StatefulSet
El estudio para la certificación también sirve para mejorar los conocimientos. StatefulSet todavía no es cobrado en el examen, pero creo que futuramente será cobrado. Este es un estudio opcional que resolví documentar para fijar el contenido.
Muchas aplicaciones que deployamos vía Helm usan ese método. Vamos a entender el motivo.
Sabemos que:
- No podemos confiar en el IP de un pod. Si un pod morrer otro podrá ser creado con un IP completamente diferente.
- No podemos garantizar que un pod creado por un deployment tendrá un nombre específico, pues toda vez que un pod es creado él recibe un nombre randómico. Tenemos un nombre que comienza con el nombre del deployment adicionado al número del ReplicaSet que es randómico y después un número randómico en el final que definirá el pod.
- No existe una orden para la creación de las réplicas. Ellas son creadas todas de forma paralela.
Si precisamos crear una aplicación que a pesar de tener 3 réplicas una depende de la otra ¿cómo haríamos? Un ejemplo de eso es una base de datos.
Precisamos que el primero sea el master y otros slaves que apuntan para el master.
Las configuraciones de otras réplicas dependen de la primera que será el nuestro master.
Los slaves hacen una sincronización con el master y precisan apuntar para él, luego el master no puede cambiar de nombre. Si el master para él precisa volver con el mismo nombre.
Todos esos problemas son resueltos usando StatefulSet.
En el StatefulSet los nombres son dados como pod-0, pod-1, pod-2 en secuencia garantizando que no existan nombres randómicos.
Una réplica solamente inicia cuando la anterior termina de inicializar.
Vamos a observar una implantación de un banco MySQL.
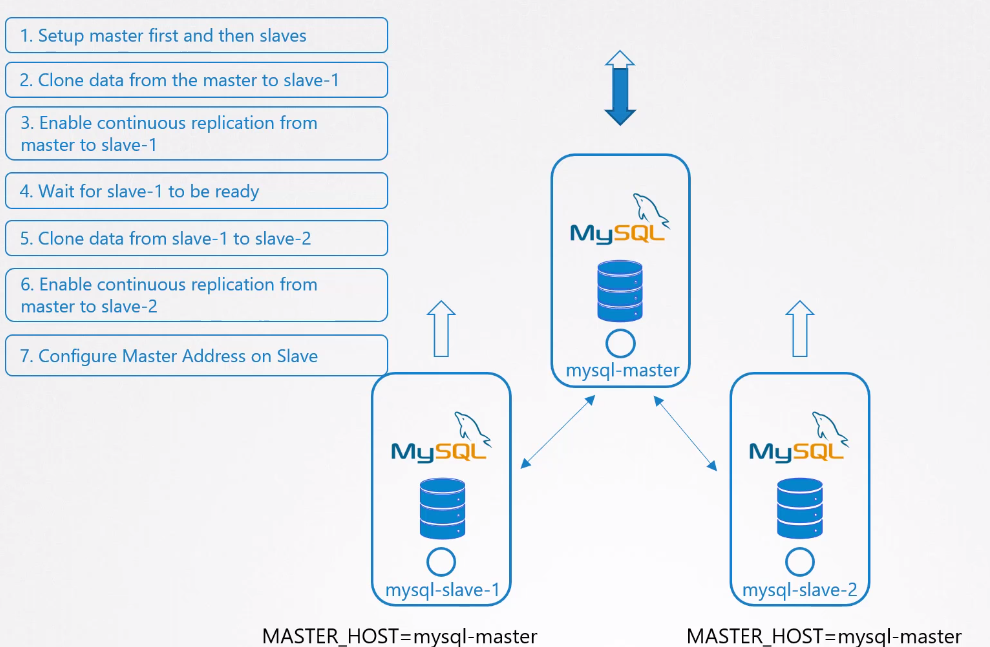
Primero precisamos crear el master. Después precisamos crear el primer slave haciendo la replicación de los datos del master. Después precisamos crear el segundo slave que apunta para el master, pero para evitar carga en el master hacemos la replicación de los datos a partir del primer slave.
Varias aplicaciones que usamos como Jaeger, Vault, bases de datos, poseen ese tipo de comportamiento. Por eso vale la pena entender un poco sobre StatefulSet. El uso es bien específico, y usado solamente en algunos escenarios. La gran mayoría de las aplicaciones puede trabajar como deployments.
StatefulSets pueden hacer scale up, scale down, rolling updates, rollback, etc, así como los deployments. La diferencia está en los items mencionados anteriormente que garantizan una orden y nombres fijos.
El template para StatefulSet es exactamente el mismo que el de deployments con apenas una diferencia. Es necesario apuntar el serviceName.
Vamos a crear un StatefulSet simple del MySQL.
kubectl create deployment mysql --image mysql --replicas 3 --dry-run=client -o yaml > mysql.yaml
# Vamos ya mostrar el archivo editado
cat mysql.yaml
apiVersion: apps/v1
#kind: Deployment
kind: StatefulSet
metadata:
creationTimestamp: null
labels:
app: mysql
name: mysql
spec:
replicas: 3
selector:
matchLabels:
app: mysql
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: mysql
spec:
containers:
- image: mysql
name: mysql
resources: {}
serviceName: mysql-headless
Vamos a aplicar y observar lo que acontece.