Clair: Una Alternativa a Trivy

Clair es un escáner de vulnerabilidades para contenedores.
Vamos directamente al punto que es comparar Clair con Trivy.
-
Capacidades de escaneo: Ambos pueden escanear vulnerabilidades en imágenes de contenedor, pero Clair tiene una base de datos de vulnerabilidades más extensa y puede escanear una gama mayor de vulnerabilidades.
-
Facilidad de uso: Clair es un poco más complejo de configurar y usar que Trivy.
-
Integración: ambos pueden integrarse en pipelines de CI/CD y flujos de trabajo DevOps, pero Trivy tiene más integraciones con otras herramientas y plataformas, como Kubernetes y Helm.
-
Rendimiento: Trivy es generalmente más rápido y ligero que Clair, lo que lo convierte en una mejor opción para organizaciones con grandes entornos de contenedores o que necesitan escaneo rápido.
¿Por qué usar Clair entonces? Cada herramienta usa enfoques diferentes para verificar vulnerabilidades, así que usar más de una reducirá las posibilidades de vulnerabilidad. Como dice el refrán "más vale prevenir que curar".
Pero todo esto depende de los casos de uso y de qué herramienta es más adecuada para tus necesidades.
Arquitectura
La manera más fácil de ejecutar Clair es en un entorno local.
Clair utiliza una base de datos Postgres para:
- Almacenamiento de Vulnerabilidades: Clair mantiene una base de datos local de vulnerabilidades, obtenida de diversas fuentes como NVD, Ubuntu, Alpine, Red Hat, etc.
- Indexación de Capas de Imagen: Cuando una imagen de contenedor es escaneada, cada capa es analizada y los metadatos resultantes (como paquetes de software y sus versiones) son almacenados en la base de datos.
- Comparación Rápida: Usando una base de datos, Clair puede comparar rápidamente los paquetes detectados en una imagen con las vulnerabilidades conocidas.

Esta es una de las diferencias con Trivy, la facilidad de uso.
Es posible desplegar Clair de forma distribuida, pero ya es un recurso más avanzado que debe estudiarse cuando se entienda mejor la arquitectura de la herramienta y esté siendo bastante utilizada. Por ahora vamos a utilizar solamente una base de datos para todo, pero vale la pena saber cómo funciona realmente.
Clair puede ser desplegado en diferentes modos siendo que el modo COMBO es el all in one, es decir, no está distribuido. Podemos apuntar todos los componentes (indexer, matcher y notifier) a la misma base de datos o separar las bases de datos.
En la misma base de datos la configuración quedaría así, que es exactamente lo que vamos a hacer.
...
indexer:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
matcher:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
...
notifier:
connstring: "host=clairdb user=clair dbname=clair sslmode=verify-full"
...
Para bases de datos separadas quedaría así.
...
indexer:
connstring: "host=indexer-clairdb user=clair dbname=clair sslmode=verify-full"
matcher:
connstring: "host=matcher-clairdb user=clair dbname=clair sslmode=verify-full"
...
notifier:
connstring: "host=notifier-clairdb user=clair dbname=clair sslmode=verify-full"
...
Entonces la arquitectura quedaría así.

Si la demanda fuera lo suficientemente alta para necesitar un despliegue distribuido cada uno de los procesos, indexer matcher y notifier podría estar separado y cada uno con su base de datos o para una base de datos sola, pero esto sería un cuello de botella que no querríamos.
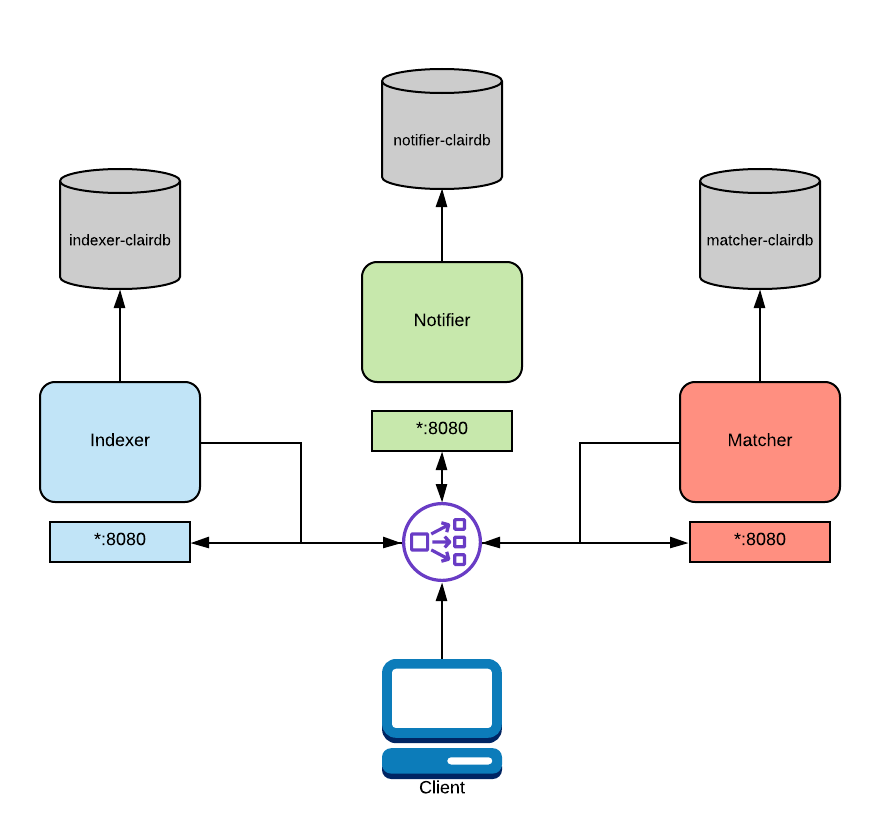
En el diagrama anterior, un balanceador de carga está configurado para enrutar el tráfico proveniente del cliente al servicio correcto. Este enrutamiento se basa en la ruta y requiere un balanceador de carga de capa 7. Traefik, Nginx y HAProxy son todos capaces de esto. Como se mencionó anteriormente, esta funcionalidad es nativa de OpenShift y Kubernetes.
Indexer: La indexación implica tomar un manifiesto que representa una imagen de contenedor y calcular sus partes constituyentes. El indexador está intentando descubrir qué paquetes existen en la imagen, de qué distribución se deriva la imagen y qué repositorios de paquetes se usan dentro de la imagen. Una vez que esta información se calcula, se persiste en un IndexReport.Matcher: Ejecuta un conjunto de Updaters que periódicamente sondean sus fuentes de datos en busca de nuevos contenidos, almacenando nuevas vulnerabilidades en la base de datos cuando se descubren. Este servicio se llama frecuentemente y proporcionará el VulnerabilityReport más actualizado cuando sea consultado. Este VulnerabilityReport resume tanto el contenido de un manifiesto como cualquier vulnerabilidad que afecte el contenido.Notifier: El servicio de notificación hace seguimiento de nuevas actualizaciones de la base de datos de seguridad e informará a un cliente interesado si vulnerabilidades nuevas o eliminadas afectan un manifiesto indexado.
Resumiendo, si una imagen fue calculada los datos de la capa serán guardados. Si un CVE aparece en el futuro para ella podrás saber sin hacer el reanálisis de las imágenes.
Trivy trabaja dentro del clúster analizando periódicamente las imágenes, es decir, el escaneo es constante. Ya Clair hace el escaneo, persiste los datos y con los datos de cada capa del contenedor consigue saber si tendrá o no el CVE.
Despliegue
En el modo combo, que ejecuta todo en un único lugar, vamos a crear un docker compose para levantar el entorno.
version: "3.7"
# Esto es solo para mantener un montón de anclas yaml e intentar consolidar partes de
# la configuración.
x-anchors:
postgres: &postgres-image docker.io/library/postgres:12
clair: &clair-image quay.io/projectquay/clair:4.7.4
services:
combo::q!
image: &clair-image
depends_on:
clair-database:
condition: service_healthy
volumes:
- "./docker-compose-data/clair-config/:/config/:ro"
- "./docker-compose-data/clair-tmp/:/tmp/:rw"
command: ["-conf", "/config/config.yaml"]
restart: unless-stopped
environment:
CLAIR_MODE: "combo"
networks:
- clair-network
clair-database:
container_name: clair-database
image: *postgres-image
environment:
POSTGRES_DB: clair
POSTGRES_USER: clair
POSTGRES_PASSWORD: clair_password
healthcheck:
test:
- CMD-SHELL
- "pg_isready -U postgres"
interval: 5s
timeout: 4s
retries: 12
start_period: 10s
volumes:
- ./docker-compose-data/postgres-data/:/var/lib/postgresql/data:rw
networks:
- clair-network
restart: unless-stopped
networks:
clair-network:
driver: bridge
version: '3'
services:
clair:
image: quay.io/projectquay/clair:4.7.4
restart: unless-stopped
command: [-config, /config/config.yaml]
ports:
- "6060:6060" # Puerto de la API del Indexer
- "6061:6061" # Puerto de la API del Matcher
environment:
- CLAIR_MODE=combo # Todos los servicios habilitados
- CLAIR_DATABASE_HOST=postgres
- CLAIR_DATABASE_USER=clair
- CLAIR_DATABASE_PASSWORD=clair_password
- CLAIR_DATABASE_NAME=clair
volumes:
- ./docker-compose-data/clair-config/:/config/:ro
- ./docker-compose-data/clair-tmp/:/tmp/:rw
depends_on:
postgres:
condition: service_started
networks:
- clair-network
networks:
clair-network:
driver: bridge
Si quieres instalar postgres, hacer la descarga de clairctl y apuntar la base de datos en las llamadas y en el archivo de configuración funciona también, pero es mucho más trabajoso.
Observa que necesitamos un archivo de configuración que vamos a crear llamado clair-config. Es solo un archivo clave-valor para definiciones. Este archivo nada más hace que levantar utilizando esas claves y valores para variables de entorno.