StatefulSet
The study for certification also serves to improve knowledge. StatefulSet is not yet covered in the exam, but I believe it will be covered in the future. This is an optional study that I decided to document to consolidate the content.
Many applications we deploy via Helm use this method. Let's understand why.
We know that:
- We can't rely on a pod's IP. If a pod dies, another can be created with a completely different IP.
- We can't guarantee that a pod created by a deployment will have a specific name, because every time a pod is created it receives a random name. We have a name that starts with the deployment name plus the ReplicaSet number which is random, and then a random number at the end that will define the pod.
- There is no order for replica creation. They are all created in parallel.
If we need to create an application that despite having 3 replicas, one depends on the other, how would we do it? An example of this is a database.
We need the first one to be the master and others to be slaves that point to the master.
The configurations of other replicas depend on the first one which will be our master.
The slaves synchronize with the master and need to point to it, so the master cannot change its name. If the master stops, it needs to come back with the same name.
All these problems are solved using StatefulSet.
In StatefulSet, names are given as pod-0, pod-1, pod-2 in sequence, ensuring there are no random names.
A replica only starts when the previous one finishes initializing.
Let's observe a MySQL database deployment.
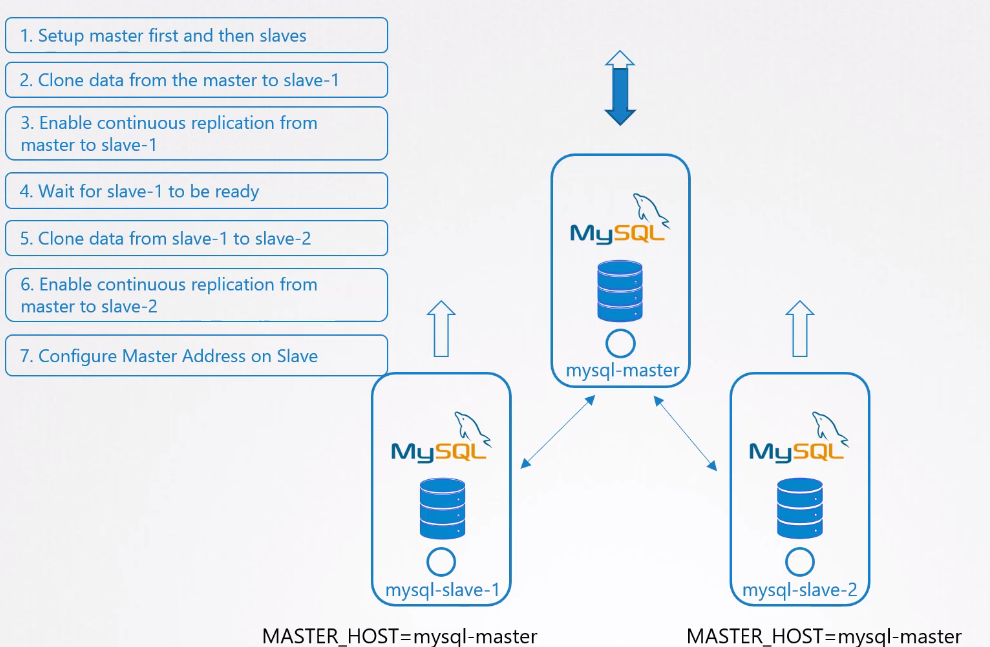
First, we need to create the master. Then we need to create the first slave by replicating data from the master. Then we need to create the second slave that points to the master, but to avoid load on the master, we replicate the data from the first slave.
Many applications we use like Jaeger, Vault, databases, have this type of behavior. That's why it's worth understanding a bit about StatefulSet. The use is very specific, and used only in some scenarios. The vast majority of applications can work as deployments.
StatefulSets can scale up, scale down, do rolling updates, rollback, etc., just like deployments. The difference is in the items mentioned earlier that ensure order and fixed names.
The template for StatefulSet is exactly the same as for deployments with only one difference. You need to specify the serviceName.
Let's create a simple MySQL StatefulSet.
kubectl create deployment mysql --image mysql --replicas 3 --dry-run=client -o yaml > mysql.yaml
# Let's show the edited file
cat mysql.yaml
apiVersion: apps/v1
#kind: Deployment
kind: StatefulSet
metadata:
creationTimestamp: null
labels:
app: mysql
name: mysql
spec:
replicas: 3
selector:
matchLabels:
app: mysql
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: mysql
spec:
containers:
- image: mysql
name: mysql
resources: {}
serviceName: mysql-headless
Let's apply and observe what happens.