Ecosistema Kafka
Kafka Connectors
Kafka Connect es un framework para integración de datos que facilita el movimiento de informaciones entre Kafka y sistemas externos, como bases de datos, servicios de almacenamiento y otras fuentes de datos. Simplifica la importación y exportación de datos sin la necesidad de escribir código personalizado para consumir o producir mensajes.
Kafka Connect usa conectores para comunicarse con diferentes sistemas. Existen dos tipos principales:
-
Source Connector (Conector de Origen) → Captura datos de fuentes externas (bases de datos, APIs, sistemas de mensajería) y los publica en tópicos de Kafka.
-
Sink Connector (Conector de Destino) → Consume datos de tópicos de Kafka y los envía a destinos como bases de datos, sistemas de análisis y almacenamiento distribuido.
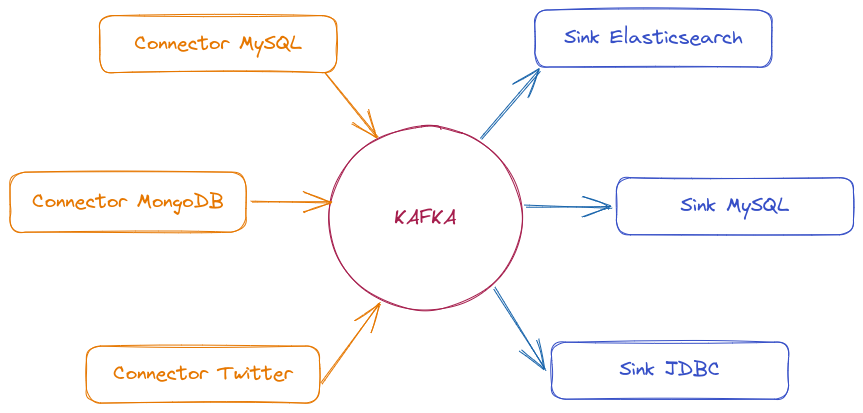
Hay muchos conectores disponibles para mover datos entre Kafka y otros sistemas de datos populares, como S3, JDBC, Couchbase, S3, Golden Gate, Cassandra, MongoDB, Elasticsearch, Hadoop y muchos más.
Ventajas:
- Facilidad de integración → Permite conectar diferentes sistemas con mínima configuración.
- Escalable y tolerante a fallos → Puede correr como un proceso único o en modo distribuido.
- Interfaz REST → Permite gestionar conectores vía API REST sin necesidad de tocar el código.
- Gestión automática de offsets → Kafka Connect gestiona los desplazamientos automáticamente, evitando problemas de reprocesamiento de mensajes.
- Procesamiento de datos en lote y streaming → Puede lidiar tanto con flujos continuos como con cargas en lote.
Kafka Connect no forma parte del cluster Kafka. Es un servicio separado que facilita la integración de datos, pero corre independientemente de Kafka.
No todos los conectores son gratuitos. Algunos son open-source, pero otros son mantenidos por empresas y exigen licenciamiento.
Podemos consultar esta lista para encontrar lo que necesitamos.
Kafka Rest Proxy
Kafka REST Proxy es un servicio que permite interactuar con Kafka por medio de una API REST, facilitando la producción y el consumo de mensajes sin la necesidad de utilizar bibliotecas o drivers específicos de Kafka.
¿Cuándo usar esto?
- Si tu aplicación no posee un cliente Kafka compatible, el REST Proxy permite enviar y consumir mensajes vía HTTP.
- Ideal para sistemas que ya utilizan APIs REST y no quieren adicionar dependencias específicas de Kafka.
- Cuando no hay necesidad de gestionar un Producer/Consumer manualmente dentro del código.
En vez de usar una biblioteca Kafka, puedes enviar mensajes a un tópico simplemente haciendo una petición HTTP:
curl -X POST "http://localhost:8082/topics/mi-topico" \
-H "Content-Type: application/vnd.kafka.json.v2+json" \
--data '{"records":[{"value":{"id":1, "mensaje":"¡Hola DevSecOps!"}}]}'
## Y para consumir
curl -X GET "http://localhost:8082/consumers/mi-grupo/instances/mi-instancia/records"
Ventajas:
- No necesitas gestionar conexiones o configurar consumidores/productores complejos.
- Funciona con cualquier lenguaje que soporte peticiones HTTP.
- Es más fácil probar y enviar mensajes manualmente vía curl o Postman.
Desventajas
- Mayor latencia pues las peticiones HTTP tienen más overhead que las conexiones nativas Kafka.
- No permite ajustes avanzados como particionamiento manual y configuraciones específicas de consumidores.
- Puede no ser ideal para sistemas de alto throughput.
Kafka Streams
Kafka Streams es una poderosa biblioteca Java para procesamiento y transformación de datos en tiempo real.
Para utilizar Kafka Streams, es necesario un consumer desarrollado en Java. Consume los datos, aplica las transformaciones deseadas y los republica en el formato adecuado.
Kafka Streams actúa simultáneamente como consumer y producer.
- Garantía de entrega "Exactly Once", evitando mensajes duplicados.
- Escalable y tolerante a fallos.
- Capacidad de agregación: permite operaciones como cálculos de promedio, suma y conteo.
- Procesamiento en tiempo real
KSQL (Kafka SQL)
KSQL es un lenguaje basado en SQL para procesar y consultar datos directamente en los tópicos de Kafka, sin la necesidad de escribir código Java u otro lenguaje de programación.
- Consultas en tiempo real permite filtrar, transformar y agregar datos directamente en los tópicos de Kafka.
- Evita la necesidad de desarrollar aplicaciones personalizadas para procesar mensajes.
- Puede mantener el estado de consultas y agregaciones sin necesidad de bases de datos externas.
- Funciona bien con formatos como AVRO, JSON y Protobuf, garantizando la consistencia de los datos.
KSQL trata los tópicos de Kafka como tablas o streams continuos de datos, permitiendo realizar operaciones como:
Por ejemplo si fuéramos a filtrar el tópico de pedidos. Imagina que tenemos los 3 mensajes abajo en el tópico:
{"id": 1, "cliente": "João", "valor": 90}
{"id": 2, "cliente": "Maria", "valor": 150}
{"id": 3, "cliente": "Carlos", "valor": 200}
Ejecutando el comando:
SELECT * FROM pedidos WHERE valor > 100;
Tendríamos la siguiente salida:
{"id": 2, "cliente": "Maria", "valor": 150}
{"id": 3, "cliente": "Carlos", "valor": 200}
Si quieres persistir ese resultado en un nuevo tópico filtrado, podrías crear un stream derivado:
CREATE STREAM pedidos_filtrados AS
SELECT * FROM pedidos WHERE valor > 100;
Esto crea un nuevo tópico pedidos_filtrados donde solo entran los eventos que pasan la regla.
KSQL es poderoso para análisis y transformaciones de datos sin necesidad de código Java u otro lenguaje.
Otros ejemplos:
SELECT categoria, COUNT(*) FROM vendas GROUP BY categoria;
SELECT pedidos.id, clientes.nome FROM pedidos JOIN clientes ON pedidos.cliente_id = clientes.id;
Esto hace de KSQL una herramienta poderosa para análisis de datos en tiempo real, enriquecimiento de eventos y creación de pipelines de datos sin necesidad de escribir código complejo.
Si el contenido del mensaje está cifrado, no sería posible utilizar KSQL.
Cruise Control (Balanceo Inteligente de Particiones)
Un cluster típico puede quedar cargado de forma desigual a lo largo del tiempo. Particiones que lidian con grandes cantidades de tráfico de mensajes pueden no estar distribuidas uniformemente entre los brokers disponibles. Para rebalancear el cluster, los administradores deben monitorear la carga en los brokers y reasignar manualmente particiones ocupadas a brokers con capacidad extra.
Cruise Control es una herramienta desarrollada por LinkedIn para gestionar automáticamente la carga y el balanceo de particiones en Apache Kafka. Permite optimizar la distribución de datos entre los brokers, evitando cuellos de botella y garantizando un rendimiento más estable del cluster.
Construye un modelo de carga de trabajo de utilización de recursos para el cluster — basado en la carga de CPU, disco y red — y genera propuestas de optimización (que puedes aprobar o rechazar) para asignaciones de particiones más balanceadas. Un conjunto de metas de optimización configurables es usado para calcular esas propuestas.
Podemos ser bien específicos al generar propuestas de optimización.
- El modo Full rebalancea particiones en todos los brokers.
- Podemos hacer rebalanceo siempre que adicionemos o removamos un broker para acomodar las alteraciones.
Al aprobar una propuesta de optimización, Cruise Control la aplicará en el cluster.
Principales Funcionalidades de Cruise Control:
- Analiza constantemente el consumo de CPU, memoria, disco y red en los brokers.
- Redistribuye particiones entre los brokers para optimizar la carga.
- Permite probar nuevas distribuciones antes de aplicarlas.
- Puedes ejecutar ajustes bajo demanda o dejar que Cruise Control haga eso de forma autónoma.
- Si un broker falla o es removido, Cruise Control redistribuye las particiones sin impacto significativo.
- Interfaz para integración con otros sistemas, permitiendo automatización.
Cruise Control colecta métricas de uso de los brokers y utiliza algoritmos de optimización para tomar decisiones sobre el balanceo de particiones. Trabaja con tres componentes principales:
1️. Monitor de Métricas → Colecta datos de los brokers vía JMX y Kafka Metrics Reporter. 2️. Analizador de Carga → Procesa las métricas colectadas e identifica patrones de uso. 3️. Ejecutor de Acciones → Realoca particiones con base en los análisis para mantener un balanceo eficiente.
La comunicación con Cruise Control es hecha por medio de APIs REST, permitiendo que visualices el estado del cluster y ejecutes rebalanceos bajo demanda.