Clair: Uma Alternativa ao Trivy

O clair é um scanner de vulnerabilidade para container.
Vamos direto ao ponto que é comparar o Clair com o Trivy.
-
Capacidades de varredura: Ambos podem escanear vulnerabilidades em imagens de contêiner, mas o Clair tem um banco de dados de vulnerabilidades mais extenso e podendo escanear uma gama maior de vulnerabilidades.
-
Facilidade de uso: Clair é um pouco mais complexo de configurar e usar do que o Trivy.
-
Integração: ambos podem ser integrados em pipelines de CI/CD e fluxos de trabalho DevOps, mas o Trivy tem mais integrações com outras ferramentas e plataformas, como Kubernetes e Helm.
-
Desempenho: O Trivy é geralmente mais rápido e leve que o Clair, o que o torna uma escolha melhor para organizações com grandes ambientes de contêineres ou que precisam de digitalização rápida.
Por que usar o clair então? Cada ferramenta usa abordagens diferentes para verificar a vulnerabilidade, então usar mais de uma reduzirá as chances de vulnerabilidade. Como diz o ditado "o seguro morreu de velho".
Mas tudo isso depende dos casos de uso e de qual ferramenta é mais adequada às suas necessidades.
Arquitetura
A maneira mais fácil de rodar o Clair é em um ambiente local.
O Clair utiliza um banco de dados Postgres para:
- Armazenamento de Vulnerabilidades: O Clair mantém um banco de dados local de vulnerabilidades, obtido de diversas fontes como NVD, Ubuntu, Alpine, Red Hat, etc.
- Indexação de Camadas de Imagem: Quando uma imagem de contêiner é escaneada, cada camada é analisada e os metadados resultantes (como pacotes de software e suas versões) são armazenados no banco de dados.
- Comparação Rápida: Usando um banco de dados, o Clair pode rapidamente comparar os pacotes detectados em uma imagem com as vulnerabilidades conhecidas.

Essa é uma das diferenças com o Trivy, a facilidade de uso.
É possível deployar o Clair de forma distribuída, mas já é um recurso mais avançado que deve ser estudado quando entender melhor a arquitetura da ferramenta estiver sendo bastante utilizada. Por agora vamos utilizar somente um banco para tudo, mas vale saber como funciona realmente.
O Clair pode ser deployado de diferentes modos sendo que o modo COMBO é o all in one, ou seja, não é distribuido. Podemos apontar todos os componentes (indexer, matcher e notifier) para o mesmo banco ou separar os bancos.
No mesmo banco a configuração ficaria assim, que é o exatamente o vamos fazer.
...
indexer:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
matcher:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
...
notifier:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
...
Para bancos separados ficaria assim.
...
indexer:
connstring: "host=indexer-clairdb user=clair dbname=clair sslmode=verify-full"
matcher:
connstring: "host=matcher-clairdb user=clair dbname=clair sslmode=verify-full"
...
notifier:
connstring: "host=notifier-clairdb user=clair dbname=clair sslmode=verify-full"
...
Então a arquitetura ficaria assim.

Se a demanda for alta suficiente para precisar de um deploy distribuído cada um dos processos, indexer matcher e notifier poderia estar separados e cada um com o seu banco ou para um banco só, mas isso seria um gargalo que não iamos querer.
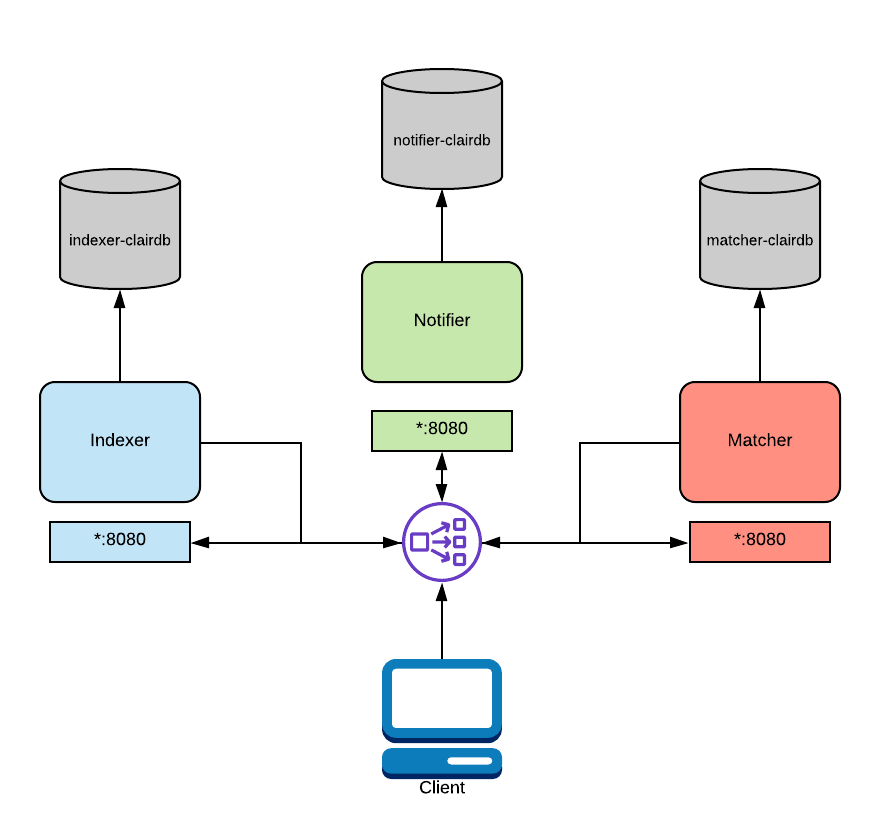
No diagrama acima, um balanceador de carga é configurado para rotear o tráfego vindo do cliente para o serviço correto. Esse roteamento é baseado em caminho e requer um balanceador de carga de camada 7. Traefik, Nginx e HAProxy são todos capazes disso. Como mencionado acima, essa funcionalidade é nativa do OpenShift e do Kubernetes.
Indexer: A indexação envolve pegar um manifesto representando uma imagem de contêiner e computar suas partes constituintes. O indexador está tentando descobrir quais pacotes existem na imagem, de qual distribuição a imagem é derivada e quais repositórios de pacotes são usados dentro da imagem. Uma vez que essas informações são computadas, elas são persistidas em um IndexReport.Matcher: Executa um conjunto de Updaters que periodicamente sondam suas fontes de dados em busca de novos conteúdos, armazenando novas vulnerabilidades no banco de dados quando descobertas. Esse serviço é chamado frequentemente e fornecerá o VulnerabilityReport mais atualizado quando consultado. Este VulnerabilityReport resume tanto o conteúdo de um manifesto quanto quaisquer vulnerabilidades que afetam o conteúdo.Notifier: O serviço de notificação acompanhará novas atualizações do banco de dados de segurança e informará um cliente interessado se vulnerabilidades novas ou removidas afetarem um manifesto indexado.
Resumindo, se uma imagem foi computada o dados da camada serão guardados. Se uma CVE aparecer no futuro para ela você conseguirá saber sem fazer a reanalise das imagens.
O Trivy trabalha dentro do cluster analisando períodicamente as imagens, ou seja, a varredura é constante. Já o Clair faz o scanner persiste os dados e com e com os dados de cada camada do container ele consegue saber se terá ou não a CVE.
Deploy
No modo combo, que roda tudo em um único lugar, vamos criar um docker compose para subir o ambiente.
version: "3.7"
# This is just to hold a bunch of yaml anchors and try to consolidate parts of
# the config.
x-anchors:
postgres: &postgres-image docker.io/library/postgres:12
clair: &clair-image quay.io/projectquay/clair:4.7.4
services:
combo::q!
image: &clair-image
depends_on:
clair-database:
condition: service_healthy
volumes:
- "./docker-compose-data/clair-config/:/config/:ro"
- "./docker-compose-data/clair-tmp/:/tmp/:rw"
command: ["-conf", "/config/config.yaml"]
restart: unless-stopped
environment:
CLAIR_MODE: "combo"
networks:
- clair-network
clair-database:
container_name: clair-database
image: *postgres-image
environment:
POSTGRES_DB: clair
POSTGRES_USER: clair
POSTGRES_PASSWORD: clair_password
healthcheck:
test:
- CMD-SHELL
- "pg_isready -U postgres"
interval: 5s
timeout: 4s
retries: 12
start_period: 10s
volumes:
- ./docker-compose-data/postgres-data/:/var/lib/postgresql/data:rw
networks:
- clair-network
restart: unless-stopped
networks:
clair-network:
driver: bridge
version: '3'
services:
clair:
image: quay.io/projectquay/clair:4.7.4
restart: unless-stopped
command: [-config, /config/config.yaml]
ports:
- "6060:6060" # Porta da API do Indexer
- "6061:6061" # Porta da API do Matcher
environment:
- CLAIR_MODE=combo # Todos os serviços habilitado
- CLAIR_DATABASE_HOST=postgres
- CLAIR_DATABASE_USER=clair
- CLAIR_DATABASE_PASSWORD=clair_password
- CLAIR_DATABASE_NAME=clair
volumes:
- ./docker-compose-data/clair-config/:/config/:ro
- ./docker-compose-data/clair-tmp/:/tmp/:rw
depends_on:
postgres:
condition: service_started
networks:
- clair-network
networks:
clair-network:
driver: bridge
Se quiser instalar o postgree, fazer o download do clairctl e apontar o banco nas chamadas e no arquivo de configuração funciona também, mas é muito mais trabalhoso.
Observe que precisamos de um arquivo de configuração que vamos criar chamado clair-config É só um arquivo chave valor para definições. Esse arquivo nada mais faz do que subir utilizar essas chaves e valore para variáveis de ambiente.