Desarrollo con Kafka
Además de los conceptos iniciales, para trabajar con Kafka debemos profundizar en cómo funciona. Será una visión amplia para que podamos entender mejor cómo utilizarlo.
Etapas en la Producción de Mensajes
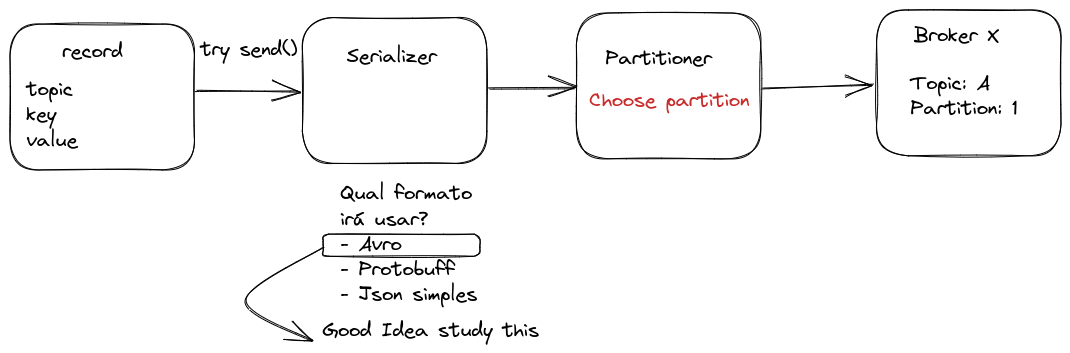
Una vez que se haya elegido el tópico, ya tengamos un valor, definamos si vamos o no a utilizar una clave (opcional para garantizar el orden), será necesario que el objeto pase por un proceso de serialización del mensaje que no es más que transformar la estructura en una secuencia de bytes.
En muchos sistemas de streaming, JSON es frecuentemente utilizado como formato para mensajes debido a su simplicidad y legibilidad. Sin embargo, para aplicaciones que requieren mayor control sobre tipos de datos, Apache Avro ofrece ventajas significativas. A diferencia de JSON convencional, AVRO implementa un sistema de esquemas fuertemente tipados que acompaña los datos serializados. Esto elimina ambigüedades comunes en JSON, donde, por ejemplo, un valor booleano como true podría ser interpretado incorrectamente como una cadena "true" por el consumidor, causando comportamientos inesperados y difíciles de depurar. Avro también proporciona mejor rendimiento, compactación más eficiente y soporta evolución de esquemas, convirtiéndolo en una elección superior para sistemas de producción que necesitan confiabilidad y eficiencia en la transmisión de datos.
No es necesario preocuparse en este momento por definir réplicas para el tópico y cantidad de particiones, etc., pues eso está en un momento de creación de los tópicos y no en el envío del mensaje.
Es posible configurar para que Kafka cree tópicos automáticamente con una especificación predeterminada cuando se produzca un mensaje para un tópico que no existe. Sin embargo, YO no considero que esto sea una buena práctica, pero depende mucho del objetivo del proyecto.
Garantía de entrega
Existen 3 formatos de entrega del mensaje:
-
Enviar un mensaje que puede perderse en el camino.
- Ej: Localización del conductor de Uber. Puedes perder uno u otro pues el mensaje es enviado cada 2 segundos, así que si recibimos 8 de 10 está óptimo.
- En este caso el
ACK=0. Se envía el mensaje y no se necesita confirmación de la entrega. - Más velocidad al costo de pérdidas.
-
Enviar un mensaje que puede ser leído más de una vez y no hace diferencia.
- Ej: Temperatura de la ciudad
- En este caso el
ACK=1. Al menos una confirmación espera recibir, aunque sea más de una. - Velocidad moderada con garantía de entrega.
-
Garantía que recibió solamente 1 vez.
- Ej: depósito o retiro bancario.
- En este caso el
ACK=-1. El productor envía el mensaje y aguarda confirmación de que fue replicado en todos los brokers que poseen réplicas de la partición. Solamente después que todas las réplicas confirmen la recepción, el mensaje es considerado "entregado" - Garantía total al costo de velocidad y rendimiento.
¡Trabaja con las opciones de garantía con sentido común!
Idempotencia
Existe un parámetro llamado Idempotent que puede estar ON u OFF en el productor para garantizar exactamente una entrega del mismo mensaje.
Kafka consigue descartar mensajes repetidos utilizando el timestamp y garantizar el orden correcto.
Consumer group
Kafka ofrece un mecanismo elegante para procesamiento paralelo a través de grupos de consumidores (consumer groups). Cuando múltiples consumidores pertenecen al mismo grupo y leen el mismo tópico, Kafka automáticamente distribuye las particiones entre ellos:
- Con un tópico de 3 particiones y un grupo de 3 consumidores: cada consumidor procesa exactamente 1 partición.
- Con un tópico de 3 particiones y un grupo de 2 consumidores: un consumidor procesa 2 particiones y el otro procesa 1 partición.
- Con un tópico de 2 particiones y un grupo de 3 consumidores: apenas 2 consumidores quedan activos procesando 1 partición cada uno, mientras el tercero permanece en estado inactivo
La configuración de un consumidor en Kafka es notablemente simple. Basta especificar el grupo de consumidores al cual pertenece el consumidor, y Kafka automáticamente:
- Asigna particiones apropiadas al consumidor
- Gestiona la suscripción de los tópicos
- Mantiene el control de los offsets consumidos
Kafka mantiene alta disponibilidad a través de rebalanceo automático. Si un consumidor falla, Kafka redistribuye sus particiones entre los consumidores restantes y si un nuevo consumidor es adicionado, Kafka reequilibra las asignaciones de particiones. Este proceso es transparente y no requiere intervención manual.
Para obtener máxima eficiencia, lo ideal es dimensionar el número de consumidores para corresponder al número de particiones, evitando tanto consumidores inactivos como sobrecargados.
Seguridad
Es posible cifrar todos los mensajes en tránsito entre producer <--> Kafka <--> consumer, pero, por defecto, los datos son almacenados en las particiones sin cifrado, exactamente como fueron producidos. Kafka garantiza apenas el cifrado en el transporte, pero los mensajes son descifrados al llegar al destino.
A partir de la versión 2.8.0, Kafka introdujo el Tiered Storage y adicionó soporte al cifrado de datos en reposo (Encryption at Rest) por medio de la integración con Key Management Systems (KMS), generalmente usado en clusters Kafka as a Service.
Si estás usando un cluster Kafka auto-gestionado, existen otras aproximaciones para garantizar la seguridad de los datos en reposo:
-
Cifrado a nivel de aplicación (End-to-End Encryption): El productor ya envía el mensaje cifrado, y solamente el consumidor con la clave correcta puede descifrarlo. Como el mensaje llega cifrado, también será almacenado de esa forma. Esta es la aproximación más segura y fácil de implementar.
-
Cifrado a nivel de disco: Configurar LUKS (Linux Unified Key Setup) para cifrar el disco donde los logs de Kafka son almacenados, garantizando que los datos queden protegidos incluso si el disco es accedido directamente.
Autenticación y Autorización
El Flujo de seguridad tiene dos etapas:
1️. Autenticación: El cliente (productor/consumidor) prueba su identidad (vía SASL, TLS, etc.). 2️. Autorización: Kafka verifica lo que el usuario puede hacer (vía ACLs o RBAC).
Autenticación
Apache Kafka ofrece diversos mecanismos para autenticación que sirven tanto para usuarios humanos como para service accounts (cuentas de servicio).
- PLAIN: Nombre de usuario y contraseña
- OAuth/OAUTHBEARER: Soporte para OAuth 2.0
- Es muy común en grandes empresas uso de SSO para usuarios que puede ser hecho con servicios como Okta, AD, Keycloak, Auth0
- SSL/TLS: Autenticación basada en certificados
- SCRAM: Autenticación con desafío-respuesta
- GSSAPI: Integración con Kerberos
Para service accounts, que son utilizadas en aplicaciones, generalmente se utiliza API tokens estáticos en las aplicaciones internas. Para uso externo podemos crear certificados específicos para service accounts de terceros, pero depende mucho del escenario, conocimiento del equipo y seguridad interna del control de esos API tokens y generación de los certificados.
Autorización
La autorización (Permisos) para una cuenta puede ser controlada a través de ACLs (Access Control Lists) o RBAC (Role-Based Access Control), dependiendo de la necesidad y de la distribución de Kafka que estamos utilizando.
¿Cuándo usar ACLs?
- Si estás usando Apache Kafka puro (auto-gestionado).
- Si necesitas control de acceso granular por usuario o servicio.
- Si quieres un modelo basado en permisos individuales en vez de funciones.
¿Cuándo usar RBAC (Role-Based Access Control)?
RBAC es un modelo de control basado en funciones, disponible en distribuciones empresariales de Kafka, como Confluent Kafka. En vez de definir permisos para cada usuario individualmente, asignas funciones que ya poseen permisos predefinidos.
- Si estás usando Confluent Kafka u otra distribución empresarial que soporte RBAC.
- Si quieres un modelo más escalable, agrupando usuarios por función.
- Si necesitas integrar Kafka con un IAM corporativo (como LDAP, Okta, Active Directory).
Con RBAC, puedes definir permisos globales para administración, producción, consumo y operaciones de cluster, lo que facilita la gestión en ambientes con muchos usuarios.
Explicaré con más detalles más adelante sobre cómo dar esos permisos.
Compatibilidad de Datos
Kafka, en su esencia, apenas transfiere datos en formato de bytes. No realiza ninguna validación o verificación de esos datos a nivel del cluster. En realidad, Kafka ni siquiera sabe qué tipo de información está siendo enviada o recibida.

Debido a la naturaleza desacoplada de Kafka, productores y consumidores no se comunican directamente. En vez de eso, el intercambio de informaciones acontece por medio de los tópicos de Kafka. Sin embargo, el consumidor aún necesita saber cuál es el formato de los datos enviados por el productor para poder deserializarlos correctamente. Ahora, imagina si el productor comenzara a enviar datos inválidos o alterara el tipo de dato sin aviso. Esto haría que los consumidores paren de consumir o hasta se rompan si no existe un tratamiento de error. Para evitar ese problema, es necesario un mecanismo que garantice un tipo de dato común y estandarizado entre productor y consumidor.
Es aquí que entra el **Schema Registry**. Es un servicio que funciona fuera del cluster Kafka, siendo responsable por la distribución y gestión de los schemas de datos. Almacena una copia de los esquemas en su cache local, garantizando que tanto productores como consumidores sigan la misma estructura.
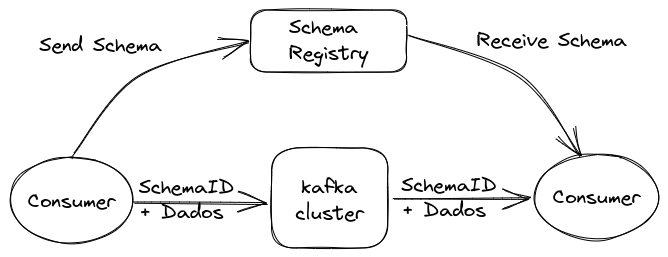
Con el Schema Registry en funcionamiento, el productor, antes de enviar los datos a Kafka, verifica si el esquema correspondiente ya está registrado. Si no está, lo registra en el Schema Registry y almacena en cache. Después de obtener el esquema correcto, el productor serializa los datos de acuerdo con él y los envía a Kafka en formato binario, incluyendo un ID único del esquema. Cuando el consumidor recibe ese mensaje, consulta el Schema Registry para recuperar el esquema correspondiente al ID y realiza la deserialización de los datos. Si hay una incompatibilidad, el Schema Registry retornará un error, informando que el esquema esperado fue violado.
¿Qué tipo de formato de serialización de datos debemos usar con Schema Registry? Algunos puntos importantes deben ser considerados al elegir el formato adecuado:
- Formato binario:
- Es más eficiente, reduciendo el uso de almacenamiento.
- Evita problemas de precisión numérica comunes en formatos de texto, como JSON.
- Uso de esquemas para validar estructura de datos.
- Permite garantizar que los datos escritos estén dentro del formato esperado, evitando incompatibilidades.
IDL (Interface Description Language) define estándares de mensaje
| Nombre | Binario | IDL | DESARROLLADOR | OBSERVACIÓN |
|---|---|---|---|---|
| JSON | NO | YES | No tipado | |
| YAML | NO | NO | No tipado | |
| XML | NO | YES | W3C | Muy Verboso |
| Kryo | NO | YES | Esoteric Software | Solo funciona en JVM |
| AVRO | YES | YES | Apache | Estándar de Confluent y mayor curva de aprendizaje |
| Protocol Buffer | YES | YES | Fácil de usar | |
| Thrift | YES | YES | Casi lo mismo que protocol buffer y más difícil de usar |
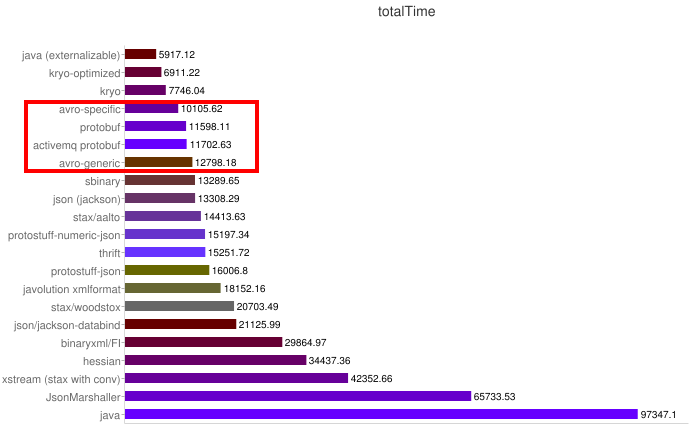
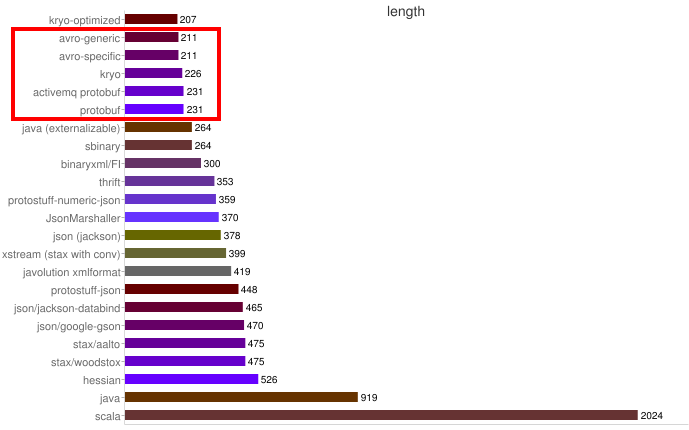
Algunos benchmarks:
Velocidad
Tamaño
AVRO
Un ejemplo de un schema AVRO:
{
"namespace": "pnda.entity",
"type": "record",
"name": "event",
"fields": [
{"name": "timestamp", "type": "long"},
{"name": "src", "type": "string"},
{"name": "host_ip", "type": "string"},
{"name": "rawdata", "type": "bytes"}
]
}
Características:
- Los formatos de datos son descritos escribiendo Avro Schemas, que están en JSON.
- Los datos pueden ser usados de forma genérica como Generic Records o con código compilado.
- Los datos guardados en archivos o transmitidos por una red generalmente contienen el propio esquema.
Pros
- Formato binario eficiente que reduce el tamaño de los registros.
- Los esquemas del lector y del escritor son conocidos, permitiendo grandes alteraciones en el formato de los datos.
- Lenguaje muy expresivo para escribir esquemas.
- Ninguna recompilación es necesaria para soportar nuevos formatos de datos.
Contras
- El formato Avro Schema es complejo y requiere estudio para aprender. Busca en el sitio que en algún momento hablaré sobre eso.
- Las bibliotecas Avro para serialización y deserialización son más complejas de aprender.
Útil cuando:
- Es muy importante minimizar el tamaño de los datos.
- Los formatos de datos están en constante evolución o incluso algo que los usuarios pueden usar.
- Son necesarias soluciones genéricas para problemas como almacenamiento de datos o sistemas de consulta de datos.
Protocol Buffer
Características:
- Los formatos de datos son descritos escribiendo archivos proto en un formato personalizado.
- Un compilador protobuf genera código en el lenguaje de programación elegido.
- Creas, serializas y deserializas tus datos usando el código generado.
Pros:
- Formato binario muy eficiente que reduce bytes.
- Representación JSON estándar.
- Código generado fuertemente tipado para acelerar el desarrollo.
Contras:
- Requiere recompilación cuando los formatos cambian.
- Es necesaria una disciplina rigurosa para mantener la compatibilidad con versiones anteriores cuando los formatos cambian.
Útil cuando:
- Es muy importante minimizar el tamaño de los datos
- Los formatos de datos no cambian con mucha frecuencia.
Yo particularmente me gusta más AVRO. A pesar de dar más trabajo, no es necesario un compilador.