Backup e Restore
Sabemos que:
- As aplicações devem ser definidas nos seus respectivos arquivos de manifestos que possam ser aplicados gerando somente a diferença.
- Porém, às vezes podemos usar declarações imperativas e não temos uma cópia dos manifestos. Nem todos os membros da equipe costumam seguir o método correto e muitas vezes na hora de apagar algum incêndio recorrem a métodos mais rápidos e desesperados.
- Não conseguimos compartilhar essas diferenças aplicadas via métodos imperativos e sempre precisamos procurar no cluster e conferir.
- Devemos sempre versionar em um repositório git os nossos manifestos para serem mantidos pela equipe
- O kube-apiserver possui todas as declarações de manifestos sejam feitos de forma imperativa ou não.
- O cluster armazena todos os seus dados no ETCD cluster seja ele deployado junto aos nodes master ou de outra maneira.
- Os dados das aplicações são armazenados nos persistent volumes
Kube-ApiServer
Vamos recuperar os manifestos que o kube-apiserver possui.
kubectl get all --all-namespaces -o yaml > all_manifests.yaml
Porém esse comando acima é somente para um pequeno grupo de objetos e existem muitos outros que devem ser considerados. Portanto recuperar os manifestos dessa maneira não é o melhor caminho.
Existem ferramentas com esse propósito como é o caso do Velero, mas não deve ser usado no exame.
ETCD
Ao invés de fazer o backup do kube-apiserver podemos fazer o backup do cluster do ETCD que armazena os dados do kube-apiserver e todos os recursos criados no cluster.
Às vezes em um ambiente gerenciado pela cloud não temos acesso ao etcd então não adiantaria essa solução. Logo fazer o backup usando o kube-apiserver é a melhor maneira.
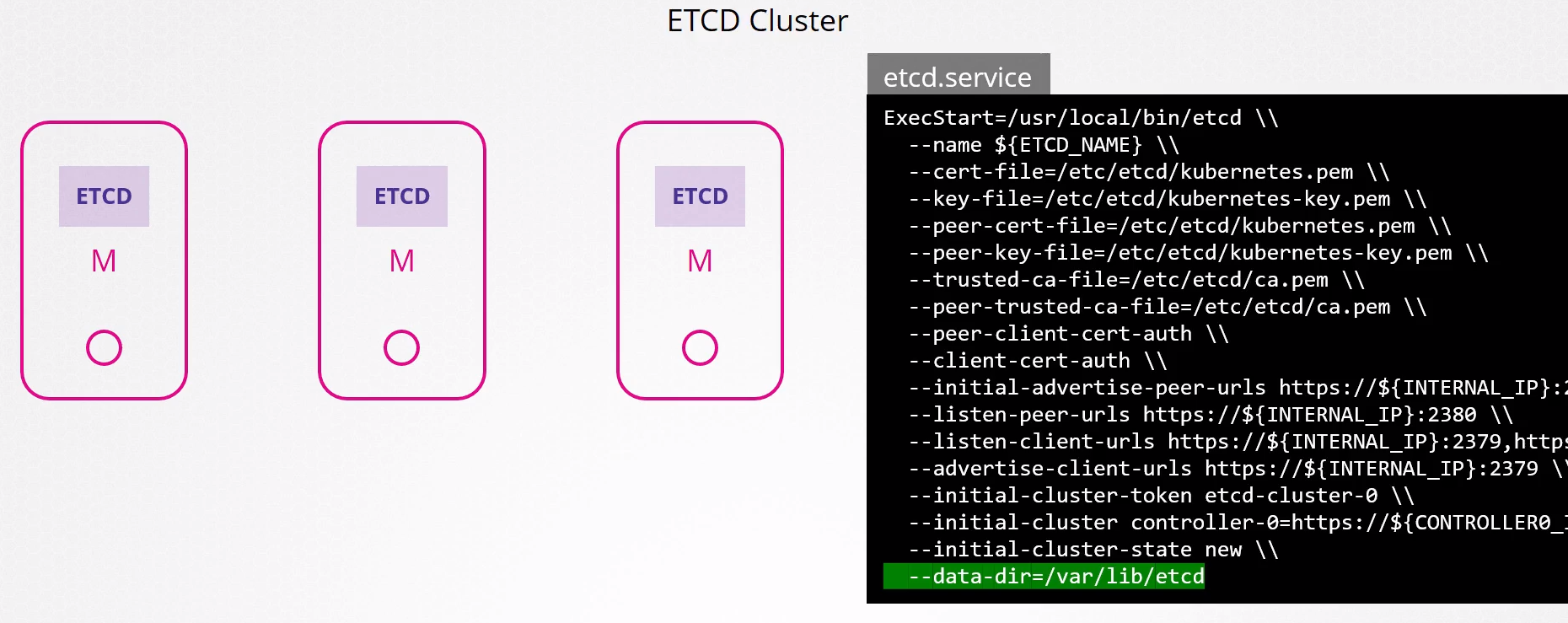
O ETCD tem o seu próprio cluster que pode ser externo ou não, mas geralmente são hospedados dentro dos nós masters.
Na instalação do etcd, temos especificado o local onde são armazenados todos os dados e podemos usar esse diretório para uma ferramenta de backup.
Se o etcd estiver rodando como um pod, geralmente é um pod estático que tem os manifestos no /etc/kubernetes/manifests
Se analisarmos o manifesto desses pods estáticos caso o etcd seja deployado dessa maneira
#cat /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.12.50.3:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.12.50.3:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # certificado usado
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.12.50.3:2380
- --initial-cluster=controlplane=https://192.12.50.3:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.12.50.3:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.12.50.3:2380
- --name=controlplane
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key # cert key usada
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt # CA usado
image: registry.k8s.io/etcd:3.5.7-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health?exclude=NOSPACE&serializable=true
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: etcd
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /health?serializable=false
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts: # Veja os volumes
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priority: 2000001000
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
# Esses volumes do host estão sendo mapeados para dentro do pod nos mesmos paths
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
Observe também que temos também o caminho dos certificados sendo passado usando a referencia do volumes que foi montado.
O comando etcdctl precisa de uma variável para reconhecer que é a api v2 ou v3.
etcdctl --version
etcdctl version: 3.3.13
API version: 2
# esse comando não existe na v2
etcdctl version
No help topic for 'version'
# Essa é a variável que precisa ser definida para saber a versão passando para v3 temos outros comandos e o version funciona aqui assim como o snapshot que não temos na v2
export ETCDCTL_API=3
etcdctl version
etcdctl version: 3.3.13
API version: 3.3
O ETCD também vem com uma solução builtin que pode tirar um snapshot instantâneo do database na v3.
Se o etcd estiver sob tls precisamos passar o comando abaixo com os certificados apontados.
etcdctl snapshot save --endpoints=127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key /opt/snapshot-pre-boot.db
# Nesse caso instalei o etcd na minha própria máquina então não precisei passar os certificados
etcdctl snapshot save snapshot.db # passe o caminho completo do arquivo se quiser.
{"level":"info","ts":1704447228.7458081,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"snapshot.db.part"}
{"level":"info","ts":"2024-01-05T06:33:48.747-0300","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1704447228.747063,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2024-01-05T06:33:48.748-0300","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1704447228.7492132,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"20 kB","took":0.003339672}
{"level":"info","ts":1704447228.7493641,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"snapshot.db"}
Snapshot saved at snapshot.db
# Para ver o status do backup
etcdctl snapshot status snapshot.db
bfa20374, 0, 3, 20 kB
Para recuperar os dados usando esse snapshot.
sudo systemctl stop etcd.service
sudo systemctl status etcd.service
○ etcd.service - etcd - highly-available key value store
Loaded: loaded (/lib/systemd/system/etcd.service; enabled; preset: enabled)
Active: inactive (dead) since Fri 2024-01-05 06:38:00 -03; 31s ago
Duration: 4min 30.235s
Docs: https://etcd.io/docs
man:etcd
Process: 50148 ExecStart=/usr/bin/etcd $DAEMON_ARGS (code=killed, signal=TERM)
Main PID: 50148 (code=killed, signal=TERM)
CPU: 2.152s
Jan 05 06:33:30 david-laptop etcd[50148]: enabled capabilities for version 3.4
Jan 05 06:33:48 david-laptop etcd[50148]: sending database snapshot to client 20 kB [20480 bytes]
Jan 05 06:33:48 david-laptop etcd[50148]: sending database sha256 checksum to client [32 bytes]
Jan 05 06:33:48 david-laptop etcd[50148]: successfully sent database snapshot to client 20 kB [20480 bytes]
Jan 05 06:38:00 david-laptop systemd[1]: Stopping etcd.service - etcd - highly-available key value store...
Jan 05 06:38:00 david-laptop etcd[50148]: received terminated signal, shutting down...
Jan 05 06:38:00 david-laptop etcd[50148]: skipped leadership transfer for single voting member cluster
Jan 05 06:38:00 david-laptop systemd[1]: etcd.service: Deactivated successfully. #<<<
# O comando restore pegará o snapshot e colocará em um diretório específico que precisará depois ser usado
sudo etcdctl snapshot restore snapshot.db --data-dir /var/lib/etcd-from-backup
{"level":"info","ts":1704447747.1907465,"caller":"snapshot/v3_snapshot.go:296","msg":"restoring snapshot","path":"snapshot.db","wal-dir":"/var/lib/etcd-from-backup/member/wal","data-dir":"/var/lib/etcd-from-backup","snap-dir":"/var/lib/etcd-from-backup/member/snap"}
{"level":"info","ts":1704447747.195053,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"cdf818194e3a8c32","local-member-id":"0","added-peer-id":"8e9e05c52164694d","added-peer-peer-urls":["http://localhost:2380"]}
{"level":"info","ts":1704447747.1978393,"caller":"snapshot/v3_snapshot.go:309","msg":"restored snapshot","path":"snapshot.db","wal-dir":"/var/lib/etcd-from-backup/member/wal","data-dir":"/var/lib/etcd-from-backup","snap-dir":"/var/lib/etcd-from-backup/member/snap"}
Agora precisamos configurar o serviço do etcd novamente para usar esse diretório.
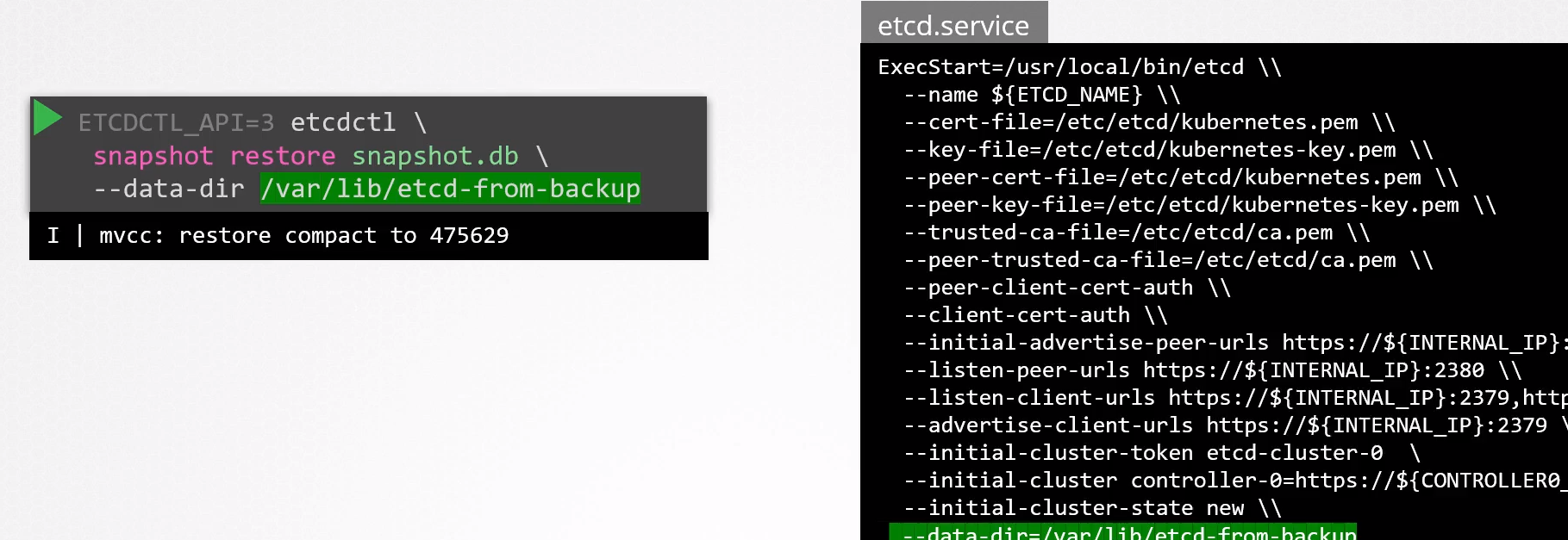
E depois podemos recarregar o serviço e iniciar novamente.
systemctl daemon-reload
systemctl restart etcd-service
Em um cluster etcd externo é necessário que o diretório dos dados do etcd pertença ao usuário etcd
# para definir a permissão quando necessário
chown etcd:etcd -R /var/lib/etcd