Red de Pods
Hablamos sobre la red que conecta los nodos, pero también hay otra capa de red que es crucial para el funcionamiento de los clusters, que es la red en la capa del pod.
Nuestro cluster de Kubernetes pronto tendrá un gran número de pods y servicios en ejecución.
¿Cómo son tratados los pods? ¿Cómo se comunican entre sí? ¿Cómo se accede a los servicios en ejecución en esos pods internamente, desde dentro del cluster, y externamente, desde fuera del cluster?
Kubernetes no viene con una solución integrada para esto, espera que implementes una solución de red que resuelva estos desafíos. Sin embargo, Kubernetes ha definido claramente los requisitos para la red de pods. Kubernetes espera que:
- cada pod obtenga su propia dirección IP exclusiva y que cada pod pueda alcanzar a todos los otros pods en el mismo nodo usando esa dirección IP.
- cada pod debe ser capaz de alcanzar a todos los otros pods en otros nodos también usando la misma dirección IP. No importa cuál es la dirección IP y a qué intervalo o subred pertenece.
Mientras puedas implementar una solución que se encargue de la asignación automática de direcciones IP y establezca la conectividad entre los pods en un nodo, así como entre los pods en nodos diferentes, no habrá problema.
Entonces, ¿cómo implementarías un modelo que cumpla estos requisitos?
Hay muchas soluciones de red disponibles que hacen esto, pero como es un estudio, vamos a intentar usar lo que aprendimos para resolver este problema nosotros mismos primero, lo que ayudará a entender cómo funcionan otras soluciones.
Vamos a imaginar que tenemos un cluster de tres nodos. No importa si es master o worker, pues todos ejecutan pods.
Los nodos forman parte de una red externa y tienen direcciones.
- master1 (192.168.0.1)
- worker1 (192.168.0.2)
- worker2 (192.168.0.3)
Cuando los contenedores son creados, el container runtime utilizado en los nodos de Kubernetes crea los network namespaces para ellos. Para permitir la comunicación entre ellos necesitamos conectar esos namespaces a una red bridge como vimos anteriormente.
Para respetar lo que el CNI definió necesitaríamos crear una interfaz bridge en cada nodo que debe pertenecer a una red diferente. Los contenedores necesitarían recibir IPs diferentes también.
Tendríamos entonces.
- master1 bridge 10.244.1.1 (red es 10.244.1.0/24)
- contenedores tendrían ip 10.244.1.2, 10.244.1.3, 10.244.1.4
- node1 bridge 10.244.2.1 (red es 10.244.2.0/24)
- contenedores tendrían ip 10.244.2.2, 10.244.2.3, 10.244.2.4
- node2 bridge 10.244.3.1 (red es 10.244.3.0/24)
- contenedores tendrían ip 10.244.3.2, 10.244.3.3, 10.244.3.4
Creamos una red en bridge en cada nodo, activamos la interfaz y asignamos una dirección IP y definimos el ip propuesto arriba.
Los pasos restantes deben ejecutarse para cada contenedor y siempre que un nuevo contenedor sea creado, por lo tanto, escribimos un script para eso.
En ese script tendríamos los siguientes pasos.
- Crear un pipe o un cable de red virtual. Creamos esto usando el comando ip link add.
- Conectar un extremo al contenedor y el otro extremo al bridge usando el comando ip link set.
- Asignar la dirección IP usando el comando ip addr y agregamos una ruta al gateway predeterminado. Pero ¿qué IP agregamos? Nosotros mismos gestionamos esto o almacenamos esas informaciones en algún tipo de base de datos. Por ahora, asumiremos que esta función toma un IP libre en la subred. Tomar un IP en la red bridge que no esté siendo usado.
- Activar las interfaces creadas
Los contenedores en el mismo nodo pueden comunicarse entre sí ahora dentro del mismo nodo.
Copiamos el script a los otros nodos y ejecutamos el script en ellos para asignar la dirección IP y conectar esos contenedores a sus propias redes internas. Resolvimos la primera parte del desafío. Todos los pods reciben su propia dirección IP exclusiva y pueden comunicarse entre sí en sus propios nodos.
La próxima parte es permitir que alcancen otros pods en otros nodos. Digamos, por ejemplo, que el pod está en 10.244.2.2 en node1 y desea hacer ping al pod 10.244.3.2 en node2.
Hasta el momento, el primero no tiene idea de dónde está la dirección 10.244.3.2 porque está en una red diferente de la suya.
Por lo tanto, lo envía al IP del bridge, pues está configurado como el gateway predeterminado. El nodo uno tampoco sabe ya que 10.244.2.2 es una red privada en el nodo dos.
Agregue una ruta a la tabla de enrutamiento del nodo uno para enrutar el tráfico a 10.244.2.2 en donde el IP del segundo nodo es 192.168.1.12.
Después de que se agrega la ruta, el pod azul puede hacer ping.
En lugar de configurar rutas en cada servidor, una solución mejor es hacerlo en un router, si hay uno en tu red, e indicar a todos los hosts que lo usen como gateway predeterminado. De esta manera, puedes gestionar fácilmente las rutas para todas las redes en la tabla de enrutamiento del router.
Con esto, las redes virtuales individuales que creamos con la dirección 10.244.1.0/24 en cada nodo ahora forman una única red grande con la dirección 10.244.0.0/16.
Es hora de unir todo.
Ejecutamos varios pasos manuales para preparar el ambiente con las redes bridge y las tablas de enrutamiento.
Luego, escribimos un script que puede ejecutarse para cada contenedor y que ejecuta los pasos necesarios para conectar cada contenedor a la red. Y ejecutamos el script manualmente.
Por supuesto que no queremos hacer esto en ambientes grandes donde miles de pods son creados cada minuto.
Entonces, ¿cómo ejecutamos el script automáticamente cuando un pod es creado en Kubernetes?
Es ahí donde el CNI entra, actuando como intermediario. El CNI informa a Kubernetes que es así como debes llamar a un script tan pronto como crees un contenedor.
Y el CNI nos dice: "Es así como debe ser tu script". Por lo tanto, necesitamos modificar un poco el script para cumplir con los estándares del CNI.
Debe tener una sección de adición (ADD) que se encargará de agregar un contenedor a la red y una sección de exclusión (DEL) que se encargará de excluir las interfaces del contenedor de la red y liberar la dirección IP, etc.
Por lo tanto, nuestro script está listo.
El container runtime en cada nodo es responsable de la creación de contenedores.
Siempre que un contenedor es creado, el container runtime examina la configuración del CNI pasada como argumento de línea de comando cuando fue ejecutado e identifica el nombre de nuestro script.
Luego, busca en el directorio bin de los CNIs para encontrar nuestro script y, después, ejecuta el script con el comando add y el nombre y el ID del namespace del contenedor, y nuestro script se encarga del resto.
Los plugins, scripts que hacen el trabajo repetitivo, están en /opt/cni/bin/
root@kind-cluster-worker:/etc/cni/net.d# ls -lha /opt/cni/bin
total 15M
drwxr-xr-x 2 root root 4.0K Feb 2 00:14 .
drwxr-xr-x 3 root root 4.0K Feb 2 00:14 ..
-rwxr-xr-x 1 root root 3.4M Feb 2 00:12 host-local
-rwxr-xr-x 1 root root 3.4M Feb 2 00:12 loopback
-rwxr-xr-x 1 root root 3.8M Feb 2 00:12 portmap
-rwxr-xr-x 1 root root 4.2M Feb 2 00:12 ptp
Y la configuración está en /etc/cni/net.d/. Si tuviera más de un archivo en esa carpeta, tomaría el primero según el orden lexicográfico.
root@kind-cluster-worker:/etc/cni/net.d# ls /etc/cni/net.d/
10-kindnet.conflist
Analizando ese archivo 10-kindnet.conflist que es un archivo de configuración de cni usado por kind
{
"cniVersion":"0.3.1",
"name":"kindnet",
"plugins":[
{
"type":"ptp",
"ipMasq":false,
"ipam":{
"type":"host-local",
"dataDir":"/run/cni-ipam-state",
"routes":[
{
"dst":"0.0.0.0/0"
}
],
"ranges":[
[
{
"subnet":"10.244.2.0/24"
}
]
]
},
"mtu":1500
},
{
"type":"portmap",
"capabilities":{
"portMappings":true
}
}
]
}
Pero vamos a intentar buscar dónde se muestra la configuración que apunta a ese cni.
¿Quién es responsable de la creación de contenedores en kubernetes? Kubelet, entonces es ahí donde necesitamos verificar.
El kubelet no se ejecuta como un pod, entonces vamos a ver el servicio que lo define.
root@kind-cluster-worker:/etc/systemd/system# cat /etc/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=http://kubernetes.io/docs/
ConditionPathExists=/var/lib/kubelet/config.yaml
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=1s
CPUAccounting=true
MemoryAccounting=true
Slice=kubelet.slice
KillMode=process
[Install]
WantedBy=multi-user.target
root@kind-cluster-worker:/etc/systemd/system#
#Vamos a mirar qué tenemos aquí ConditionPathExists=/var/lib/kubelet/config.yaml
root@kind-cluster-worker:/etc/systemd/system# cat /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
cgroupRoot: /kubelet
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionHard:
imagefs.available: 0%
nodefs.available: 0%
nodefs.inodesFree: 0%
evictionPressureTransitionPeriod: 0s
failSwapOn: false
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageGCHighThresholdPercent: 100
imageMaximumGCAge: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
root@kind-cluster-worker:/etc/systemd/system# ps -aux | grep kubelet
root 216 1.5 0.1 2998920 87512 ? Ssl Feb28 15:19 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///run/containerd/containerd.sock --node-ip=172.18.0.3 --node-labels= --pod-infra-container-image=registry.k8s.io/pause:3.9 --provider-id=kind://docker/kind-cluster/kind-cluster-worker --runtime-cgroups=/system.slice/containerd.service
root 10841 0.0 0.0 3324 1664 pts/1 S+ 14:51 0:00 grep kubelet
Ya que no encontramos nada, vamos a recrear nuestro cluster kind, pero ahora desactivando el cni default para instalar otro. Ya vamos a aprovechar para mejorar algunas cosas en la configuración que vamos a pasar a kind.
Desinstale el cluster anterior
kind delete cluster
Cree un archivo llamado king-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: cka-cluster
networking:
ipFamily: ipv4
disableDefaultCNI: true
kubeProxyMode: "ipvs"
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
kind create cluster --config kind-config.yaml
Creating cluster "cka-cluster" ...
✓ Ensuring node image (kindest/node:v1.29.1) 🖼
✓ Preparing nodes 📦 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-cka-cluster"
You can now use your cluster with:
kubectl cluster-info --context kind-cka-cluster
Thanks for using kind! 😊
# Nodos no listos
k get nodes
NAME STATUS ROLES AGE VERSION
cka-cluster-control-plane NotReady control-plane 34s v1.29.1
cka-cluster-worker NotReady <none> 13s v1.29.1
cka-cluster-worker2 NotReady <none> 11s v1.29.1
cka-cluster-worker3 NotReady <none> 12s v1.29.1
Y ahora vamos a instalar el [weave cni[(https://github.com/weaveworks/weave/releases)].
kubectl apply -f https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
serviceaccount/weave-net created
clusterrole.rbac.authorization.k8s.io/weave-net created
clusterrolebinding.rbac.authorization.k8s.io/weave-net created
role.rbac.authorization.k8s.io/weave-net created
rolebinding.rbac.authorization.k8s.io/weave-net created
daemonset.apps/weave-net created
kubectl get nodes
NAME STATUS ROLES AGE VERSION
cka-cluster-control-plane Ready control-plane 110s v1.29.1
cka-cluster-worker Ready <none> 89s v1.29.1
cka-cluster-worker2 Ready <none> 87s v1.29.1
cka-cluster-worker3 Ready <none> 88s v1.29.1
kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 4 4 4 4 4 kubernetes.io/os=linux 3m15s
weave-net 4 4 4 4 4 <none> 103s
Ahora vamos a verificar las cosas nuevamente.
root@cka-cluster-worker:/etc/cni/net.d# cat /etc/cni/net.d/10-weave.conflist
{
"cniVersion": "0.3.0",
"name": "weave",
"plugins": [
{
"name": "weave",
"type": "weave-net",
"hairpinMode": true
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"snat": true
}
]
}
# Tenemos plugins diferentes pues usamos weavenet en lugar de kindnet
root@cka-cluster-worker:/etc/cni/net.d# ls /opt/cni/bin/
host-local loopback portmap ptp weave-ipam weave-net weave-plugin-latest
ps -aux | grep kubelet
root 251 2.0 0.1 2998152 84476 ? Ssl 18:16 0:08 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///run/containerd/containerd.sock --node-ip=172.18.0.5 --node-labels= --pod-infra-container-image=registry.k8s.io/pause:3.9 --provider-id=kind://docker/cka-cluster/cka-cluster-worker --runtime-cgroups=/system.slice/containerd.service
Aún no encontramos nada. Analizando otros materiales de estudio vimos que en el service podríamos pasar los parámetros para avisar dónde está la carpeta del plugin.
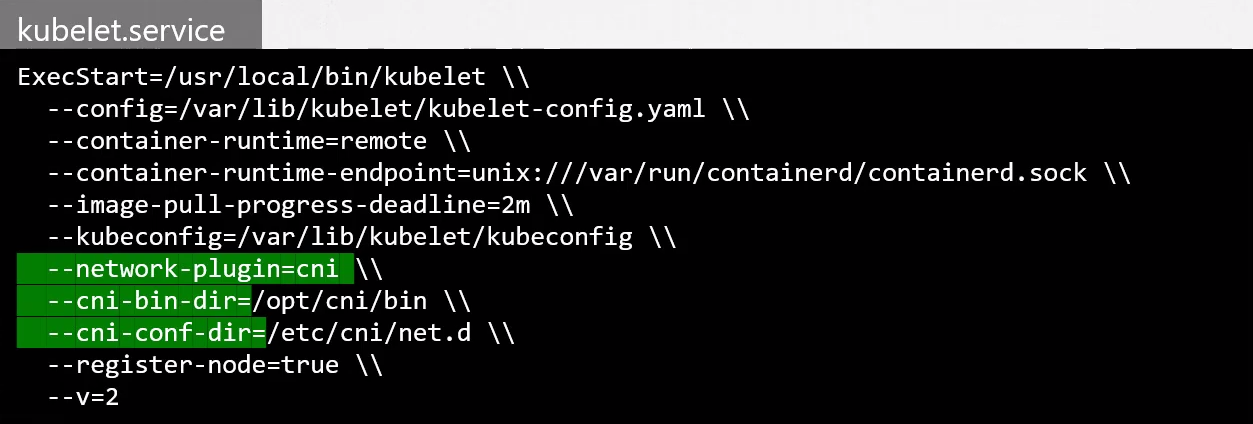
CNI Plugin
Vamos a profundizar mejor en una solución de CNI y los conceptos pueden aplicarse al resto. Vamos a tomar como ejemplo Weave.
La solución que usamos hasta ahora mapeaba qué redes están en qué hosts, mientras que cuando un paquete era enviado de un pod a otro, sigue el flujo de ir a la red, luego al router, luego al host y luego a otro pod. Pero esta solución no funciona bien con miles de pods y cientos de nodos. La tabla de enrutamiento puede no soportar tantas entradas y necesitamos ser creativos y encontrar nuevas soluciones.
Pensando en kubernetes como una empresa y los nodos como sucursales. Dentro de las sucursales tenemos diferentes sectores con diferentes departamentos. Si fuera dentro de la misma ciudad o en un país pequeño, podríamos crear un sistema de logística y contratar un office boy que llevaría los documentos de un lado a otro. Nadie necesita saber la dirección de las sucursales y pondríamos en las correspondencias solamente:
- Nombre de la sucursal
- Nombre del sector
- Nombre del departamento
- Nombre del destinatario
Si el office boy va en carro, autobús, moto, carro o bicicleta es problema de él. ¡Solo necesita entregar! Quien tiene que saber dónde es la dirección de las sucursales es él.
Si la empresa posee sucursales en diferentes países un office boy no es suficiente, entonces necesitaríamos mejorar nuestro sistema terciarizando el servicio de entrega. Entonces podemos contratar una empresa que colocará un agente responsable por cada país o área. Los documentos serían entregados siempre entre los agentes y estos son responsables de resolver la entrega dentro de su responsabilidad.
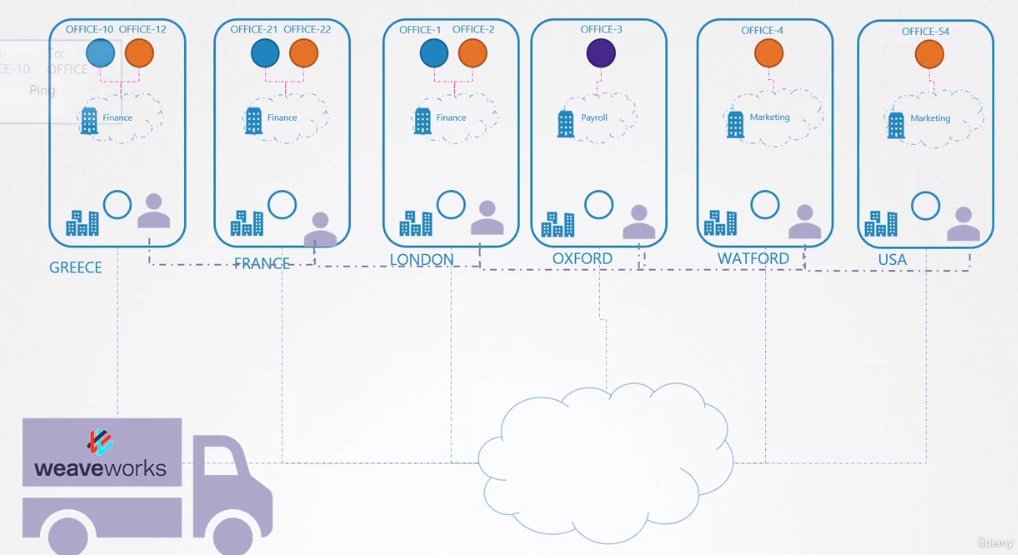
Volviendo a nuestro CNI, vimos arriba que Weavenet crea un daemonset, es decir, un pod (agente) por nodo (país). Esos agentes conocen la topología de toda la red pues se comunican entre sí. Se comunican entre sí para intercambiar información sobre los nodos, las redes y los pods dentro de ellos. Cada agente o par almacena una topología de toda la configuración. De esta manera, conocen los pods y sus IPs en los otros nodos. Weave crea su propio Bridge en los nodos con el nombre weave y asigna una dirección IP a cada red.
# WORKER-1
root@cka-cluster-worker:/# ip link show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether e2:0f:fd:ef:ad:fa brd ff:ff:ff:ff:ff:ff
root@cka-cluster-worker:/# ip addr show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether e2:0f:fd:ef:ad:fa brd ff:ff:ff:ff:ff:ff
inet 10.40.0.0/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
# WORKER-2 Vea que inicia con 10.32
root@cka-cluster-worker2:/# ip link show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 5e:56:a8:56:6e:f4 brd ff:ff:ff:ff:ff:ff
root@cka-cluster-worker2:/# ip addr show weave
5: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP group default qlen 1000
link/ether 5e:56:a8:56:6e:f4 brd ff:ff:ff:ff:ff:ff
inet 10.34.0.0/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
root@cka-cluster-worker2:/#
Recuerde que un único pod puede estar conectado a múltiples redes bridge. Todo depende de las rutas configuradas en los namespaces. Por ejemplo, puede tener un pod conectado al Weave Bridge, así como al Docker Bridge creado por Docker.
El camino que recorre un paquete para llegar a su destino depende de la ruta configurada en el contenedor.
Weave garantiza que los pods obtengan la ruta correcta configurada para alcanzar al agente, y el agente se encarga de los otros pods. Ahora, cuando un paquete es enviado de un pod a otro en otro nodo, Weave intercepta el paquete e identifica que está en una red separada, encapsulándolo en un nuevo paquete con nuevo origen y destino y enviándolo por la red. Del otro lado, el agente Weave recupera el paquete, lo desencapsula y lo envía al pod correcto.
Weave y los Weave Peers pueden implementarse como services o daemons en cada nodo del cluster manualmente o, si Kubernetes ya está configurado, una manera más fácil de hacer esto es implementarlos como pods en el cluster como hicimos con el apply en kind.
Cuando el sistema Kubernetes básico esté listo, con los nodos y la red configurados correctamente entre los nodos y los componentes básicos del plano de control implementados, Weave puede implementarse en el cluster con un único comando kubectl apply que implementa todos los componentes necesarios para Weave en el cluster. Lo más importante es que los pares de Weave se implementan como un conjunto de daemons.
kubectl get pods -A -n kube-system -o wide | grep weave
kube-system weave-net-29ffl 2/2 Running 4 (4h4m ago) 23h 172.18.0.2 cka-cluster-worker <none> <none>
kube-system weave-net-4q8kr 2/2 Running 4 (4h4m ago) 23h 172.18.0.4 cka-cluster-worker3 <none> <none>
kube-system weave-net-8zxbw 2/2 Running 5 (4h4m ago) 23h 172.18.0.3 cka-cluster-worker2 <none> <none>
kube-system weave-net-phbz8 2/2 Running 4 (4h4m ago) 23h 172.18.0.5 cka-cluster-control-plane <none> <none>
Una cosa importante es que cuando aplicamos el yaml de Weavenet es bueno verificar el CIDR en el configmap de kube-proxy y aplicar el mismo.
kubectl describe cm -n kube-system kube-proxy | grep CIDR
clusterCIDR: 10.244.0.0/16
excludeCIDRs: null
Si verificamos lo que viene por defecto en el yaml.
wget https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml
# Vamos a verificar las definiciones del contenedor weave en el ítem daemonset
cat weave-daemonset-k8s.yaml
# Removido para arriba
- apiVersion: apps/v1
kind: DaemonSet
metadata:
name: weave-net
labels:
name: weave-net
namespace: kube-system
spec:
# Removida esta parte para facilitar la lectura aquí!
containers:
- name: weave
command:
- /home/weave/launch.sh
env:
##############################################
# no tenemos una variable que defina el CIDR que vamos a usar entonces podemos colocar
- name: IPALLOC_RANGE # AGREGAR
value: 10.244.0.0/16
###############################################
- name: INIT_CONTAINER
value: "true"
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
Para fines de solución de problemas, visualice los registros usando el comando kubectl logs.