Upgrade do Sistema Operacional
Vamos imaginar o seguinte cenário.
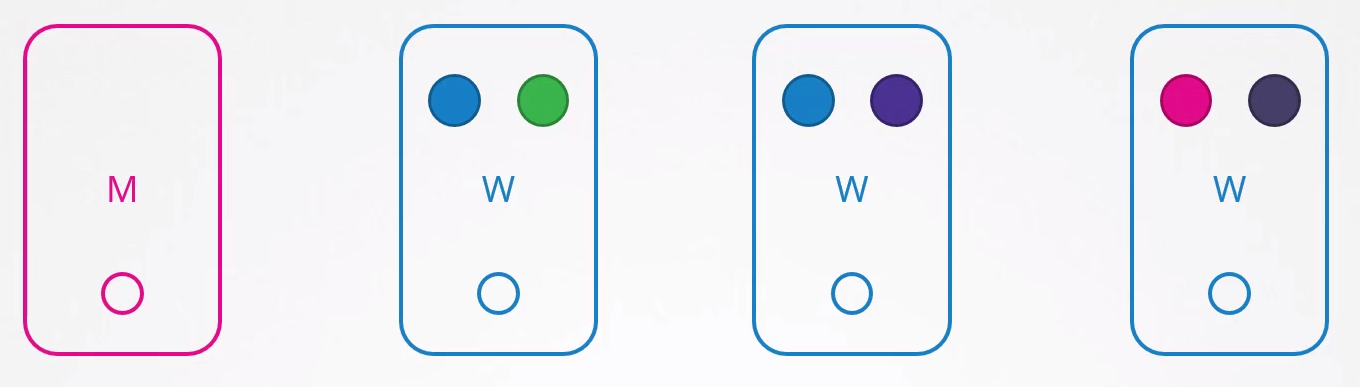
Pods azuis são definidos por um ReplicaSet e os demais são simplesmente pods sem ReplicaSets.
Se o node 1 parar o que acontece?
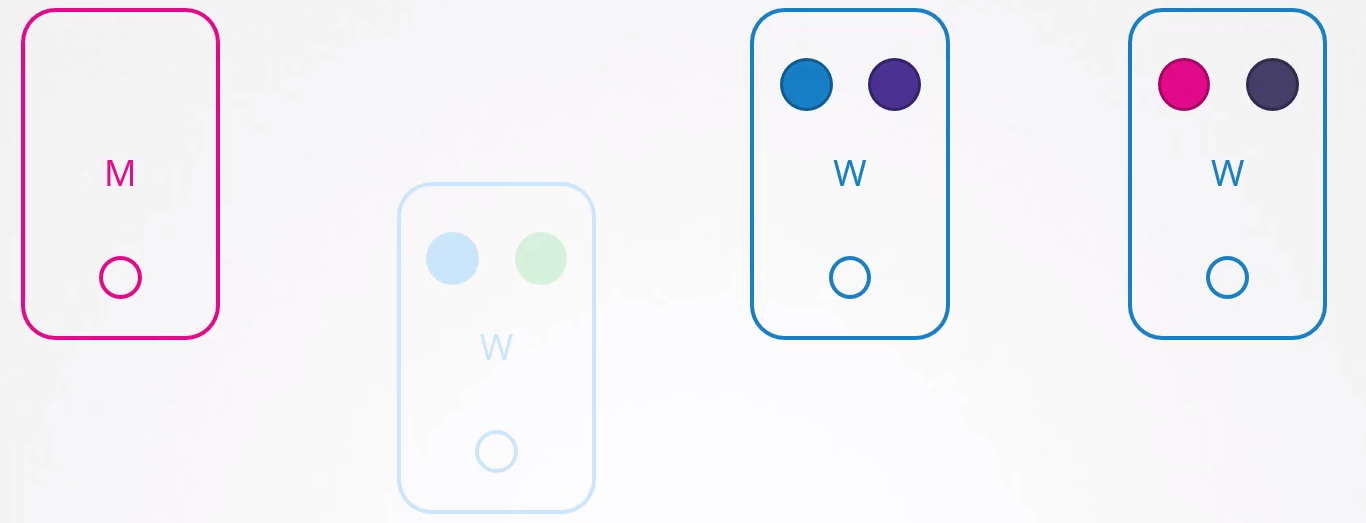
Os usuários que precisam de acesso ao app verde terão sido impactados, mas os que acessam o azul não. Se os dois azuis estivessem no mesmo node, teriam.
Como o Kubernetes se comporta por default caso um node pare de responder?
Se parar de responder e voltar imediatamente o Kubelet inicia com os pods online. Porém, se o node ficar inacessível por mais de 5 minutos então os pods são terminados a partir deste node e tentam ser agendados para outros possíveis nodes. O Kubernetes considera os pods que estavam no node que parou de responder como terminado.
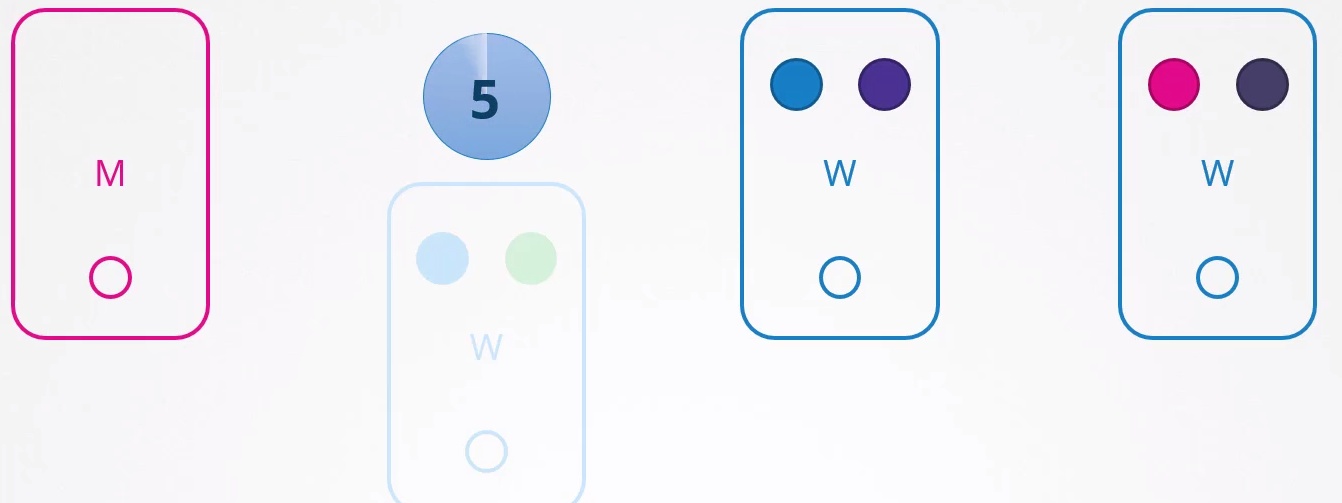
Replicaset e DaemonSet garantem que os pods que gerenciam estejam sempre ativos, distribuindo-os para outros nós quando necessário. No entanto, se um pod não estiver associado a um controlador, como um Replicaset, após cinco minutos ele não será realocado para outros nós. Isso evidencia a falta de praticidade em ter pods soltos, sem vínculo com um Replicaset. Por essa razão, é comum criar Deployments, DaemonSets, entre outros controladores, para gerenciar os pods de maneira eficiente.
Para configurar o tempo de evacuação de pods para 5 minutos no kube-controller após a criação do cluster, você pode utilizar a opção --pod-eviction-timeout seguida pelo valor desejado em segundos. Por exemplo:
kube-controller-manager --pod-eviction-timeout=5m0s
Quando um nó volta online após os 5 minutos, ele aparece em branco sem nenhum pod dentro.
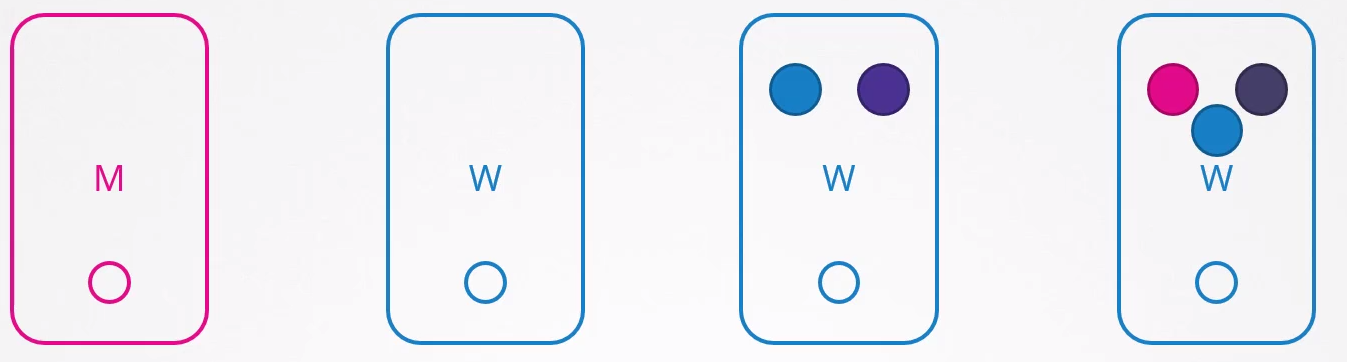
No caso da aplicação verde, ela não voltaria, pois não tem um controller.
Um cenário proposto seria:
- Todos os pods deveriam ter pelo menos 2 replicas, em nodes diferentes.
- O upgrade durará menos de 5 minutos para reiniciar.
Este seria o cenário onde a certeza existe, mas essa certeza é sempre incerta :D. Não se sabe quanto tempo poderia levar o upgrade de um sistema operacional ou aplicar um patch no node.
Uma abordagem eficaz é remover intencionalmente os pods desses nós e relocá-los para outros nós disponíveis. Isso pode ser feito utilizando uma técnica conhecida como "drenagem" dos pods de um node específico.
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k3d-k3s-default-agent-1 Ready <none> 2d7h v1.27.4+k3s1
k3d-k3s-default-agent-0 Ready <none> 2d7h v1.27.4+k3s1
k3d-k3s-default-server-0 Ready control-plane,master 2d7h v1.27.4+k3s1
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d6h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-95qhp 1/1 Running 1 (2d5h ago) 2d6h 10.42.0.8 k3d-k3s-default-agent-0 <none> <none>
# Podemos observar neste cenário que temos pods rodando no node agent-0 e agent-1
# Este comando iria drenar o node dos workloads presentes neles, mas como estou executando isso em um kubernetes local, preciso fazer algumas ignores
kubectl drain k3d-k3s-default-agent-0 # <<<
node/k3d-k3s-default-agent-0 already cordoned
error: unable to drain node "k3d-k3s-default-agent-0" due to error:[cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/svclb-traefik-15becd31-mrzbx, cannot delete Pods with local storage (use --delete-emptydir-data to override): kube-system/metrics-server-648b5df564-lbdhk], continuing command...
There are pending nodes to be drained:
k3d-k3s-default-agent-0
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/svclb-traefik-15becd31-mrzbx
cannot delete Pods with local storage (use --delete-emptydir-data to override): kube-system/metrics-server-648b5df564-lbdhk
# Observe que este node foi drenado e não existem pods rodando nele, além disso ele foi marcado com uma taint NoSchedule para evitar que novos pods sejam agendados para ele
kubectl drain k3d-k3s-default-agent-0 --ignore-daemonsets --delete-emptydir-data # <<<
node/k3d-k3s-default-agent-0 already cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/svclb-traefik-15becd31-mrzbx
evicting pod kube-system/metrics-server-648b5df564-lbdhk
evicting pod default/nginx-7b8df77865-95qhp
evicting pod kube-system/local-path-provisioner-957fdf8bc-ksx6w
pod/nginx-7b8df77865-95qhp evicted
pod/metrics-server-648b5df564-lbdhk evicted
pod/local-path-provisioner-957fdf8bc-ksx6w evicted
node/k3d-k3s-default-agent-0 drained
kubectl describe nodes k3d-k3s-default-agent-0
Name: k3d-k3s-default-agent-0
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k3d-k3s-default-agent-0
kubernetes.io/os=linux
node.kubernetes.io/instance-type=k3s
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"f6:bd:b2:c3:69:1d"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.18.0.3
k3s.io/hostname: k3d-k3s-default-agent-0
k3s.io/internal-ip: 172.18.0.3
k3s.io/node-args: ["agent"]
k3s.io/node-config-hash: GNY45P4EZT4AMDLCADCGJR3BA5KIFTXTP7YACNXMTZAVYI2VMO7A====
k3s.io/node-env:
{"K3S_KUBECONFIG_OUTPUT":"/output/kubeconfig.yaml","K3S_TOKEN":"********","K3S_URL":"https://k3d-k3s-default-server-0:6443"}
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 30 Dec 2023 10:59:09 -0300
Taints: node.kubernetes.io/unschedulable:NoSchedule # <<<<<
Unschedulable: true #<<<<
Lease:
HolderIdentity: k3d-k3s-default-agent-0
AcquireTime: <unset>
RenewTime: Mon, 01 Jan 2024 18:37:28 -0300
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Mon, 01 Jan 2024 18:34:32 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.18.0.3
Hostname: k3d-k3s-default-agent-0
Capacity:
cpu: 24
ephemeral-storage: 1055762868Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
Allocatable:
cpu: 24
ephemeral-storage: 1027046117185
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
System Info:
Machine ID:
System UUID:
Boot ID: 8e6ef727-43a3-47b4-b08f-6f51e384394c
Kernel Version: 5.15.133.1-microsoft-standard-WSL2
OS Image: K3s dev
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.7.1-k3s1
Kubelet Version: v1.27.4+k3s1
Kube-Proxy Version: v1.27.4+k3s1
PodCIDR: 10.42.0.0/24
PodCIDRs: 10.42.0.0/24
ProviderID: k3s://k3d-k3s-default-agent-0
Non-terminated Pods: (1 in total) ## <<< AINDA TEMOS ESSE PODS DENTRO
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system svclb-traefik-15becd31-mrzbx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotSchedulable 4m10s kubelet Node k3d-k3s-default-agent-0 status is now: NodeNotSchedulable #<<<<
## Vamos comparar com outro node que possui pods
kubectl describe nodes k3d-k3s-default-agent-1
Name: k3d-k3s-default-agent-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=k3s
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k3d-k3s-default-agent-1
kubernetes.io/os=linux
node.kubernetes.io/instance-type=k3s
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"36:e0:49:2e:af:f7"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.18.0.2
k3s.io/hostname: k3d-k3s-default-agent-1
k3s.io/internal-ip: 172.18.0.2
k3s.io/node-args: ["agent"]
k3s.io/node-config-hash: GNY45P4EZT4AMDLCADCGJR3BA5KIFTXTP7YACNXMTZAVYI2VMO7A====
k3s.io/node-env:
{"K3S_KUBECONFIG_OUTPUT":"/output/kubeconfig.yaml","K3S_TOKEN":"********","K3S_URL":"https://k3d-k3s-default-server-0:6443"}
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 30 Dec 2023 10:59:08 -0300
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: k3d-k3s-default-agent-1
AcquireTime: <unset>
RenewTime: Mon, 01 Jan 2024 18:42:16 -0300
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:08 -0300 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Mon, 01 Jan 2024 18:41:25 -0300 Sat, 30 Dec 2023 10:59:09 -0300 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 172.18.0.2
Hostname: k3d-k3s-default-agent-1
Capacity:
cpu: 24
ephemeral-storage: 1055762868Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
Allocatable:
cpu: 24
ephemeral-storage: 1027046117185
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 7996960Ki
pods: 110
System Info:
Machine ID:
System UUID:
Boot ID: 8e6ef727-43a3-47b4-b08f-6f51e384394c
Kernel Version: 5.15.133.1-microsoft-standard-WSL2
OS Image: K3s dev
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.7.1-k3s1
Kubelet Version: v1.27.4+k3s1
Kube-Proxy Version: v1.27.4+k3s1
PodCIDR: 10.42.1.0/24
PodCIDRs: 10.42.1.0/24
ProviderID: k3s://k3d-k3s-default-agent-1
#################################################################################################################
# Veja que temos o nginx aqui
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h #<<<
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 6m46s
#################################################################################################################
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
## Para onde foi o outro pod?
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-rkvvp 1/1 Running 0 8m17s 10.42.2.13 k3d-k3s-default-server-0 <none> <none>
# O miserável foi pro server, O que não é boa ideia, mas ele foi, pois nesse cluster local, os master não estão com taints.
kubectl taint node k3d-k3s-default-server-0 nodeType=master:NoExecute
node/k3d-k3s-default-server-0 tainted
# Agora temos tudo no agent-1 que seria o único possível de receber.
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-g5z2d 1/1 Running 0 6s 10.42.1.31 k3d-k3s-default-agent-1 <none> <none>
kubectl describe nodes k3d-k3s-default-agent-1
...
ProviderID: k3s://k3d-k3s-default-agent-1
Non-terminated Pods: (7 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h #<<<<
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 14m
default nginx-7b8df77865-g5z2d 0 (0%) 0 (0%) 0 (0%) 0 (0%) 83s #<<<<
kube-system coredns-77ccd57875-mmlgl 100m (0%) 0 (0%) 70Mi (0%) 170Mi (2%) 83s
kube-system metrics-server-648b5df564-tb7ks 100m (0%) 0 (0%) 70Mi (0%) 0 (0%) 83s
Allocated resources:
# E temos os dois rodando no mesmo nó
Quando drenamos um node ele é marcado com um taint e os pods são removidos. Alguns pods não são removidos, pois são daemonset como visto acima e rodam obrigatoriamente 1 por node. Provavelmente no caso desse traefik aí, ele deve ter uma toleration para NoScheduler por isso ainda está presente.
Nenhum pod pode ser agendado para esse node a não ser que você remova a taint com a restrição.
O comando drain não necessariamente move os pods, mas mata o pod e este volta para a fila para ser agendado. Quando voltar na etapa de filtragem o node que eles estava não será escolhido.
A partir de agora poderíamos trabalhar em cima desse node e fazer os upgrades necessários com segurança.
Para remover a taint específica criada pelo drain usamos o comando uncordon.
kubectl uncordon k3d-k3s-default-agent-0
node/k3d-k3s-default-agent-0 uncordoned
kubectl describe nodes k3d-k3s-default-agent-0
Name: k3d-k3s-default-agent-0
...
CreationTimestamp: Sat, 30 Dec 2023 10:59:09 -0300
Taints: <none> #<<<<
Unschedulable: false
...
Non-terminated Pods: (1 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system svclb-traefik-15becd31-mrzbx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 0 (0%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotSchedulable 23m kubelet Node k3d-k3s-default-agent-0 status is now: NodeNotSchedulable
Normal NodeSchedulable 19s kubelet Node k3d-k3s-default-agent-0 status is now: NodeSchedulable #<<<<
Quando um node volta, o Kubernetes não tenta redistribuir a carga, ele simplesmente fica disponível para novos pods. Isso só aconteceria se o pod terminasse e um controller tentasse encontrar um novo node para ele.
O comando cordon marca um node como não agendado, mas não mata os pods. O drain faz as duas coisas.
kubectl cordon k3d-k3s-default-agent-1
node/k3d-k3s-default-agent-1 cordoned
kubectl describe nodes k3d-k3s-default-agent-1 | grep Unschedulable
Unschedulable: true
kubectl describe nodes k3d-k3s-default-agent-1
Name: k3d-k3s-default-agent-1
...
CreationTimestamp: Sat, 30 Dec 2023 10:59:08 -0300
Taints: node.kubernetes.io/unschedulable:NoSchedule
Unschedulable: true
Non-terminated Pods: (7 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-7b8df77865-gt6fd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d7h
kube-system traefik-64f55bb67d-x8d4f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d8h
kube-system svclb-traefik-15becd31-6qjqz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d8h
kube-system local-path-provisioner-957fdf8bc-rdr26 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
default nginx-7b8df77865-g5z2d 0 (0%) 0 (0%) 0 (0%) 0 (0%) 15m
kube-system coredns-77ccd57875-mmlgl 100m (0%) 0 (0%) 70Mi (0%) 170Mi (2%) 15m
kube-system metrics-server-648b5df564-tb7ks 100m (0%) 0 (0%) 70Mi (0%) 0 (0%) 15m
...
Normal NodeNotSchedulable 16s kubelet Node k3d-k3s-default-agent-1 status is now: NodeNotSchedulable
# Agora vamos escalar esse nginx para 10 e vamos ver pra onde ele vai
kubectl scale deployment nginx --replicas 10
deployment.apps/nginx scaled
# Foi tudo pro node agent-0
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7b8df77865-gt6fd 1/1 Running 1 (2d5h ago) 2d7h 10.42.1.9 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-g5z2d 1/1 Running 0 17m 10.42.1.31 k3d-k3s-default-agent-1 <none> <none>
nginx-7b8df77865-j4tn4 1/1 Running 0 7s 10.42.0.15 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-tnnkc 1/1 Running 0 7s 10.42.0.12 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-hlq69 1/1 Running 0 7s 10.42.0.14 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-5h7bx 1/1 Running 0 7s 10.42.0.11 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-w6wxz 1/1 Running 0 7s 10.42.0.13 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-5vjv4 1/1 Running 0 7s 10.42.0.16 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-hvwpn 1/1 Running 0 7s 10.42.0.17 k3d-k3s-default-agent-0 <none> <none>
nginx-7b8df77865-vgrrz 1/1 Running 0 7s 10.42.0.18 k3d-k3s-default-agent-0 <none> <none>