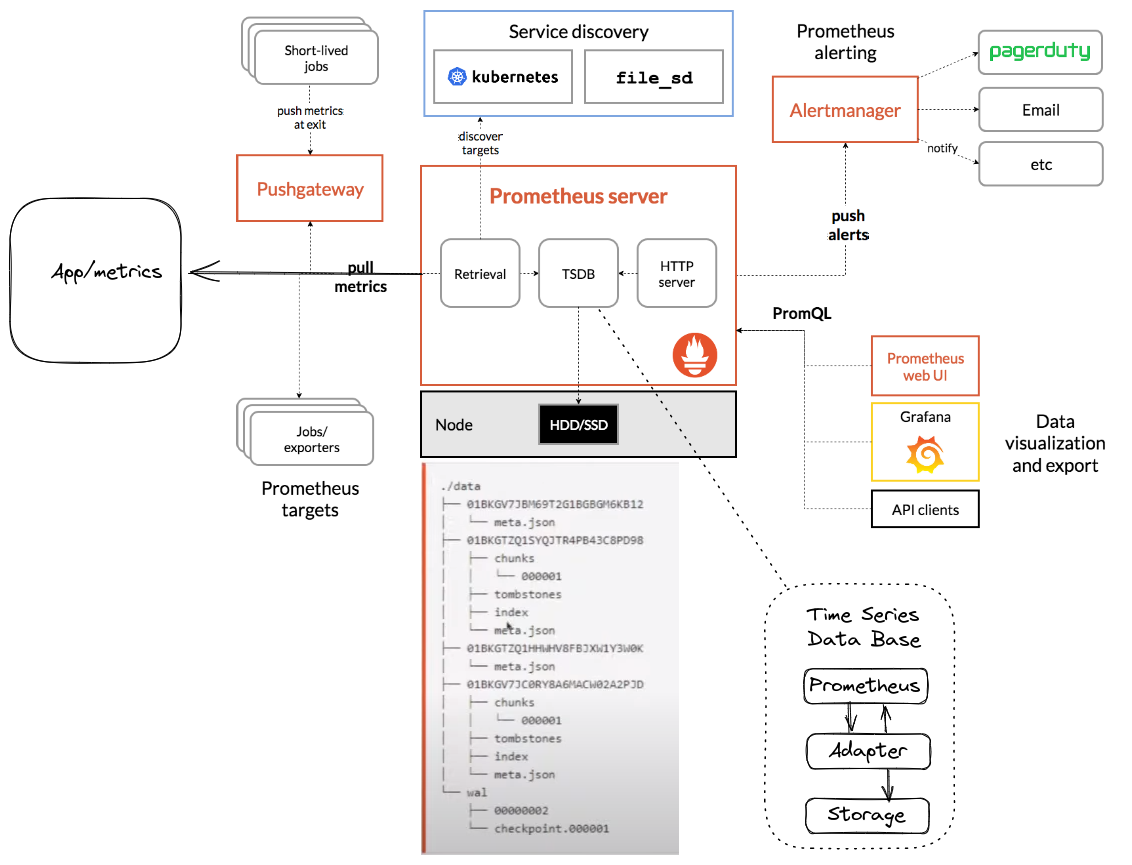
Arquitectura de Prometheus
Prometheus trabaja de forma activa, él es quien va hasta un endpoint expuesto por la aplicación para buscar las métricas mediante pull. Sin embargo, estas métricas deben estar correctamente formateadas para entrar en la TSDB (Time Series Database).
Generalmente en otras herramientas, es la aplicación quien envía los datos mediante push.
Servidor Prometheus
Dentro del servidor Prometheus tenemos los siguientes elementos:
- TSDB
- Retrieval
- HTTP (PromQL)
TSDB (Time Series Database)
https://prometheus.io/docs/prometheus/latest/storage/
Se utiliza para almacenar los datos de métricas.
Prometheus incluye una base de datos de series temporales local en disco, pero también se integra opcionalmente con sistemas de almacenamiento remoto.
Prometheus por defecto (se puede configurar) separa los archivos en bloques de dos en dos horas y consigue guardar sus valores recopilados en diferentes archivos. Cada bloque de dos horas consiste en un directorio que contiene un subdirectorio de chunks conteniendo todas las muestras de series temporales para esa ventana de tiempo, un archivo de metadatos y un archivo de índice (que indexa nombres de métricas y etiquetas para series temporales en el directorio de chunks). Las muestras en el directorio chunks se agrupan en uno o más archivos de segmento de hasta 512 MB cada uno por defecto. Cuando las series se eliminan mediante la API, los registros de eliminación se almacenan en archivos de eliminación separados (en lugar de eliminar los datos inmediatamente de los segmentos del bloque).
Separar mejora el rendimiento y disminuye el consumo de memoria, pues no habrá un archivo tan grande ocupando espacio.
El bloque actual para las muestras recibidas se mantiene en memoria y no es totalmente persistente. Está protegido contra caídas por un log write-ahead (WAL) que puede reproducirse cuando el servidor Prometheus se reinicie.
Observe que una limitación del almacenamiento local es que no está agrupado ni replicado. Se sugiere el uso de RAID para disponibilidad de almacenamiento y se recomiendan snapshots para backup.
También es posible utilizar otras bases de datos en lugar de guardar en archivo. Para ello es necesario el uso de un adaptador según la base de datos donde vayas a guardar los datos. Sin embargo, existe una pérdida de rendimiento y eficiencia.
Con el paso del tiempo, los bloques de dos horas se compactan en bloques más largos, generalmente 31 días. Esta compactación es lo que causa una pérdida de precisión en los datos recopilados.
Por eso Prometheus no se recomienda para métricas de negocio.
Retrieval
Responsable de ir a buscar las métricas en los jobs (aplicaciones). A continuación un ejemplo de cómo deben ser formateadas las métricas.
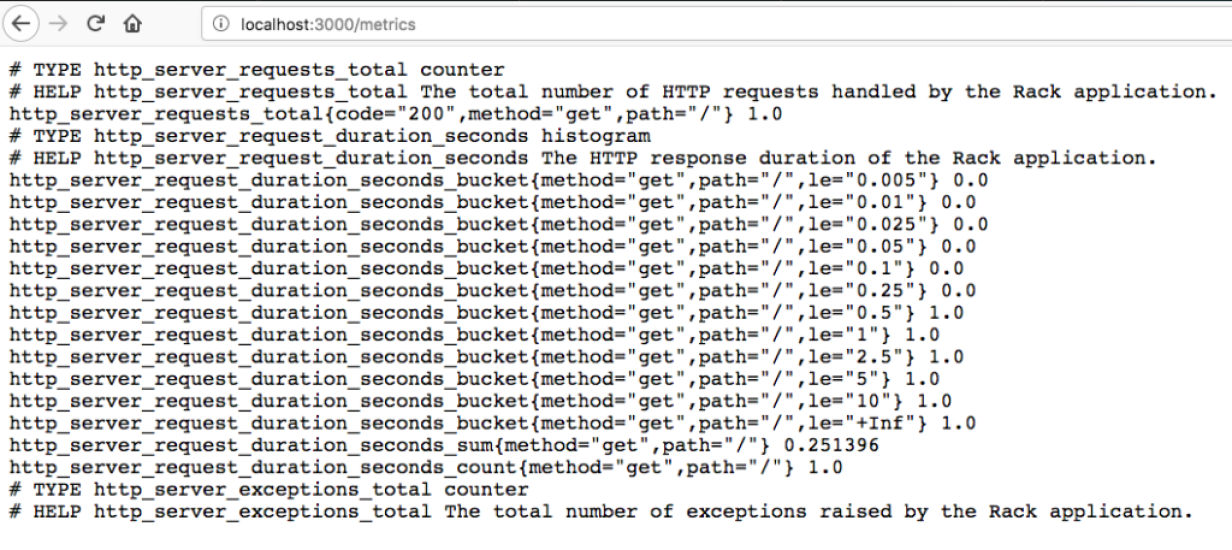
Varias bibliotecas en diferentes lenguajes dan soporte a esto. Consulta el enlace https://prometheus.io/docs/instrumenting/clientlibs/.
Además, existen bibliotecas listas como OpenTelemetry que pueden ser usadas.
Integración Nativa
Algunas herramientas del mercado ya poseen soporte nativo para Prometheus exponiendo endpoints de métricas para que Prometheus recopile las métricas.
- Grafana
- Docker
- Kubernetes
- Traefik
- Gitlab
- Netdata
- RabbitMQ
- Etcd
- ...
Exportadores
Cuando una herramienta no tiene soporte para Prometheus (no expone sus métricas, o no utilizan los estándares necesarios para Prometheus) usamos lo que llamamos exportadores para este escenario.
Los exportadores son procesos que van a recopilar las métricas de esas aplicaciones y exponerlas para que Prometheus recopile esas métricas.
Push Gateway
Cuando un proceso tiene una corta duración (Short-lived jobs) y no da tiempo a que Prometheus busque las métricas, utilizamos un recurso llamado Push Gateway. En este caso corresponde a ese proceso enviar sus métricas al push gateway y Prometheus las buscará en él funcionando como una caché.
Service Discovery
Para que el retrieval consiga encontrar los endpoints de aplicaciones que van cambiando de IP y escalando dinámicamente, Prometheus dispone de la funcionalidad de service discovery y da soporte a varios servicios como Kubernetes, Consul, etc. Esto es muy bueno para el escenario de microservicios.
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Servidor HTTP
Esta es la parte que hace la interacción de Prometheus con el usuario.
- WEB UI
- API
- Grafana o algún otro dashboard
AlertManager
No es responsabilidad de Prometheus entregar la alerta al usuario cuando esta suceda. Para ello utiliza otro sistema llamado AlertManager.
Observe que AlertManager es una aplicación aparte de Prometheus a la cual Prometheus envía una alerta y corresponde a él enviarla al usuario ya sea mediante Slack, Telegram, correo electrónico o alguna otra notificación push.
¿Puede Prometheus ser altamente disponible?
Sí, ejecuta servidores Prometheus idénticos en dos o más máquinas separadas. Las alertas idénticas serán deduplicadas por AlertManager.
Para alta disponibilidad de AlertManager puedes ejecutar múltiples instancias en un cluster Mesh y configurar los servidores Prometheus para enviar notificaciones a cada uno de ellos.