Arquitectura
Kafka es un sistema distribuido compuesto por servidores y clientes que se comunican por medio de un protocolo de red TCP de alto rendimiento.
Puede ser desplegado en hardware bare-metal, máquinas virtuales, contenedores locales o en ambientes de nube.
Servidores
Kafka se ejecuta como un cluster de uno o más servidores que pueden abarcar varios datacenters o regiones de nube. Algunos de esos servidores forman la capa de almacenamiento, llamados brokers. Otros servidores ejecutan Kafka Connect, que importa y exporta continuamente datos como flujos de eventos, integrando Kafka a sistemas existentes, como bases de datos y otros clusters Kafka. Para garantizar alta disponibilidad y confiabilidad, un cluster Kafka es altamente escalable y tolerante a fallos: si un servidor falla, los demás asumen su carga de trabajo, garantizando la continuidad de las operaciones sin pérdida de datos.
Clientes
Los clientes permiten que aplicaciones y microservicios distribuidos lean, graben y procesen flujos de eventos de manera paralela, escalable y tolerante a fallos, incluso ante problemas de red o fallos de máquina. Kafka incluye algunos clientes nativos y cuenta con diversas implementaciones proporcionadas por la comunidad.
Los clientes están disponibles para Java y Scala, incluyendo la biblioteca Kafka Streams, además de soporte para Go, Python, C/C++ y otros lenguajes, así como APIs REST.
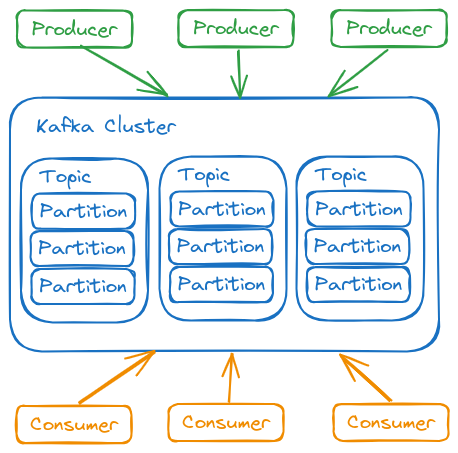
Componentes del Ecosistema
- Kafka Brokers
- Cada nodo de Kafka es llamado broker. Un cluster Kafka posee varios brokers.
- Es posible instalar múltiples brokers en la misma instancia alterando solo el puerto o en servidores diferentes utilizando el mismo puerto, pero con IP distinta.
- Asigna un número secuencial (offset) a los mensajes.
- Almacena los mensajes en disco.
- Los mensajes no necesitan ser consumidos inmediatamente.
- Permite recuperación de fallos de los consumidores (softwares que reaccionan a un evento).
- kafka client API
- kafka connect
- kafka streams
- kafka ksql
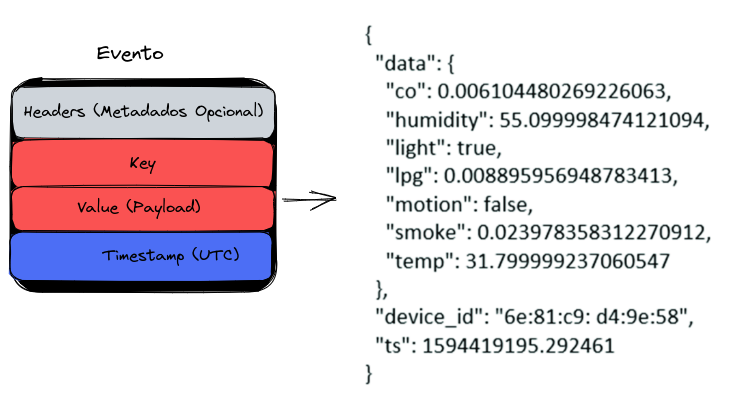
Evento
Un evento registra el hecho de que "algo sucedió" en el mundo o en tu empresa. Al leer o escribir datos en Kafka, eso se hace en forma de eventos. Conceptualmente, un evento posee:
- Una clave
- Un valor
- Un timestamp
- Es una buena práctica utilizar siempre el horario en UTC al producir eventos (producers), dejando el ajuste de la fecha/hora correcto para los consumidores, si es necesario.
- Cabeceras de metadatos opcionales.
El evento es el dato en sí, y muchas veces conocido como payload
Vea un ejemplo de evento:
- Clave del evento: "Alice"
- Valor del evento: "Hice un pago de $ 200 para Bob"
- Timestamp del evento: "25 de junio de 2020 a las 14h06"
Los eventos son organizados y almacenados de forma duradera en tópicos, así como en un foro de Internet. Quien tenga permiso puede leer los eventos en cualquier momento.
Muchas reglas pueden ser definidas para un tópico, pero generalmente la relación es N para N.
La key sirve para separar el contexto. Es posible crear un evento para un tópico que varios consumers suscriben.
Un determinado consumidor puede optar por leer solo mensajes de un tópico con una key específica y descartar el resto. Por ejemplo, un tópico TEMPERATURA, donde la key representa el nombre de la ciudad.
Tópico
Un tópico puede tener cero, uno o muchos productores que graban eventos en él, así como cero, uno o muchos consumidores que suscriben esos eventos.
No hay límite para el número de tópicos. Pueden ser creados conforme sea necesario.
Los eventos de un tópico pueden ser leídos cuantas veces sean necesarias. Diferentemente de los sistemas tradicionales de mensajes, los eventos no son excluidos después del consumo. En vez de eso, el tiempo de retención de los eventos es configurable por tópico. Después de ese período, eventos antiguos son descartados.
El rendimiento de Kafka es prácticamente constante, independientemente del volumen de datos almacenados. Por lo tanto, mantener datos por largos períodos es viable.
En muchos casos, un evento necesita ser procesado por múltiples consumidores. Por ejemplo, un evento puede registrar un depósito en la cuenta del cliente y, simultáneamente, generar una notificación informando la recepción del valor. Para garantizar que todos los consumidores procesan el mensaje antes de ser descartado, es posible configurar el tópico para retención condicional.
Un tópico funciona como un gran log. Kafka mantiene eventos por un período configurable (por defecto, 1 semana), pudiendo ser ajustado para más tiempo o incluso indefinidamente.
En el caso del tópico TEMPERATURA, donde la key representa una ciudad, podemos recuperar solo el último valor de la ciudad sin necesidad de procesar todo el histórico. Este recurso es llamado compact log. Kafka almacena todos los datos, pero los consumidores pueden recuperar solo el evento más reciente.
Particiones de un Tópico
Los tópicos son divididos en particiones, lo que significa que sus eventos son distribuidos entre múltiples brokers. Esto mejora la escalabilidad, pues permite que los clientes lean y graben datos simultáneamente en diferentes brokers.
Cuando un nuevo evento es publicado en un tópico, es anexado a una de sus particiones. Eventos con la misma key son siempre grabados en la misma partición, garantizando que cualquier consumidor leerá los eventos en el mismo orden en que fueron producidos.
Mensajes sin key son distribuidos en particiones de forma round robin.
Cada partición funciona como una cola FIFO. Como eventos con la misma key siempre son escritos en la misma partición, esto garantiza el orden de procesamiento. Cada evento posee un offset, que identifica su posición dentro de la partición.
Existe el offset 0 1 2 3 .. en todas las particiones de todos los tópicos. Por causa de esos offset separados, kafka consigue guardar cuál próximo mensaje cada consumer debe recibir en el orden correcto. Si un consumidor falla, kafka sabe de dónde paró.
La cantidad de particiones de un tópico debe ser definida en el momento de la creación y varía conforme el volumen de eventos esperados. Cuanto más particiones, mayor la capacidad de procesamiento paralelo.
Cada partición puede tener réplicas para garantizar alta disponibilidad. El factor de replicación define cuántas copias de una partición serán mantenidas en diferentes brokers. Si un broker falla, una réplica asume automáticamente.
La lectura ocurre siempre a partir de la partición líder, mientras las réplicas solo sincronizan los datos.
Si un broker que contiene una partición líder falla, una réplica es promovida a líder automáticamente.
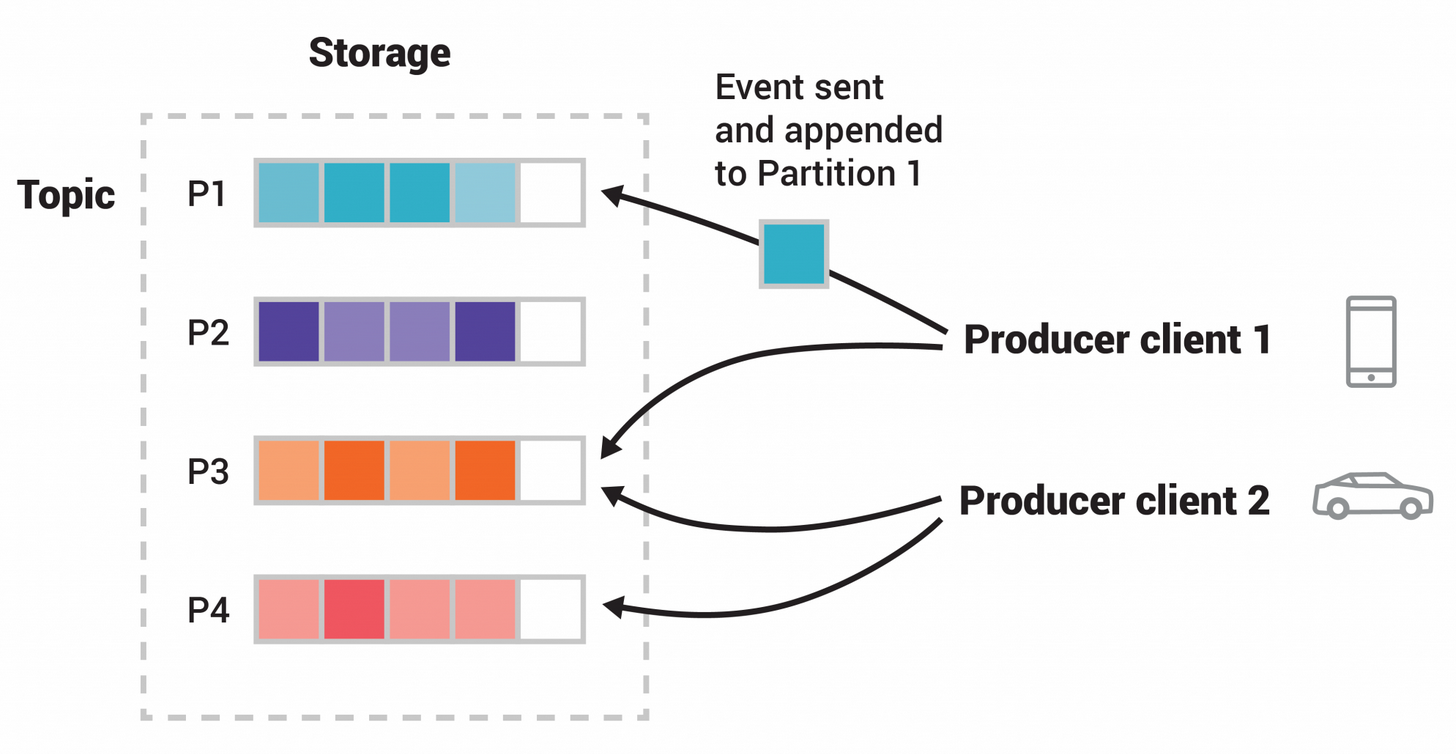
- Un tópico con 4 particiones
- Productores publican independiente uno del otro
- Cuadrados iguales indican eventos con el mismo ID por eso son grabados en la misma partición.
Es posible definir un factor de replicación para cada tópico. Si el factor es 1, la partición será creada en solo un broker y, si ese broker falla, los datos serán perdidos. En un cluster de 3 nodes, por ejemplo, un factor de replicación de 3 garantizaría copias en todos los brokers, aumentando la resiliencia del sistema.
Para garantizar disponibilidad en datos críticos, se recomienda al menos 2 réplicas por tópico.
Cada partición tiene un líder y réplicas (followers). Siempre se lee a partir de la partición líder, mientras las réplicas solo sincronizan datos. Si un broker con una partición líder falla, una réplica es promovida a líder. Tener más particiones no acelera la lectura – en ese caso, aumentar el número de consumidores es el abordaje correcto.
Segmentos de una partición de un tópico
Cada partición es dividida en segmentos, que son archivos físicos donde los eventos son almacenados. Esta división permite gestionar la retención de datos de manera eficiente.
Productores y Consumidores
Los productores son las aplicaciones cliente que publican (graban) eventos en Kafka
Los consumidores son aquellos que suscriben (leen y procesan) esos eventos.
Nada impide que un productor también sea un consumidor. Un evento puede generar otros eventos.
En Kafka, productores y consumidores son totalmente desacoplados y agnósticos uno del otro, lo que es un elemento de diseño clave para alcanzar la alta escalabilidad por el cual Kafka es conocido.
Por ejemplo, los productores nunca necesitan esperar por los consumidores. Kafka ofrece garantías como procesamiento de eventos exactamente una vez (exactly-once processing).
Un consumidor queda en ejecución continua, es decir, en un while true, aguardando nuevos mensajes.
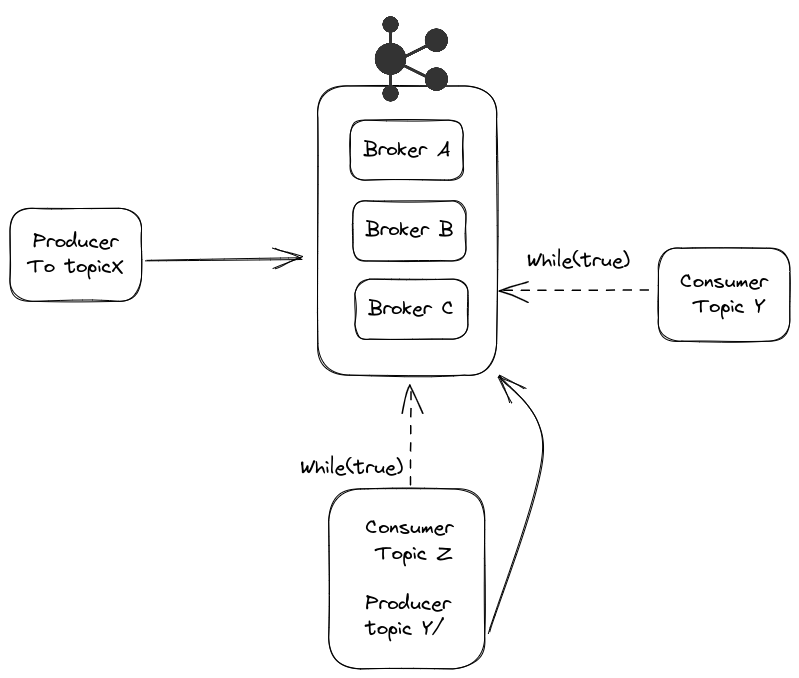
Un consumidor puede suscribir múltiples tópicos simultáneamente. Así, un único while true puede reaccionar a eventos de diferentes tópicos.
Brokers en Kafka
Un consumidor puede suscribir múltiples tópicos simultáneamente. Así, un único while true puede reaccionar a eventos de diferentes tópicos.
Cada broker almacena particiones de tópicos en su sistema de archivos local. Esas particiones son replicadas entre brokers para garantizar alta disponibilidad y tolerancia a fallos. Cuando una partición es replicada, un broker es designado como líder para esa partición, mientras otros brokers mantienen copias como seguidores (réplicas).
Para coordinar la sincronización entre los brokers y gestionar la distribución de particiones, Kafka utiliza Apache ZooKeeper (en las versiones más antiguas) o KRaft (Kafka Raft, en las versiones más recientes). Este mecanismo de coordinación:
- Elige líderes para particiones
- Gestiona la configuración del cluster
- Monitorea el estado de cada broker
- Mantiene el control de qué particiones están asignadas a qué brokers
Esta arquitectura distribuida permite que Kafka escale horizontalmente, agregando más brokers al cluster para aumentar la capacidad de procesamiento y almacenamiento sin interrumpir las operaciones.
Buena Práctica
Manipulación de Timestamps
Siempre almacene timestamps en UTC. El UTC (Tiempo Universal Coordenado) elimina ambigüedades relacionadas a zonas horarias y horario de verano. La responsabilidad de convertir para la zona horaria local debe quedar con la capa de presentación, que exhibirá el horario apropiado al usuario final.
Replicación de Datos
En ambientes de producción con Apache Kafka, una configuración estándar recomendada es utilizar un factor de replicación de 3. Esto significa que cada partición de un tópico será replicada en tres brokers diferentes dentro del cluster.
Esta estrategia de replicación:
- Garantiza alta disponibilidad de los datos
- Proporciona tolerancia a fallos (el sistema continúa operando incluso con el fallo de hasta dos brokers)
- Balancea rendimiento y confiabilidad
La replicación ocurre en el nivel de las particiones, permitiendo distribución eficiente de la carga y del almacenamiento por los brokers del cluster.