, tamaño del modelo, frecuencia de uso.
-
Desarrolla casos de prueba: ¿Cómo saber si estás cerca del resultado ideal?
- Crea ejemplos genéricos (80%) y algunos de excepción (casos de borde).
-
Escribe el prompt inicial con base en la estructura P.R.O.M.P.T.
-
Prueba con los ejemplos
- Evalúa los resultados manualmente o usa otra LLM para eso — hasta con sugerencias de mejora.
-
Refina el prompt con base en los resultados
- Ese es el ciclo: 4, 5, 4, 5, 4, 5... hasta acertar.
-
Coloca en producción. Cuando el prompt sea confiable, listo — puede escalar!