Docker Swarm - Parte 1
Para comenzar este aprendizaje vamos a necesitar las máquinas limpias. Por eso, si estás siguiendo el estudio, vamos a destruir todo y crear desde cero.
❯ cd DCA/Environment
❯ vagrant destroy -f
❯ vagrant up
Docker Swarm es una herramienta de orquestación de contenedores que permite al usuario gestionar múltiples contenedores distribuidos en diversas máquinas hosts (clúster). Swarm no es la herramienta más utilizada hoy en día, perdió ante Kubernetes. Sin embargo, es bueno conocer al competidor, así como Nomad de Hashicorp. La mayoría de los conceptos que aprendas aquí funcionan para kubernetes.
Conceptos Básicos
Clúster
Un clúster es un grupo de hosts que proporciona la capacidad computacional para la orquestación de contenedores. Un clúster es la suma de la fuerza de todos sus nodos. El uso de clúster abarata el costo de la infraestructura. Una máquina extremadamente potente cuesta más que varias máquinas menos potentes juntas.
Escalado horizontal o Horizontal Scalinges cuando agregamos una máquina más (nodo) a nuestro clúster.Escalado Vertical o Vertical Scalinges cuando mejoramos la configuración de nuestra máquina.
Nodos
Un nodo es cada host (máquina/computadora) de un clúster. Un nodo puede ser master o worker.
- Los nodos masters son los nodos de control.
- Los nodos workers son donde se desplegarán efectivamente los contenedores.
Consenso
Raft Consensus es un algoritmo que implementa el protocolo de consenso que garantiza la confiabilidad del clúster. Docker utiliza este algoritmo y este sitio explica bien cómo funciona. Es este algoritmo el que garantiza el orden en el clúster. El consenso está en los nodos masters que tendremos en nuestro clúster para controlar los workers.
Los nodos masters pertenecientes a un clúster siempre estarán en alguno de los siguientes estados del Raft Consensus:
- Follower (seguidor, no da órdenes, solo sigue)
- Candidate (candidato a convertirse en líder)
- Leader (Líder)
En Raft Consensus cada nodo master tiene derecho a un voto para elegir un líder.
Si solo tienes un nodo, este inicia como seguidor, se candidatea para ser líder y como solo hay 1 para votar (él mismo) se convierte en líder.
Si tienes solamente un único nodo master y este cae, perderás el control del clúster, por eso es necesaria una redundancia de nodos masters en sistemas distribuidos. Como mencioné, todo nodo master entra como seguidor y si no encuentra un líder se candidatea, y el nodo que tenga mayor número de votos será el líder. Si el nodo master cae, los otros masters nuevamente entran en estado de candidatos y eligen un nuevo líder. El líder tiene el estado real del clúster, por eso necesita saber todo lo que pasa con los seguidores.
No es necesario entender cómo funciona la elección, solamente el número de nodos masters para tener una redundancia en caso de que el líder quede offline.
La fórmula de tolerancia es (N-1)/2 fallos y necesita un quórum de (N/2)+1. Quórum es la cantidad mínima de nodos para garantizar la mayoría.
| Nodos | Quórum | Tolerancia Fallo |
|---|---|---|
| 1 | (1/2)+1 = 1.5 | (1-1)/2 = 0 |
| 2 | (2/2)+1 = 2 | (2-1)/2 = 0.5 |
| 3 | (3/2)+1 = 2.5 | (3-1)/2 = 1 |
| 4 | (4/2)+1 = 3 | (4-1)/2 = 1.5 |
| 5 | (5/2)+1 = 3.5 | (5-1)/2 = 2 |
| 6 | (6/2)+1 = 4 | (6-1)/2 = 2.5 |
| 7 | (7/2)+1 = 4.5 | (7-1)/2 = 3 |
*Podemos observar que necesita ser impar a partir de 3 para tener al menos 1 redundancia. Trabajar con pares es pérdida de tiempo y recursos.
Los estudios muestran que la replicación de datos consume mucha red y procesamiento. Por lo tanto, 3 es suficiente, 5 es una buena elección, 7 comienza a empeorar y 9 empeora el rendimiento. Dice la leyenda que quien tiene 1 no tiene ninguno, entonces mínimo 3 por favor.
Creando el clúster
Para nuestro laboratorio, prepara una terminal para cada máquina (master, worker1, worker2). Verifica si docker está funcionando con el comando docker container ls
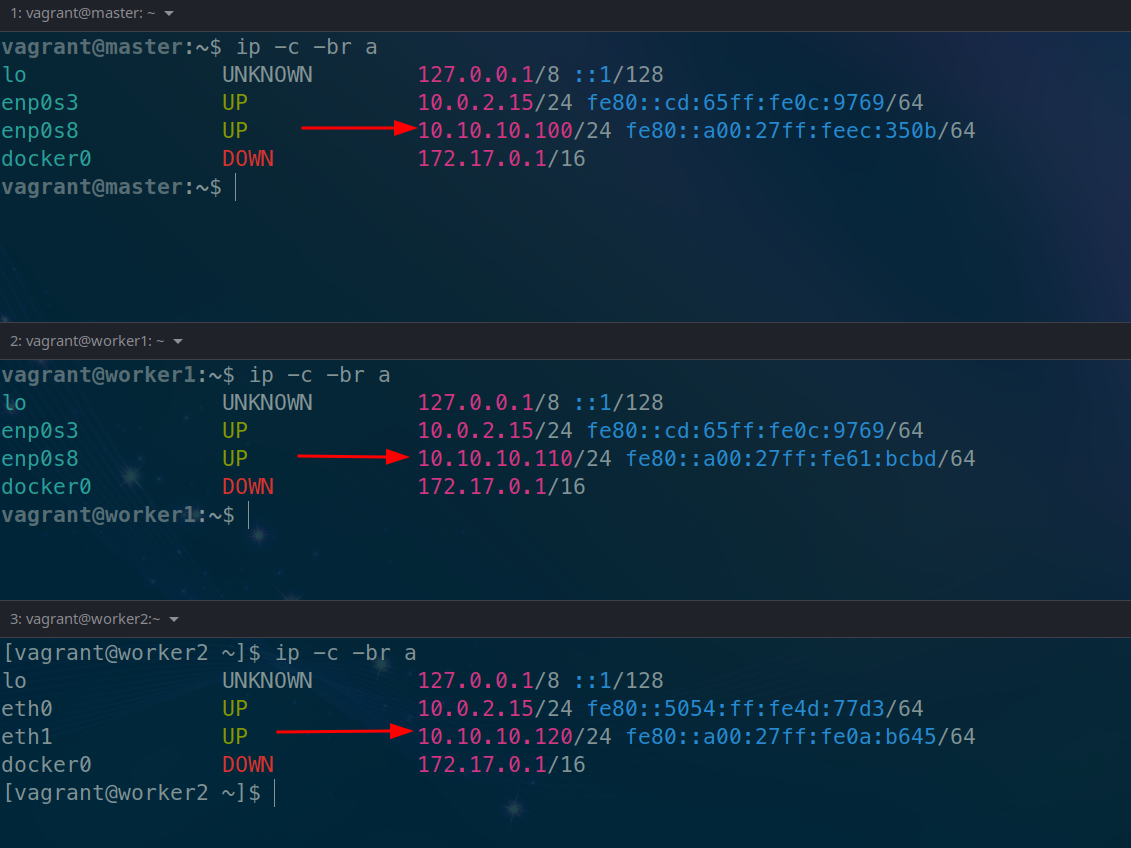
Verifica las IPs de las máquinas
Para crear el clúster basta con iniciarlo en la máquina master. Recuerda que debes pasar la IP que tiene.
# El advertise significa que anunciará la dirección pasada para comunicarse con el clúster.
vagrant@master:~$ docker swarm init --advertise-addr 10.10.10.100
Swarm initialized: current node (jdmwyhbti8s3fnmd17lw79rhw) is now a manager.
To add a worker to this swarm, run the following command:
# Observa que ya dio el comando para la entrada de los nodos workers
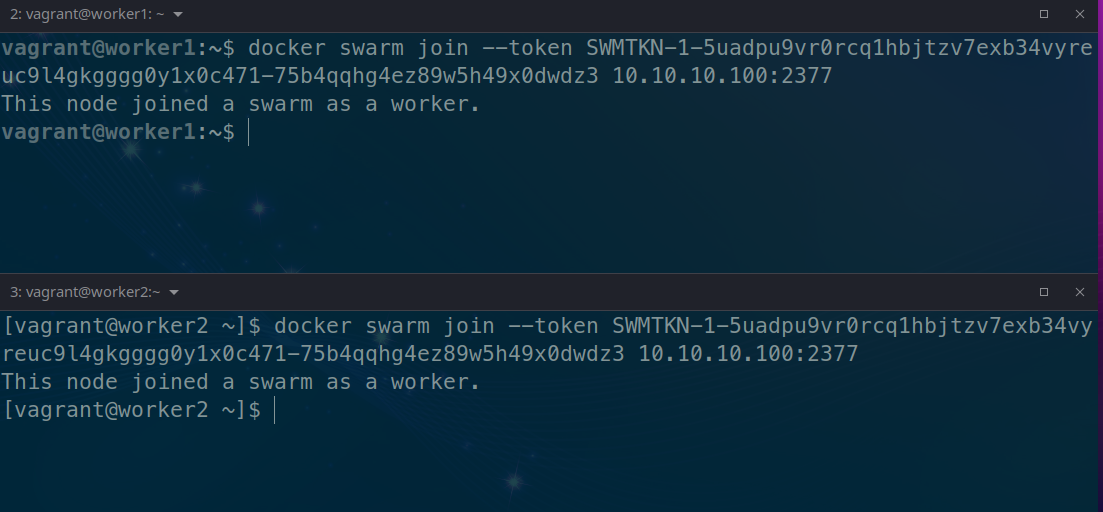
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-75b4qqhg4ez89w5h49x0dwdz3 10.10.10.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
vagrant@master:~$
¿Es posible utilizar el hostname de la máquina para iniciar el clúster? Sí, pero no es una buena práctica, ya que si el DNS falla genera un problema. La forma más segura es usar la IP.
Ejecutando el comando anterior en los nodos para unirlos al clúster
Verificando los nodos en el master...
vagrant@master:~$ docker node ls
# Observa que existe el estado de líder (leader status) y disponibilidad (availability)
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
Apagando la máquina para verificar si el estado cambia
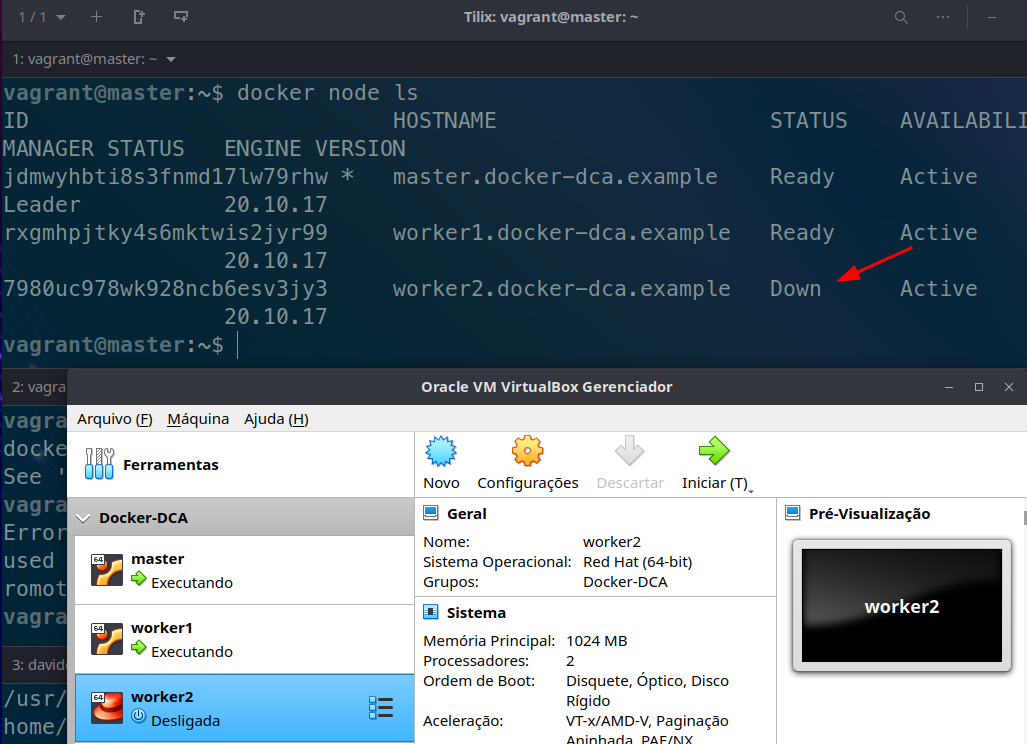
Los comandos
docker nodeestán limitados a los masters.
Un nodo worker puede ser promovido a master si se desea y también degradado.
vagrant@master:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
# con el comando promote pasando el hostname de la máquina
vagrant@master:~$ docker node promote worker1.docker-dca.example
Node worker1.docker-dca.example promoted to a manager in the swarm.
vagrant@master:~$ docker node ls
# Observa que alcanzó el estado de Reachable (alcanzable)
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active Reachable 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
# Ahora degradando y devolviendo el nodo a worker con el comando demote
vagrant@master:~$ docker node demote worker1.docker-dca.example
Manager worker1.docker-dca.example demoted in the swarm.
vagrant@master:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jdmwyhbti8s3fnmd17lw79rhw * master.docker-dca.example Ready Active Leader 20.10.17
rxgmhpjtky4s6mktwis2jyr99 worker1.docker-dca.example Ready Active 20.10.17
7980uc978wk928ncb6esv3jy3 worker2.docker-dca.example Ready Active 20.10.17
vagrant@master:~$
Haz algunas pruebas promoviendo a todos a master y apagando uno para ver la elección de un nuevo líder.
Luego apaga una máquina más y verás que no consigue elegir con dos, ocurriendo el problema del split brain donde una máquina sola no tiene la mayoría, no sabe si cayó ella o la otra y pierde el control del clúster.
El comando para obtener el token en caso de que no lo recuerdes
vagrant@master:~$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-7wzw0dvnf6rboj7jiev31rnm3 10.10.10.100:2377
vagrant@master:~$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5uadpu9vr0rcq1hbjtzv7exb34vyreuc9l4gkgggg0y1x0c471-75b4qqhg4ez89w5h49x0dwdz3 10.10.10.100:2377
Puertos Utilizados
Algunos puertos necesitan estar disponibles
| Puerto | Protocolo | Uso |
|---|---|---|
| 2377 | tcp | Comunicaciones de gestión del clúster |
| 7946 | tcp y udp | Comunicación entre nodos |
| 4789 | udp | Tráfico de red overlay |