Basic Fundamentals
The obvious needs to be said. This phrase seems silly, but it's too important, both for AI and if you're a team leader. If you want something done well, avoid letting whoever will execute the task speculate about anything.
I remember a video I saw where the mother told her son - Go to the bakery and buy me 6 loaves of bread, if they have milk bring 2. The son shows up at home with only 2 loaves of bread because they had milk while the mother expected 6 loaves of bread and 2 liters of milk.
Knowing this, the golden rule for working with LLM is - What instructions would you give someone to do this? With this simple rule we already have great chances of obtaining a plausible response from a language model. This simple rule will have direct applications both in the simplest prompts and in the most advanced techniques.
Start Simple
Start with the basics. Do the simple things well before adding complexity.
Don't overcomplicate beyond what's necessary. Simple prompts solve most problems.
Prices vs Results
You must have already noticed: if you want to laugh, you have to make them laugh.

Companies offer cheaper and more expensive models. The more expensive ones deliver better results, even with simple prompts.
And why are they more expensive?
More parameters → The more "neurons" the model has, the more connections it makes and the better it understands context, nuances, and logic.
Training with more and more varied data → Large models were trained with much more quality information (books, codes, articles, etc.), so they know more things.
Fine-tuning with humans (RLHF) → They are adjusted with human feedback, that is, people correct the answers until the model learns to be more useful, polite, and coherent.
The basic technique would be to use the most advanced models, even if they cost more, and then through improvements in the prompt manage to generate a satisfactory result in cheaper models so that we can scale.
And remember: the expensive models today will be cheap tomorrow. Evolution makes what was top of the line yesterday cheaper.
Even with smarter models, basic techniques will continue to be useful for structuring the conversation with AI well — both in the visual appearance of the text and in the logic of the interaction.
Don't overdo it. It's a waste of time Sometimes you spend a long time refining something and, when you succeed, you realize it became the new normal. If AI doesn't do it today, it will soon. What is a dream today is routine tomorrow.
Computers are learning our language instead of us having to learn theirs.
We just need to learn to express and communicate good ideas rather than complicated programming.
Web vs API
Even being from the same company and using the same models, the paid subscription gives access only to use in the app/web, it doesn't include calls via API (calls directly to the endpoint) which is what we use to make automations.
The API is sold as infrastructure for developers to create apps, bots, integrations, etc., and has separate billing per use (consumed tokens).
- API infrastructure is different: It needs to guarantee performance for multiple integrated systems. The traffic and cost control are different.
- The Web/app is individual use: While API is programmatic consumption (and can easily scale to thousands/millions of calls).
- Separate monetization: A user can use very little in the app, but spend a lot with API — or the opposite.
What is a Token in this Context?
We need to understand about tokens when we're going to make an API call.
A token is a unit of text that the model understands. It can be a word, part of a word, or even symbols like punctuation.
Let's imagine we have a simple text "Hi, how are you?"
Tokens are not the same if we vary the models, because tokenization depends on how the model was trained. Each company (OpenAI, Google, Anthropic, Mistral, etc.) may use different algorithms to break up the text.
At OpenAI we can use the site https://platform.openai.com/tokenizer to check.
For the GPT-4o model we have 5 tokens.
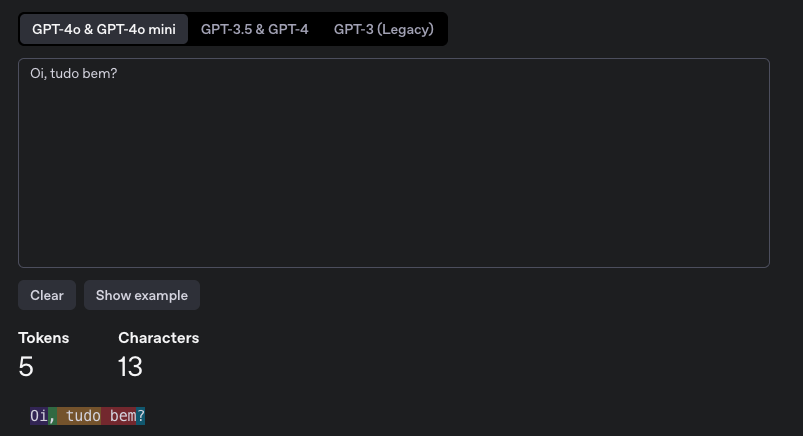
But for the GPT-3 model we have 8 tokens.
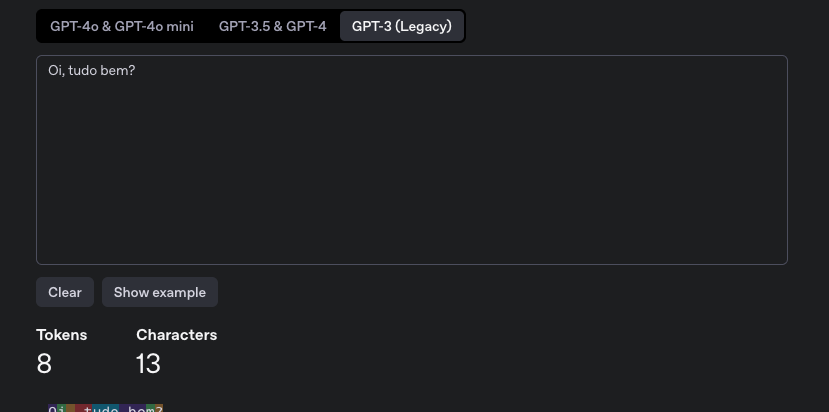
At Anthropic a call to the endpoint is needed passing the apikey, the model, and the text. We have 15 tokens for the Claude 4 model.
❯ curl https://api.anthropic.com/v1/messages/count_tokens \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--data \
'{
"model": "claude-sonnet-4-20250514",
"messages": [
{"role": "user", "content": "Hi, how are you?"}
]
}'
{"input_tokens":15}
Here is an example of how much 1 Million Tokens cost at Anthropic for 3 models when I wrote this.
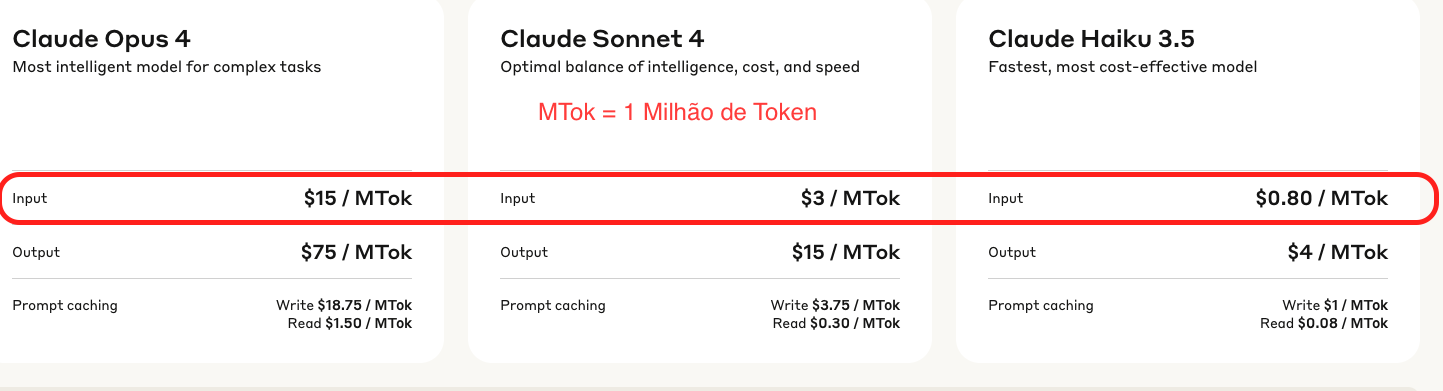
Taking Claude 3.5 as a base, we can observe that Claude 4 costs 3.75 times more and Opus costs 18.75 times more than this model.
Token pricing depends a lot on the company behind the model, so there's no point in making a comparative table that will change the value.
How Do We Consume Tokens?
You pay for how many tokens you send (Your complete prompt) and receive (AI response).
Let's do simple math for the Claude 3.5 model that works under Anthropic's umbrella, so we need to use their pricing.
| Type | Price per token |
|---|---|
| Input | $0.80 / 1000000 = $0.0000008 |
| Output | $4.00 / 1000000 = $0.000004 |
Imagining an example of (500 input / 300 output tokens)
- Input: 500 × 0.0000008 = $0.0004
- Output: 300 × 0.000004 = $0.0012
- Real cost: $0.0016 (a little over 0.001 cent)
The model's response can vary, it's not possible to totally predict what will come.
Prompt Caching
It's a technique to reuse prompts you use frequently, without needing to pay full price every time.
Normally you send a large prompt like:
{
"system": "You are a technical assistant who responds like a senior devsecops.",
"user": "Explain what kubernetes is."
}
Every time you send this, you pay for the entire input.
With Prompt Caching you save this standard prompt with an ID, like:
POST /v1/prompt_cache
{
"id": "my_standard_prompt",
"prompt": {
"system": "...",
"user": "..."
}
}
And then you reuse just the ID.
{
"prompt_id": "my_standard_prompt",
"user": "How to improve cluster security?"
}
We'll talk about this in more detail in the future.
Initial P.R.O.M.P.T
When building a prompt — the conversation with the LLM — it's important to follow a flow to organize ideas.
What comes next solves 80% of cases:
-
P (PERSONA) – Who should the model be?
- Ex: "You are an information security expert."
- LLMs were trained with a lot of content. If we don't direct them, they may not know where to start.
-
R (ROADMAP) – What is the task?
- Ex: "I want help building a security policy."
-
O (OBJECTIVE) – Where do we want to get to?
- Ex: "Create a clear and applicable policy."
-
M (MODEL) – How should the result be?
- Ex: "In list format with topics and explanations."
- In advanced techniques, this point becomes even more powerful.
-
P (PANORAMA) – What is the context and examples?
- Ex: "Organization with 50 employees, cloud environment, etc."
-
T (TRANSFORM) – What to change, improve, or adjust?
- Ex: "Now change Azure to AWS, and add a practical example."
- Not always will the first response be perfect. It may be necessary to interact with the AI or even use self-refinement, as we'll see in future techniques.
Process
Did you follow the structure above and it worked? Great. But what about when the prompt requires more logical reasoning? That's where the process comes in:
-
Define tasks and success criteria. Many people start a prompt (or even an entire project) without knowing where they want to get to.
- Performance and precision: How well does the model need to perform? Sometimes a generic response already solves it.
- Latency: What's the acceptable response time? Larger models think more, but respond better. However, a short and practical response may be sufficient for the purpose.
- Price: What's the budget? Evaluate cost per call, model size, frequency of use.
-
Develop test cases: How to know if you're close to the ideal result?
- Create generic examples (80%) and some exceptions (edge cases).
-
Write the initial prompt based on the P.R.O.M.P.T structure.
-
Test with examples
- Evaluate results manually or use another LLM for this — even with improvement suggestions.
-
Refine the prompt based on results
- This is the cycle: 4, 5, 4, 5, 4, 5... until you get it right.
-
Put in production. When the prompt is reliable, ready — you can scale!