Actualización del Sistema Operativo
Imaginemos el siguiente escenario.
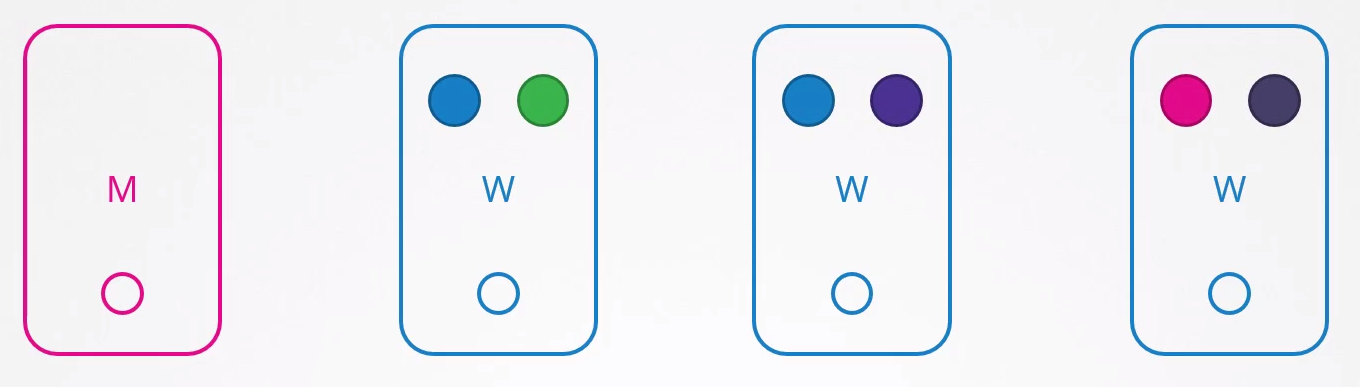
Los pods azules están definidos por un ReplicaSet y los demás son simplemente pods sin ReplicaSets.
¿Qué sucede si el nodo 1 se detiene?
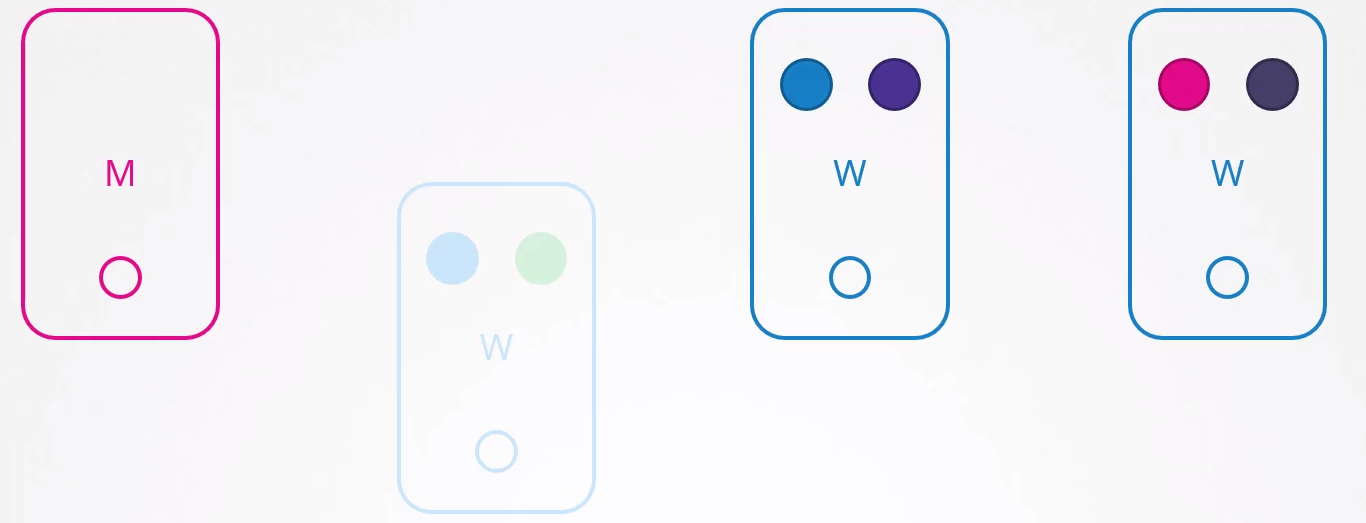
Los usuarios que necesitan acceso a la aplicación verde habrán sido impactados, pero los que acceden a la azul no. Si los dos azules estuvieran en el mismo nodo, sí lo habrían sido.
¿Cómo se comporta Kubernetes por defecto si un nodo deja de responder?
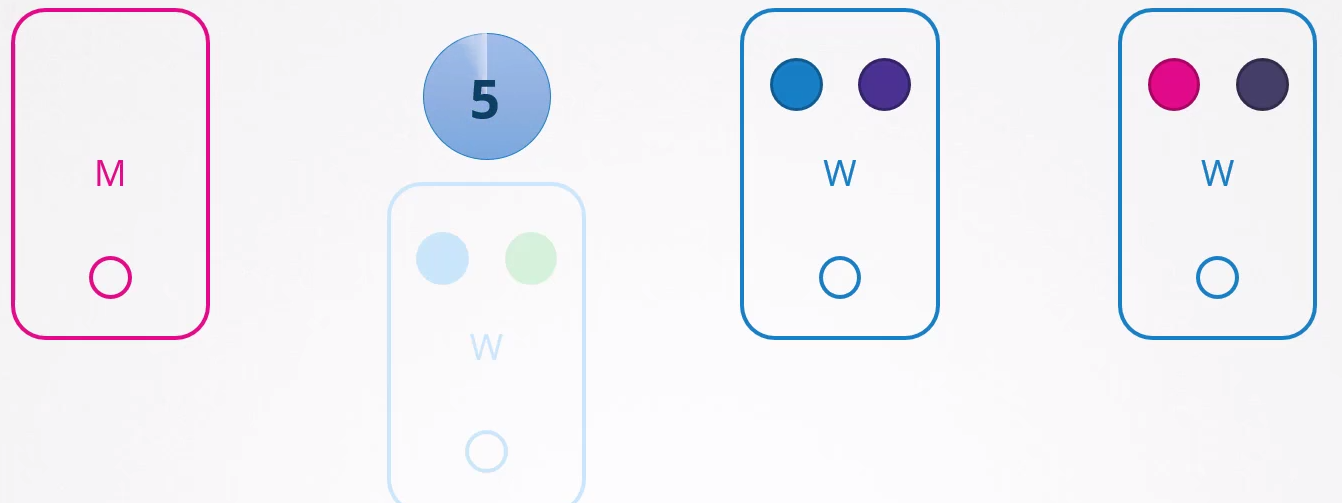
Si deja de responder y vuelve inmediatamente, el Kubelet inicia con los pods en línea. Sin embargo, si el nodo permanece inaccesible por más de 5 minutos, entonces los pods son terminados de este nodo e intentan ser programados en otros nodos posibles. Kubernetes considera los pods que estaban en el nodo que dejó de responder como terminados.
Los ReplicaSets y DaemonSets garantizan que los pods que gestionan estén siempre activos, distribuyéndolos a otros nodos cuando sea necesario. Sin embargo, si un pod no está asociado a un controlador, como un ReplicaSet, después de cinco minutos no será reubicado en otros nodos. Esto evidencia la falta de practicidad de tener pods sueltos, sin vínculo con un ReplicaSet. Por esta razón, es común crear Deployments, DaemonSets, entre otros controladores, para gestionar los pods de manera eficiente.
Para configurar el tiempo de evacuación de pods a 5 minutos en el kube-controller después de la creación del cluster, puedes utilizar la opción --pod-eviction-timeout seguida del valor deseado en segundos. Por ejemplo:
kube-controller-manager --pod-eviction-timeout=5m0s
Cuando un nodo vuelve en línea después de los 5 minutos, aparece vacío sin ningún pod dentro.
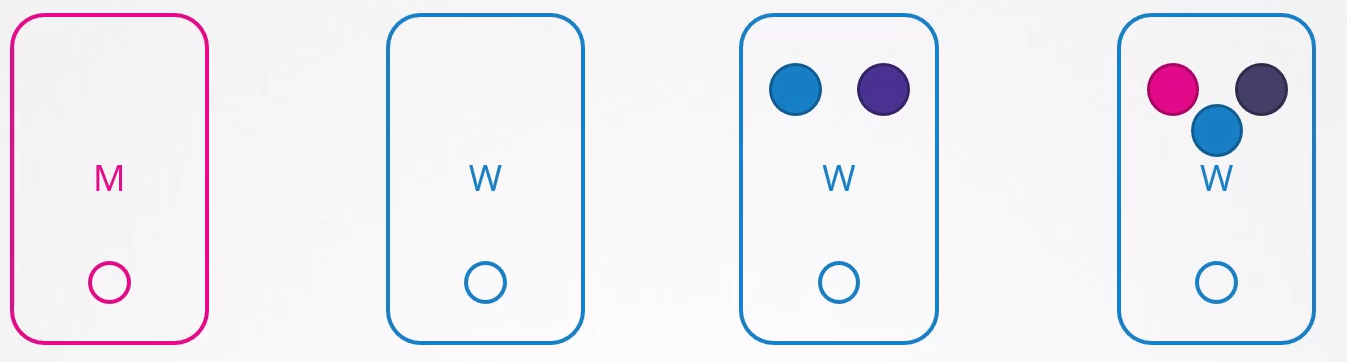
En el caso de la aplicación verde, no volvería, ya que no tiene un controlador.
Un escenario propuesto sería:
- Todos los pods deberían tener al menos 2 réplicas, en nodos diferentes.
- La actualización durará menos de 5 minutos para reiniciar.
Este sería el escenario donde existe certeza, pero esa certeza siempre es incierta :D. No se sabe cuánto tiempo podría llevar la actualización de un sistema operativo o aplicar un parche en el nodo.
Un enfoque eficaz es eliminar intencionalmente los pods de esos nodos y reubicarlos en otros nodos disponibles. Esto se puede hacer utilizando una técnica conocida como "drenaje" (drain) de los pods de un nodo específico.
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k3d-k3s-default-agent-1 Ready <none> 2d7h v1.27.4+k3s1
k3d-k3s-default-agent-0 Ready <none> 2d7h v1.27.4+k3s1
k3d-k3s-default-server-0 Ready control-plane,master 2d7h v1.27.4+k3s1
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d6h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-95qhp 1/1 Running 1 (2d5h ago) 2d6h 10.42.0.8 k3d-k3s-default-agent-0 <none> <none>
# Podemos observar en este escenario que tenemos pods ejecutándose en el nodo agent-0 y agent-1
# Este comando drenaría el nodo de las cargas de trabajo presentes en él, pero como estoy ejecutando esto en un kubernetes local, necesito hacer algunos ignores
kubectl drain k3d-k3s-default-agent-0 # <<<
node/k3d-k3s-default-agent-0 already cordoned
error: unable to drain node "k3d-k3s-default-agent-0" due to error:[cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/svclb-traefik-15becd31-mrzbx, cannot delete Pods with local storage (use --delete-emptydir-data to override): kube-system/metrics-server-648b5df564-lbdhk], continuing command...
There are pending nodes to be drained:
k3d-k3s-default-agent-0
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/svclb-traefik-15becd31-mrzbx
cannot delete Pods with local storage (use --delete-emptydir-data to override): kube-system/metrics-server-648b5df564-lbdhk
# Observa que este nodo fue drenado y no existen pods ejecutándose en él, además fue marcado con un taint NoSchedule para evitar que nuevos pods sean programados en él
kubectl drain k3d-k3s-default-agent-0 --ignore-daemonsets --delete-emptydir-data # <<<
node/k3d-k3s-default-agent-0 already cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/svclb-traefik-15becd31-mrzbx
evicting pod kube-system/metrics-server-648b5df564-lbdhk
evicting pod default/nginx-7b8df77865-95qhp
evicting pod kube-system/local-path-provisioner-957fdf8bc-ksx6w
pod/nginx-7b8df77865-95qhp evicted
pod/metrics-server-648b5df564-lbdhk evicted
pod/local-path-provisioner-957fdf8bc-ksx6w evicted
node/k3d-k3s-default-agent-0 drained
kubectl describe nodes k3d-k3s-default-agent-0
Name: k3d-k3s-default-agent-0
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k3d-k3s-default-agent-0
kubernetes.io/os=linux
node.kubernetes.io/instance-type=k3s
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"f6:bd:b2:c3:69:1d"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.18.0.3
k3s.io/hostname: k3d-k3s-default-agent-0
k3s.io/internal-ip: 172.18.0.3
k3s.io/node-args: ["agent"]
k3s.io/node-config-hash: GNY45P4EZT4AMDLCADCGJR3BA5KIFTXTP7YACNXMTZAVYI2VMO7A====
k3s.io/node-env:
{"K3S_KUBECONFIG_OUTPUT":"/output/kubeconfig.yaml","K3S_TOKEN":"********","K3S_URL":"https://k3d-k3s-default-server-0:6443"}
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 30 Dec 2023 10:59:09 -0300
Taints: node.kubernetes.io/unschedulable:NoSchedule # <<<<<
Unschedulable: true #<<<<
Lease:
HolderIdentity: k3d-k3s-default-agent-0
AcquireTime: <unset>
RenewTime: Mon, 01 Jan 2024 18:37:28 -0300
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.18.0.3
Hostname: k3d-k3s-default-agent-0
Capacity:
cpu: 24
ephemeral-storage: 1055762868Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
Allocatable:
cpu: 24
ephemeral-storage: 1027046117185
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
System Info:
Machine ID:
System UUID:
Boot ID: 8e6ef727-43a3-47b4-b08f-6f51e384394c
Kernel Version: 5.15.133.1-microsoft-standard-WSL2
OS Image: K3s dev
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.7.1-k3s1
Kubelet Version: v1.27.4+k3s1
Kube-Proxy Version: v1.27.4+k3s1
PodCIDR: 10.42.0.0/24
PodCIDRs: 10.42.0.0/24
ProviderID: k3s://k3d-k3s-default-agent-0
Non-terminated Pods: (1 in total) ## <<< TODAVÍA TENEMOS ESTE POD DENTRO
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system svclb-traefik-15becd31-mrzbx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotSchedulable 4m10s kubelet Node k3d-k3s-default-agent-0 status is now: NodeNotSchedulable #<<<<
## Vamos a comparar con otro nodo que tiene pods
kubectl describe nodes k3d-k3s-default-agent-1
Name: k3d-k3s-default-agent-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k3d-k3s-default-agent-1
kubernetes.io/os=linux
node.kubernetes.io/instance-type=k3s
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"36:e0:49:2e:af:f7"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.18.0.2
k3s.io/hostname: k3d-k3s-default-agent-1
k3s.io/internal-ip: 172.18.0.2
k3s.io/node-args: ["agent"]
k3s.io/node-config-hash: GNY45P4EZT4AMDLCADCGJR3BA5KIFTXTP7YACNXMTZAVYI2VMO7A====
k3s.io/node-env:
{"K3S_KUBECONFIG_OUTPUT":"/output/kubeconfig.yaml","K3S_TOKEN":"********","K3S_URL":"https://k3d-k3s-default-server-0:6443"}
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 30 Dec 2023 10:59:08 -0300
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: k3d-k3s-default-agent-1
AcquireTime: <unset>
RenewTime: Mon, 01 Jan 2024 18:42:16 -0300
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.18.0.2
Hostname: k3d-k3s-default-agent-1
Capacity:
cpu: 24
ephemeral-storage: 1055762868Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
Allocatable:
cpu: 24
ephemeral-storage: 1027046117185
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
System Info:
Machine ID:
System UUID:
Boot ID: 8e6ef727-43a3-47b4-b08f-6f51e384394c
Kernel Version: 5.15.133.1-microsoft-standard-WSL2
OS Image: K3s dev
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.7.1-k3s1
Kubelet Version: v1.27.4+k3s1
Kube-Proxy Version: v1.27.4+k3s1
PodCIDR: 10.42.1.0/24
PodCIDRs: 10.42.1.0/24
ProviderID: k3s://k3d-k3s-default-agent-1
#################################################################################################################
# Verás que tenemos nginx aquí
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h #<<<
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 6m46s
#################################################################################################################
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
## ¿Dónde fue el otro pod?
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-rkvvp 1/1 Running 0 8m17s 10.42.2.13 k3d-k3s-default-server-0 <none> <none>
# El desgraciado fue al servidor, lo cual no es buena idea, pero fue, porque en este cluster local, los masters no tienen taints.
kubectl taint node k3d-k3s-default-server-0 nodeType=master:NoExecute
node/k3d-k3s-default-server-0 tainted
# Ahora tenemos todo en el agent-1 que sería el único posible de recibir.
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-g5z2d 1/1 Running 0 6s 10.42.1.31 k3d-k3s-default-agent-1 <none> <none>
kubectl describe nodes k3d-k3s-default-agent-1
...
ProviderID: k3s://k3d-k3s-default-agent-1
Non-terminated Pods: (7 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h #<<<<
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 14m
default nginx-7b8df77865-g5z2d 0 (0%) 0 (0%) 0 (0%) 0 (0%) 83s #<<<<
kube-system coredns-77ccd57875-mmlgl 100m (0%) 0 (0%) 70Mi (0%) 170Mi (2%) 83s
kube-system metrics-server-648b5df564-tb7ks 100m (0%) 0 (0%) 70Mi (0%) 0 (0%) 83s
Allocated resources:
# Y tenemos ambos ejecutándose en el mismo nodo
Cuando drenamos un nodo, se marca con un taint y los pods son eliminados. Algunos pods no se eliminan, ya que son daemonset como se vio arriba y ejecutan obligatoriamente 1 por nodo. Probablemente en el caso de ese traefik, debe tener una toleration para NoSchedule por eso todavía está presente.
Ningún pod puede ser programado en ese nodo a menos que elimines el taint con la restricción.
El comando drain no necesariamente mueve los pods, sino que mata el pod y este vuelve a la cola para ser programado. Cuando vuelva a la etapa de filtrado, el nodo en el que estaba no será elegido.
A partir de ahora podríamos trabajar en ese nodo y hacer las actualizaciones necesarias con seguridad.
Para eliminar el taint específico creado por drain usamos el comando uncordon.
kubectl uncordon k3d-k3s-default-agent-0
node/k3d-k3s-default-agent-0 uncordoned
kubectl describe nodes k3d-k3s-default-agent-0
Name: k3d-k3s-default-agent-0
...
CreationTimestamp: Sat, 30 Dec 2023 10:59:09 -0300
Taints: <none> #<<<<
Unschedulable: false
...
Non-terminated Pods: (1 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system svclb-traefik-15becd31-mrzbx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotSchedulable 23m kubelet Node k3d-k3s-default-agent-0 status is now: NodeNotSchedulable
Normal NodeSchedulable 19s kubelet Node k3d-k3s-default-agent-0 status is now: NodeSchedulable #<<<<
Cuando un nodo vuelve, Kubernetes no intenta redistribuir la carga, simplemente queda disponible para nuevos pods. Esto solo ocurriría si el pod terminara y un controlador intentara encontrar un nuevo nodo para él.
El comando cordon marca un nodo como no programable, pero no mata los pods. El drain hace ambas cosas.
kubectl cordon k3d-k3s-default-agent-1
node/k3d-k3s-default-agent-1 cordoned
kubectl describe nodes k3d-k3s-default-agent-1 | grep Unschedulable
Unschedulable: true
kubectl describe nodes k3d-k3s-default-agent-1
Name: k3d-k3s-default-agent-1
...
CreationTimestamp: Sat, 30 Dec 2023 10:59:08 -0300
Taints: node.kubernetes.io/unschedulable:NoSchedule
Unschedulable: true
Non-terminated Pods: (7 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d8h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d8h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
default nginx-7b8df77865-g5z2d 0 (0%) 0 (0%) 0 (0%) 0 (0%) 15m
kube-system coredns-77ccd57875-mmlgl 100m (0%) 0 (0%) 70Mi (0%) 170Mi (2%) 15m
kube-system metrics-server-648b5df564-tb7ks 100m (0%) 0 (0%) 70Mi (0%) 0 (0%) 15m
...
Normal NodeNotSchedulable 16s kubelet Node k3d-k3s-default-agent-1 status is now: NodeNotSchedulable
# Ahora vamos a escalar este nginx a 10 y veremos a dónde va
kubectl scale deployment nginx --replicas 10
deployment.apps/nginx scaled
# Fue todo al nodo agent-0
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-g5z2d 1/1 Running 0 17m 10.42.1.31 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-j4tn4 1/1 Running 0 7s 10.42.0.15 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-tnnkc 1/1 Running 0 7s 10.42.0.12 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-hlq69 1/1 Running 0 7s 10.42.0.14 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-5h7bx 1/1 Running 0 7s 10.42.0.11 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-w6wxz 1/1 Running 0 7s 10.42.0.13 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-5vjv4 1/1 Running 0 7s 10.42.0.16 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-hvwpn 1/1 Running 0 7s 10.42.0.17 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-vgrrz 1/1 Running 0 7s 10.42.0.18 k3d-k3s-default-agent-0 <none> <none>