Backup y Restauración
Sabemos que:
- Las aplicaciones deben ser definidas en sus respectivos archivos de manifiestos que puedan ser aplicados generando solamente la diferencia.
- Sin embargo, a veces podemos usar declaraciones imperativas y no tenemos una copia de los manifiestos. No todos los miembros del equipo suelen seguir el método correcto y muchas veces a la hora de apagar algún incendio recurren a métodos más rápidos y desesperados.
- No podemos compartir esas diferencias aplicadas vía métodos imperativos y siempre necesitamos buscar en el cluster y verificar.
- Debemos siempre versionar en un repositorio git nuestros manifiestos para ser mantenidos por el equipo
- El kube-apiserver posee todas las declaraciones de manifiestos sean hechas de forma imperativa o no.
- El cluster almacena todos sus datos en el cluster ETCD sea este deployado junto a los nodos master o de otra manera.
- Los datos de las aplicaciones son almacenados en los persistent volumes
Kube-ApiServer
Vamos a recuperar los manifiestos que el kube-apiserver posee.
kubectl get all --all-namespaces -o yaml > all_manifests.yaml
Sin embargo, este comando arriba es solamente para un pequeño grupo de objetos y existen muchos otros que deben ser considerados. Por lo tanto, recuperar los manifiestos de esta manera no es el mejor camino.
Existen herramientas con este propósito como es el caso del Velero, pero no debe ser usado en el examen.
ETCD
En lugar de hacer el backup del kube-apiserver podemos hacer el backup del cluster de ETCD que almacena los datos del kube-apiserver y todos los recursos creados en el cluster.
A veces en un ambiente administrado por la nube no tenemos acceso al etcd entonces no serviría esta solución. Por lo tanto, hacer el backup usando el kube-apiserver es la mejor manera.
El ETCD tiene su propio cluster que puede ser externo o no, pero generalmente son hospedados dentro de los nodos masters.
En la instalación del etcd, tenemos especificado el local donde son almacenados todos los datos y podemos usar ese directorio para una herramienta de backup.
Si el etcd estuviera corriendo como un pod, generalmente es un pod estático que tiene los manifiestos en /etc/kubernetes/manifests
Si analizamos el manifiesto de esos pods estáticos en caso de que el etcd sea deployado de esta manera
#cat /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.12.50.3:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.12.50.3:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # certificado usado
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://192.12.50.3:2380
- --initial-cluster=controlplane=https://192.12.50.3:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.12.50.3:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.12.50.3:2380
- --name=controlplane
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key # cert key usada
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt # CA usado
image: registry.k8s.io/etcd:3.5.7-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health?exclude=NOSPACE&serializable=true
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: etcd
resources:
requests:
cpu: 100m
memory: 100Mi
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /health?serializable=false
port: 2381
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts: # Vea los volúmenes
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priority: 2000001000
priorityClassName: system-node-critical
securityContext:
seccompProfile:
type: RuntimeDefault
# Esos volúmenes del host están siendo mapeados para dentro del pod en los mismos paths
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
Observe también que tenemos también el camino de los certificados siendo pasado usando la referencia de los volúmenes que fueron montados.
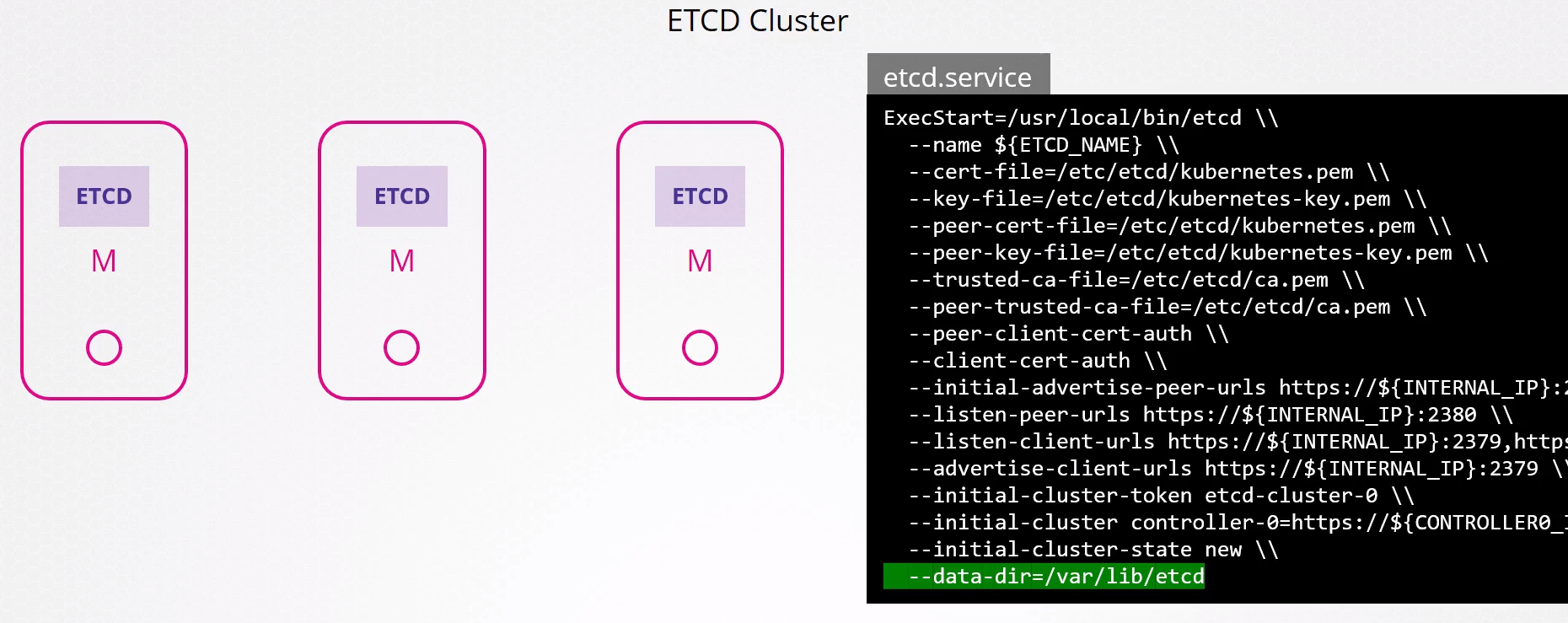
El comando etcdctl necesita de una variable para reconocer que es la api v2 o v3.
etcdctl --version
etcdctl version: 3.3.13
API version: 2
# este comando no existe en la v2
etcdctl version
No help topic for 'version'
# Esta es la variable que necesita ser definida para saber la versión pasando para v3 tenemos otros comandos y el version funciona aquí así como el snapshot que no tenemos en la v2
export ETCDCTL_API=3
etcdctl version
etcdctl version: 3.3.13
API version: 3.3
El ETCD también viene con una solución builtin que puede tomar un snapshot instantáneo de la database en la v3.
Si el etcd estuviera bajo tls necesitamos pasar el comando abajo con los certificados apuntados.
etcdctl snapshot save --endpoints=127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key /opt/snapshot-pre-boot.db
# En este caso instalé el etcd en mi propia máquina entonces no necesité pasar los certificados
etcdctl snapshot save snapshot.db # pase el camino completo del archivo si quiere.
{"level":"info","ts":1704447228.7458081,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"snapshot.db.part"}
{"level":"info","ts":"2024-01-05T06:33:48.747-0300","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1704447228.747063,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2024-01-05T06:33:48.748-0300","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1704447228.7492132,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"20 kB","took":0.003339672}
{"level":"info","ts":1704447228.7493641,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"snapshot.db"}
Snapshot saved at snapshot.db
# Para ver el status del backup
etcdctl snapshot status snapshot.db
bfa20374, 0, 3, 20 kB
Para recuperar los datos usando ese snapshot.
sudo systemctl stop etcd.service
sudo systemctl status etcd.service
○ etcd.service - etcd - highly-available key value store
Loaded: loaded (/lib/systemd/system/etcd.service; enabled; preset: enabled)
Active: inactive (dead) since Fri 2024-01-05 06:38:00 -03; 31s ago
Duration: 4min 30.235s
Docs: https://etcd.io/docs
man:etcd
Process: 50148 ExecStart=/usr/bin/etcd $DAEMON_ARGS (code=killed, signal=TERM)
Main PID: 50148 (code=killed, signal=TERM)
CPU: 2.152s
Jan 05 06:33:30 david-laptop etcd[50148]: enabled capabilities for version 3.4
Jan 05 06:33:48 david-laptop etcd[50148]: sending database snapshot to client 20 kB [20480 bytes]
Jan 05 06:33:48 david-laptop etcd[50148]: sending database sha256 checksum to client [32 bytes]
Jan 05 06:33:48 david-laptop etcd[50148]: successfully sent database snapshot to client 20 kB [20480 bytes]
Jan 05 06:38:00 david-laptop systemd[1]: Stopping etcd.service - etcd - highly-available key value store...
Jan 05 06:38:00 david-laptop etcd[50148]: received terminated signal, shutting down...
Jan 05 06:38:00 david-laptop etcd[50148]: skipped leadership transfer for single voting member cluster
Jan 05 06:38:00 david-laptop systemd[1]: etcd.service: Deactivated successfully. #<<<
# El comando restore tomará el snapshot y lo colocará en un directorio específico que necesitará después ser usado
sudo etcdctl snapshot restore snapshot.db --data-dir /var/lib/etcd-from-backup
{"level":"info","ts":1704447747.1907465,"caller":"snapshot/v3_snapshot.go:296","msg":"restoring snapshot","path":"snapshot.db","wal-dir":"/var/lib/etcd-from-backup/member/wal","data-dir":"/var/lib/etcd-from-backup","snap-dir":"/var/lib/etcd-from-backup/member/snap"}
{"level":"info","ts":1704447747.195053,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"cdf818194e3a8c32","local-member-id":"0","added-peer-id":"8e9e05c52164694d","added-peer-peer-urls":["http://localhost:2380"]}
{"level":"info","ts":1704447747.1978393,"caller":"snapshot/v3_snapshot.go:309","msg":"restored snapshot","path":"snapshot.db","wal-dir":"/var/lib/etcd-from-backup/member/wal","data-dir":"/var/lib/etcd-from-backup","snap-dir":"/var/lib/etcd-from-backup/member/snap"}
Ahora necesitamos configurar el servicio del etcd nuevamente para usar ese directorio.
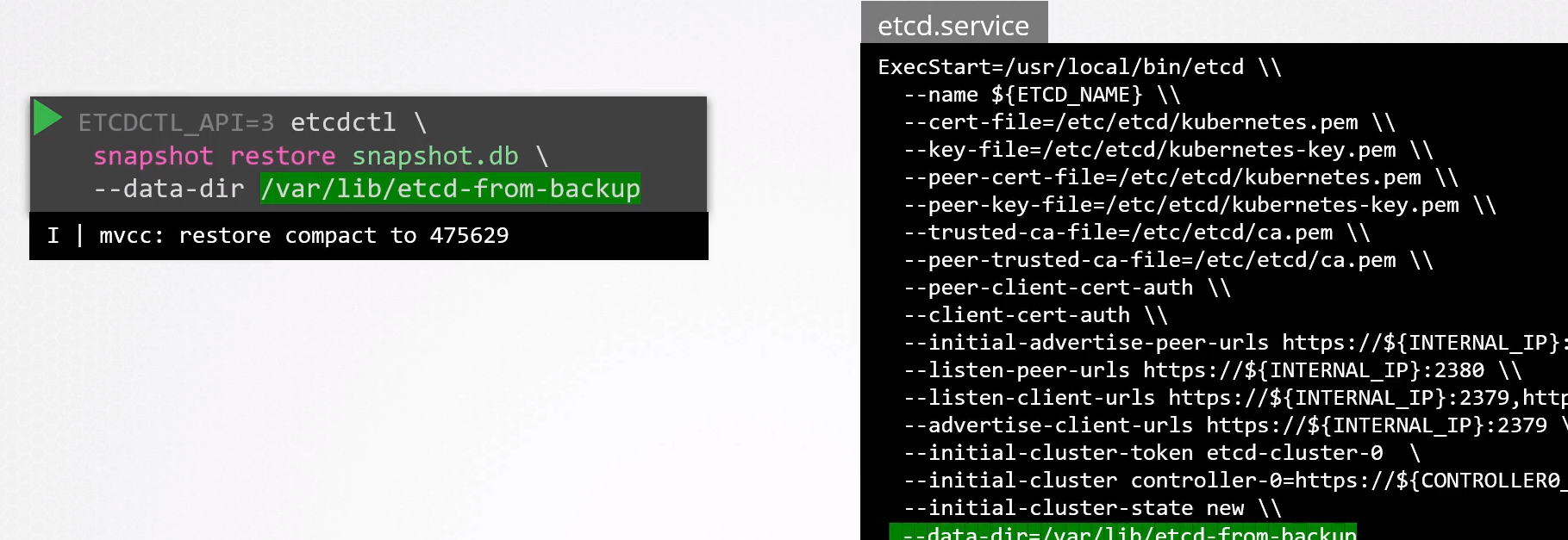
Y después podemos recargar el servicio e iniciar nuevamente.
systemctl daemon-reload
systemctl restart etcd-service
En un cluster etcd externo es necesario que el directorio de los datos del etcd pertenezca al usuario etcd
# para definir el permiso cuando sea necesario
chown etcd:etcd -R /var/lib/etcd