StatefulSet
O estudo para a certificação também serve para melhorar os conhecimentos. StatefulSet ainda não é cobrado no exame, mas acredito que futuramente será cobrado. Este é um estudo opcional que resolvi documentar para fixar o conteúdo.
Muitas aplicações que deployamos via Helm usam esse método. Vamos entender o motivo.
Sabemos que:
- Não podemos confiar no IP de um pod. Se um pod morrer outro poderá ser criado com um IP completamente diferente.
- Não podemos garantir que um pod criado por um deployment terá um nome específico, pois toda vez que um pod é criado ele recebe um nome randômico. Temos um nome que começa com o nome do deployment adicionado ao número do ReplicaSet que é randômico e depois um número randômico no final que definirá o pod.
- Não existe uma ordem para a criação das réplicas. Elas são criadas todas de forma paralela.
Se precisamos criar uma aplicação que apesar de ter 3 réplicas uma depende da outra como faríamos? Um exemplo disso é um banco de dados.
Precisamos que o primeiro seja o master e outros slaves que apontam para o master.
As configurações de outras réplicas dependem da primeira que será o nosso master.
Os slaves fazem uma sincronia com o master e precisam apontar para ele, logo o master não pode mudar de nome. Se o master parar ele precisa voltar com o mesmo nome.
Todos esses problemas são resolvidos usando StatefulSet.
No StatefulSet os nomes são dados como pod-0, pod-1, pod-2 em sequência garantindo que não existam nomes randômicos.
Uma réplica somente inicia quando a anterior termina de inicializar.
Vamos observar uma implantação de um banco MySQL.
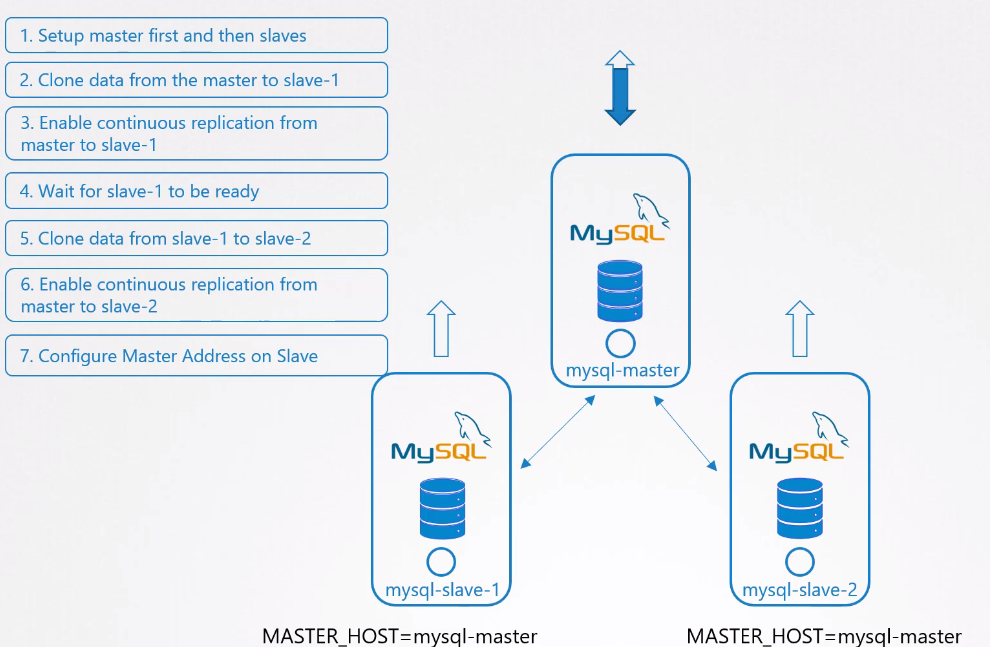
Primeiro precisamos criar o master. Depois precisamos criar o primeiro slave fazendo a replicação dos dados do master. Depois precisamos criar o segundo slave que aponta para o master, mas para evitar carga no master fazemos a replicação dos dados a partir do primeiro slave.
Várias aplicações que usamos como Jaeger, Vault, bancos de dados, possuem esse tipo de comportamento. Por isso vale a pena entender um pouco sobre StatefulSet. O uso é bem específico, e usado somente em alguns cenários. A grande maioria das aplicações pode trabalhar como deployments.
StatefulSets podem fazer scale up, scale down, rolling updates, rollback, etc, assim como os deployments. A diferença está nos itens mencionados anteriormente que garantem uma ordem e nomes fixos.
O template para StatefulSet é exatamente o mesmo que o de deployments com apenas uma diferença. É necessário apontar o serviceName.
Vamos criar um StatefulSet simples do MySQL.
kubectl create deployment mysql --image mysql --replicas 3 --dry-run=client -o yaml > mysql.yaml
# Vamos já mostrar o arquivo editado
cat mysql.yaml
apiVersion: apps/v1
#kind: Deployment
kind: StatefulSet
metadata:
creationTimestamp: null
labels:
app: mysql
name: mysql
spec:
replicas: 3
selector:
matchLabels:
app: mysql
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: mysql
spec:
containers:
- image: mysql
name: mysql
resources: {}
serviceName: mysql-headless
Vamos aplicar e observar o que acontece.