OAuth2
¿Ya te has parado a pensar cómo funciona ese sistema de login con cuentas de Google, GitHub, Facebook, LinkedIn, etc? ¿Cómo estas aplicaciones consiguen acceso a tus datos sin necesitar tu contraseña?
Si trabajas con TI, entender cómo funciona la seguridad de APIs y autenticación es esencial. Vivimos en un mundo donde todo está interconectado — y la base de esa integración segura se llama OAuth2 y OpenID Connect (OIDC).
Hoy en día, cuando haces login con tu cuenta de otro servicio, la mayoría de las veces estás usando OAuth2 sin ni siquiera percibirlo. Es el protocolo que permite que apps accedan a tus datos sin nunca ver tu contraseña. El OIDC entra como una capa encima de OAuth2 para permitir login de verdad, con identidad del usuario.
Esta documentación fue hecha para ayudarte a entender, de forma simple, cómo funciona todo esto por detrás. No vamos a sumergirnos en todos los detalles técnicos, pero saldrás de aquí con una base sólida para profundizar tus estudios cuando quieras.
Conceptos Básicos
Vamos a simplificar con una historieta:
Un usuario (user), usando un navegador (client), quiere acceder a una aplicación — el llamado Service Provider (SP). Esta app necesita saber quién es el usuario. Pero, en vez de guardar las credenciales localmente, pide ayuda a un Identity Provider (IdP), como Google o Azure AD.
El IdP autentica al usuario y envía una señal a la app diciendo: "este tipo es quien dice ser". Puede incluir información extra: nombre, email, foto, grupos... Todo esto sin compartir la contraseña.
Por cierto, la mayoría de las empresas hoy usa algún tipo de Identity Provider basado en LDAP — generalmente el Active Directory de Microsoft. Probablemente ya hayas oído ese nombre, incluso sin saber exactamente qué era. El IdP concentra toda la información del usuario: nombre, email, teléfono, foto, biometría (huella, iris), grupos de acceso y, claro, la contraseña. Su papel es garantizar: "esta persona es quien dice ser" — y avisar al Service Provider: "puede seguir, es él mismo".
La gran jugada de tener un IdP es centralizar todo en un sistema único, accesible por varias aplicaciones al mismo tiempo. Si actualizas algo en el IdP, ese cambio se refleja en todo el ecosistema.
Autenticación ≠ Autorización
- El IdP autentica: verifica quién eres.
- La aplicación autoriza: decide qué puedes hacer.
¿Cómo el IdP prueba quién eres?
Con base en factores de autenticación. Puede ser uno solo o una combinación:
- Algo que solo tú sabes: contraseña, preguntas de seguridad.
- Algo que solo tú posees: token, certificado, móvil.
- Algo que es único en ti: huella, iris.
Lo que puedes hacer (autorización) es otra historia. Esa es una responsabilidad de la aplicación o del servicio saber si puedes o no hacer algo, pero para eso también puede usar información que está en el IdP, principalmente de grupos. Si el usuario es miembro del grupo de admins entonces muestra otros tipos de información. Observa que el IdP no autorizó nada, solo informó el grupo, pero quien permitió fue la aplicación.
LDAP Básico
Estudiar LDAP aún tiene sentido, pero con enfoque estratégico. No está muerto, pero tampoco es más el protagonista.
¿Cuándo vale la pena profundizar?
- Infraestructura Corporativa Heredada
- Entornos Linux corporativos: Autenticación centralizada con OpenLDAP, SSSD, FreeIPA y es ideal para DevSecOps/Platform Eng. que trabaja con servidores e IAM. Vamos a dividir esto en partes:
- Integraciones de autenticación con servicios que exigen LDAP. A veces es más fácil conectar directo vía LDAP que hacer SSO vía SAML
- Cuando Azure AD Domain Services entra en juego, especialmente en escenarios híbridos on-prem más + Azure + AWS.
No necesitas convertirte en especialista hardcore, pero entender la historia y las bases técnicas es esencial.
Antes del IdP moderno:
- Cada app guardaba su propio banco de usuarios
- Contraseñas y datos sensibles en el mismo banco de la aplicación
- Desarrolladores tenían acceso a datos personales
- Ninguna estandarización entre apps
- Eliminar o alterar permisos era un caos manual
- ¿Auditoría y compliance? Casi imposible
Fue ahí que entró LDAP, y después el Active Directory, para organizar la casa. Se convirtió en el "banco central" de identidades.
LDAP tradicional no fue hecho para Internet. Incluso con LDAPS (versión segura), abrirlo al mundo es peligroso incluso que usemos VPN, Direct Connect, peering de VPC, etc.
- LDAP simple transmite contraseñas en texto claro (sin LDAPS)
- Kerberos no maneja bien NAT/firewalls — depende de tiempo sincronizado y tickets en tiempo real
- Alta latencia puede romper autenticación — causa timeouts, fallos de login
- Superficie de ataque aumenta — exponer el AD es abrir una puerta para ataques, incluso con firewalls y ACLs
Técnicamente el AD y la aplicación pueden residir en datacenters diferentes, pero en términos de seguridad no es un buen escenario. Exponer el AD está fuera de consideración y solo debería estar accesible en la intranet.
Por causa de ese escenario fue necesario cambiar la arquitectura y pasar al SAML. Esta lectura vale la pena para entender básicamente cómo resolvió ese escenario y cuáles limitaciones aún existen.
Protocolo OAuth2
Permite que aplicaciones de terceros accedan a recursos en nombre de un usuario, sin que el usuario necesite compartir su contraseña con esas aplicaciones. Sería como un poder notarial registrado en notaría para que la aplicación de terceros acceda en nombre del usuario a algún recurso de este usuario en algún lugar.
Conceptos Clave
Resource Owner (Usuario): Quien posee los datos (ej: tú).Client (Aplicación): Quien quiere acceder a los datos (ej: una app de calendario queriendo acceder a tus eventos de Google Calendar). Puede ser cualquier tipo de aplicación, frontend, backend, móvil, etc.Authorization Server: Quien autentica al usuario y emite tokens (ej: accounts.google.com).Resource Server: API que protege los datos (ej: api.google.com/calendar).
Para presentar los conceptos presentamos el siguiente escenario:
- Una aplicación quiere acceder a los datos del calendario de Google del usuario.
- Los datos, que son los recursos, están almacenados en la base de datos.
- Para proteger el acceso a esos datos tenemos una API. En el caso de Google es
api.google.com/calendar. - La aplicación necesita tener acceso solo a los datos del usuario, pero con permiso limitado solo a lo que necesita hacer.
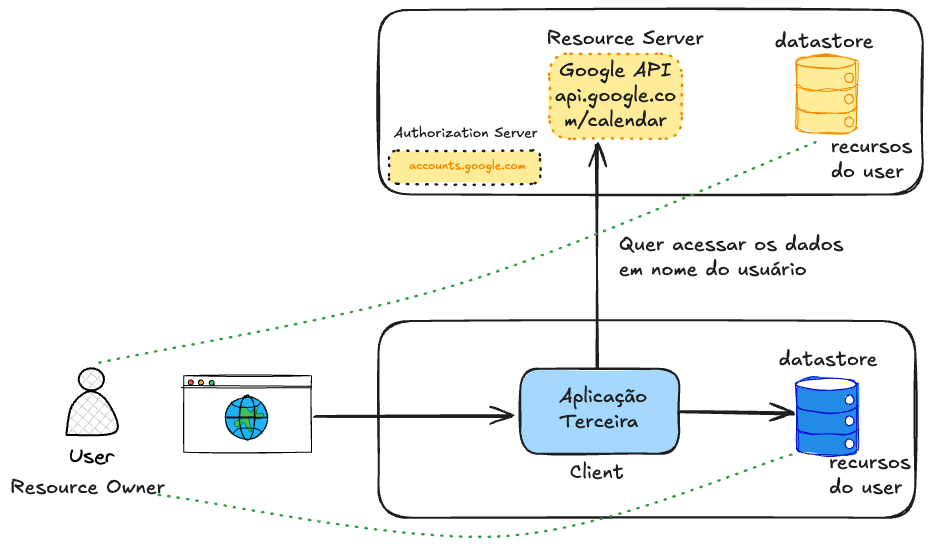
Haciendo una analogía, esa aplicación necesita ir a la notaría y conseguir un poder para que hable en nombre del usuario. El usuario necesita dar ese permiso avisando que permite que tales recursos estén disponibles para esa aplicación durante un tiempo específico.
Observa que el Authorization Server protege la API. En el caso de Google tenemos el Authorization Server de Google, pero si quisiéramos acceder al calendario de Microsoft, sería necesario acceso a otra API con un Authorization Server diferente, dedicado a los recursos de Microsoft. Otro token sería generado para acceso a la API de Microsoft.
El permiso es dado a través de ámbitos (Scopes), que son las políticas.
Ese poder no es más que un token, es decir, una credencial, en la cuenta del usuario pero con límites de acceso. En la mayoría de los casos ese token tiene tiempo de vida. Ese token poseerá un scope específico, por ejemplo, scope=calendar.read calendar.write.
Con certeza ya tuviste una experiencia de un pop-up apareciendo para que hagas login en tu cuenta para dar algún tipo de acceso. Al conceder ese tipo de acceso, en verdad lo que está sucediendo es la creación de un token específico solo para esa cuenta.
Comparando ese escenario con lo que pasa en SAML ya podemos observar que una aplicación conversa directamente con otra sin la necesidad de hacer un redirect vía navegador.
| Recurso | OAuth2 | SAML |
|---|---|---|
| Propósito | Autorización (con OIDC: login) | Autenticación y Autorización |
| Tipo de token | JSON (normalmente JWT) | XML (SAML Assertions) |
| Transporte | HTTP (generalmente vía REST) | XML vía POST/Redirect |
| Formato | Ligero, moderno, fácil de leer | Verboso, XML |
| Usado en | APIs, SPAs, móvil, apps web | Enterprise (SSO corporativo) |
| Complejidad | Simple/moderno | Más complejo |
| Soporte Móvil | Sí | Débil |
| Compatibilidad con JSON | Sí | No |
| ¿Estándar extensible? | Sí | Limitado |
Otro concepto a mencionar es el tiempo de vida de un token (Lifetime e Expiración). Existen dos tipos de token:
- Access token tiene vida corta (~1h).
- Refresh token puede durar días/semanas (pero puede ser revocado).
Authorization Server
En verdad, antes de hacer la petición a la API deseada, es necesario conseguir el token de acceso con los debidos permisos. Vamos a crear un flujo inicial para explicar la teoría, aún no es el flujo completo, solo un esbozo inicial.
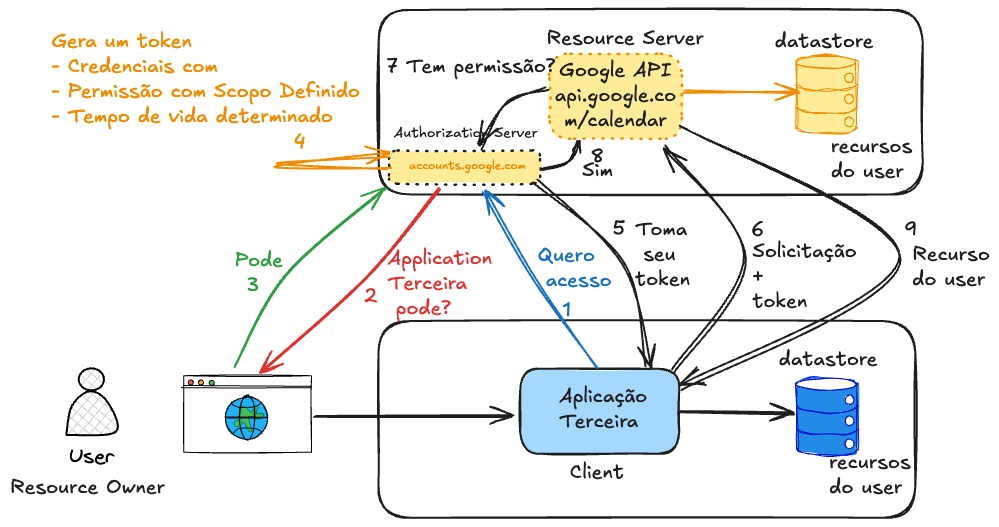
Al conseguir acceso la primera vez la aplicación debe guardar ese token por un período de tiempo en su base de datos para que la segunda vez no necesite rehacer la solicitud al usuario si el token aún está con tiempo de vida válido.
Hablando sobre la seguridad de esas transacciones.
¿Cómo un Authorization Server sabe que la petición de acceso está viniendo de un client válido? ¿Cómo tener certeza de que alguien no está intentando crear una request y enviándola en lugar de la aplicación real?
Tenemos previamente que hacer el registro del client en el Authorization Server que queremos acceder. No existe una forma segura de usar OAuth2 sin registro previo del client en el Authorization Server. Ese registro es lo que autoriza al client a participar del flujo. Sin eso, el Authorization Server no tiene cómo validar nada.
Esto puede ser hecho de dos formas:
- Manual (más común):
- Admins registran los clients vía panel web del Authorization Server (ej: Keycloak, Auth0, Okta, Google, Facebook, GitHub, LinkedIn, Apple...)
- Ideal para apps que controlas o cuando el ambiente es más cerrado.
- Automático (dinámico):
-
Vía Dynamic Client Registration (RFC 7591)
-
El client se auto-registra vía API.
-
Ejemplo: el client envía sus datos a un endpoint del Authorization Server, tipo:
POST /register
Content-Type: application/json
{
"client_name": "mi_app",
"redirect_uris": ["https://miapp.com/callback"],
"grant_types": ["authorization_code"],
"token_endpoint_auth_method": "none"
}Y tendríamos una respuesta parecida a esto.
{
"client_id": "generado_automaticamente",
"client_secret": "si_es_confidencial"
}
-
Algunos IdP soportan esto, pero generalmente necesita habilitar/configurar con cuidado (control de quién puede registrarse). Esto es más usado en entornos dinámicos, tipo federated login o SaaS que acepta apps de terceros.
El propio Google y Facebook no soportan esto. A pesar de que algunos Authorization Server sean capaces de hacer esto, siempre es bueno mantener esa etapa manual mientras sea posible para evitar posibles ataques.
El Authorization Server (AS) graba en su base de datos una ficha con los datos del client.
| Campo | Qué es |
|---|---|
client_id | Identificador único del client (generado o definido) |
client_secret (opcional) | Contraseña usada para autenticar (solo en apps confidenciales) |
redirect_uris | URLs permitidas para redirección (evita phishing) |
grant_types | Flujos autorizados (ej: authorization_code, client_credentials) |
scopes permitidos | Qué permisos el client puede pedir (ej: email, profile) |
token_endpoint_auth_method | Cómo el client se autentica en el token endpoint (ej: client_secret_post, none, etc) |
client_name | Nombre amigable (mostrado al usuario en la pantalla de consentimiento) |
logo_uri (opcional) | Logo del app, para pantalla de consentimiento |
contacts (opcional) | Emails de los responsables |
jwks_uri o jwks | (Para apps que firman tokens o usan mTLS) |
El AS genera un client_id único y guarda esos datos en algún lugar, generalmente algún software como Vault, Cyberark o hasta mismo una base de datos relacional. Si es confidencial (backend, etc), genera también un client_secret. Esos dos valores son como usuario/contraseña del client. Una de las informaciones más importantes son las URLs de redirección.
Cuando el client haga cualquier petición, el AS consulta esa ficha, verifica si el flujo (grant_type), redirect URI, scopes, etc están permitidos y si algo está fuera de la ficha rechaza la petición. Existen varios tipos de flujo, pero hablaremos sobre eso adelante en Grant Types.
El proceso exacto de registro depende del Authorization Server, no es el mismo para todos.
Opaque Token
Al hacer la solicitud, el Authorization Server sabrá de los permisos de acuerdo con el token pasado. Este es el famoso Bearer Token que es token que parece una string aleatoria, tipo:
d7f1b5b6-8a9c-4e33-98de-44c6f7ad0f4e
La cuestión es que no lleva info legible (diferente de un JWT) por eso llamado opaque. Es solo una referencia a un token válido, que solo el Authorization Server consigue interpretar. Bearer tokens son usados como Access Token, principalmente cuando:
- Seguridad es prioridad (menos riesgo de filtración de info)
- Quieres centralizar la validación en el Authorization Server
- El Resource Server necesita siempre llamar al Auth Server para validar el token
-
El cliente pide un token al Authorization Server
-
El Authorization Server retorna el opaque token caso el usuario permita.
-
El cliente usa el token para acceder a una API
-
La API envía ese token de vuelta al Authorization Server (o lo introspecciona) para ver si:
- Es válido
- No expiró
- Está asociado al usuario X
- Tiene los scopes correctos
-
El authorization server retorna la respuesta a la API siendo lo más importante el scope de ese token.
-
La API con el scope y las informaciones correctas puede autorizar o rechazar la petición.
Es importante mencionar que el token posee un tiempo de validez que puede ser configurado dependiendo del Authorization Server. En el caso de Google es de 60 minutos. Generalmente IdP servers poseen ese tipo de configuración, como Keycloak por ejemplo.
El cuello de botella del Opaque Token es que toda petición a la API exige una ida hasta el Authorization Server para validar el token.
Imagina 100k requests por minuto para tu API. Si cada una hace introspection:
- Saturas el Auth Server
- La API se vuelve más lenta (latencia aumenta)
- Posibles timeouts, errores 5xx y caídas
- Puede convertirse en un SPOF (Single Point of Failure)
JWT Token
Si el token cargara toda información necesaria, no sería necesaria esa llamada al Authorization Server para buscar los scopes y validar el token.
JWT (JSON Web Token) es un token auto-contenido, que carga información dentro de él mismo, de forma segura y compacta, en formato JSON, codificado con base64.
Un JWT está dividido en 3 partes, separadas por .. Veremos una string enorme, pero si reparas bien existen algunos puntos en el medio. El header, payload y signature contienen mucho más campos de los que vamos a demostrar, pero vamos primero a andar después correr.
La string abajo fue dividida para demostrar los puntos.
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9. --> Header
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvZSIsImlhdCI6MTYwOTAwMDAwMH0. --> Payload
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c --> Signature
-
Header - Dice cuál algoritmo fue usado en la firma (ej: HS256, RS256)
❯ echo "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9" | base64 --decode
{"alg":"HS256","typ":"JWT"}% -
Payload - Carga los datos (claims)
❯ echo "eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvZSIsImlhdCI6MTYwOTAwMDAwMH0" | base64 --decode
{"sub":"1234567890","name":"Joe","iat":160900000} -
Signature - Sirve para verificar si el token no fue alterado. Assinatura = HMAC_SHA256(base64url(header) + "." + base64url(payload), clave_secreta).
Ventajas:
- Validación local (sin llamar al Auth Server)
- Rendimiento alto en grandes sistemas
- Fácil de pasar entre sistemas
- Soporta firmas con clave pública/privada
Vamos a analizar un JWT Token más elaborado, pero fake aún.
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCIsImtpZCI6IjEyMzQ1NiJ9.eyJpc3MiOiJodHRwczovL2FjY291bnRzLmdvb2dsZS5jb20iLCJhdWQiOiJ5b3VyLWNsaWVudC1pZC5hcHBzLmdvb2dsZXVzZXJjb250ZW50LmNvbSIsInN1YiI6IjExMjIzMzQ0NTU1NjY3NyIsImVtYWlsIjoiam9hb0BleGFtcGxlLmNvbSIsImVtYWlsX3ZlcmlmaWVkIjp0cnVlLCJzY29wZSI6InJlYWRfdXNlciB3cml0ZV9jb250ZW50IiwiaWF0IjoxNzE2ODAwMDAwLCJleHAiOjE3MTY4MDM2MDB9.Lj9sOH4ZyNzKxjEf1mGZdYeEQZleJqmb5Mg5k1nhFA8i9ZK6u2nCwZWzdk0rY6bCehgNfCvE9SLs9FSG9A
Verificando la parte central (payload) tenemos esto.
{
"iss": "https://accounts.google.com",
"aud": "your-client-id.apps.googleusercontent.com",
"sub": "112233445556677",
"email": "[email protected]",
"email_verified": true,
"scope": "read_user write_content",
"iat": 1716800000,
"exp": 1716803600
}
| Claim | Descripción |
|---|---|
iss | Quién emitió el token (issuer) |
aud | Quién debe aceptar ese token (client_id) |
sub | ID único del usuario (Subject) |
email | Email del usuario |
scope | Permisos dados por el usuario |
iat | Emitido en (issued at - timestamp) |
exp | Expira en (expiration time - timestamp) |
Cuanto menor el tiempo de vida del access token, menor el impacto si se filtra. Y como el access token da acceso directo a los recursos protegidos, es altamente sensible.
Authorization Code Flow
¿Entonces cómo sería el flujo completo?
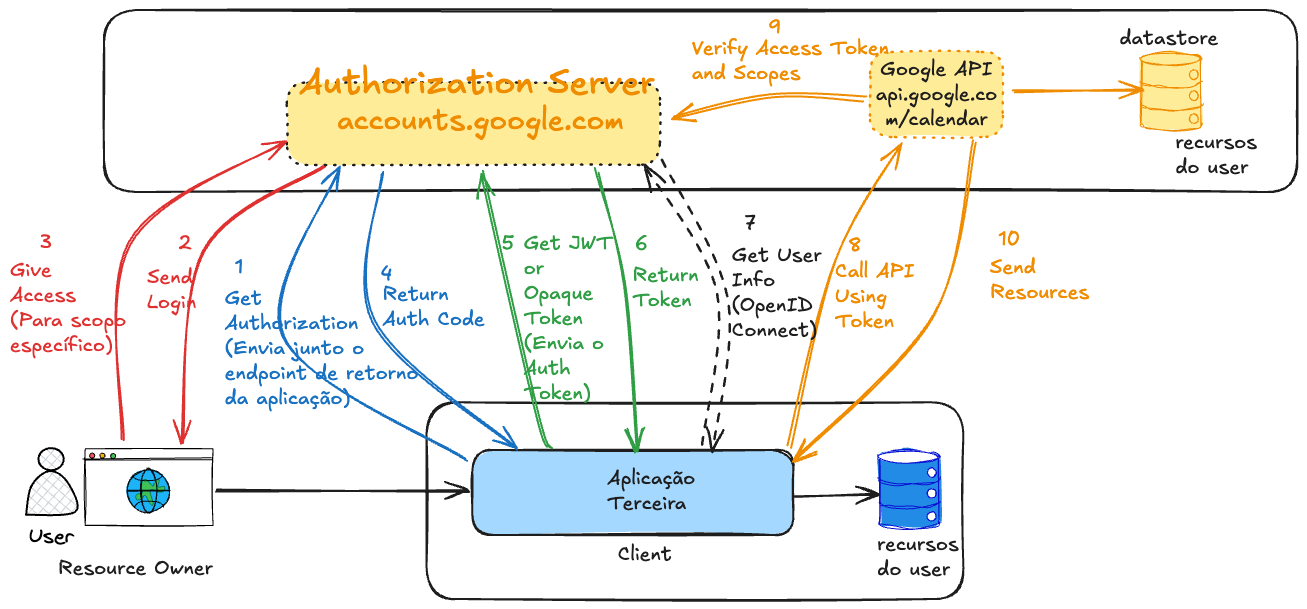
Si reparaste bien existen dos etapas diferentes.
-
Tomar el Authorization Code: Este paso sirve para autenticar al usuario y pedir consentimiento. No es un paso que ya entrega acceso. Este código es temporal e inútil solo.
-
Cambiar el Authorization Code por un Access Token. Este es el paso donde la aplicación gana permiso de verdad.
¿Por qué están separados? Por seguridad. Esto protege el Access Token real de exposición.
- El primer paso pasa por el navegador, donde todo puede filtrarse.
- El segundo paso es server-to-server, con client_secret o PKCE.
Fue añadido un step opcional para el OpenID Connect solo para que entiendas cuándo actuará. No es obligatorio utilizar, pero es bueno para entender el momento en que es usado para estudios futuros.
En el último paso, API de Google Calendar extraerá el access token y hará la verificación en el Authorization Server. Este paso solo ocurre caso sea utilizado el token del tipo Opaque, pues si es JWT ya estará firmado no necesitando esa verificación junto al Authorization Server. Sin embargo, caso sea JWT, la API necesita tener la clave pública del Authorization Server disponible para hacer la verificación local. Todo Authorization Server tiene su endpoint público para que todos tengan acceso a esa clave y cabe al desarrollador guardarla en algún lugar.
Existe un endpoint también en el Authorization Server solo para invalidar un token.
Todo ese proceso está estandarizado en el RFC para que varias bibliotecas de diferentes lenguajes puedan seguir el mismo flujo.
Grant Types
Existen varios tipos de aplicaciones en que el client puede estar implementado. Podría ser en el frontend, backend, móvil, una extensión en el navegador, en un software de escritorio, etc.
Cuando un client está en el backend de la aplicación (en el servidor) lo llamamos confidential client, pues corren en un entorno seguro donde Auth Code tiene menor chance de ser expuesto. Los public clients corren en entornos inseguros como un navegador, aplicaciones Android e iOS, extensión de navegador, etc, donde el riesgo es mucho mayor.
Lo ideal es que el token cambiado usando el auth code sea guardado lo máximo posible en el backend de la aplicación, pero existen casos que no es posible. Mostramos un flujo en que el client está en el servidor (backend), pero existen escenarios que esto no es posible. El Auth Code es válido por poco tiempo para ser cambiado por el Access Token y necesita del login del usuario. El Access token por otro lado ya es el token que permite acceso al recurso.
Existe una extensión para ese tipo de concesión de auth code llamada PKCE (Proof Key for Code Exchange) en que un parámetro verificador de código es generado dinámicamente por el client. Un desafío de código es creado y enviado al llamar al endpoint del Authorization Server. Sería como una contra contraseña dinámicamente generada por el client que quedará almacenada en el Authorization server y cuando el Access token sea cambiado esa contraseña será utilizada para confirmación. ¡Es una especie de 2FA automático! Esto sirve para que el Authorization Server sepa que es el mismo client quien hizo la petición.
El grant_type es un parámetro obligatorio de la petición hecha al token endpoint, es decir, cuando el client está pidiendo un token de acceso al Authorization Server. A continuación algunos ejemplos de grant type principales.
-
Authorization Code (con PKCE)→ Frontend o apps públicas- Usuario logea y da consentimiento
- App toma un authorization code
- Backend cambia ese code por un access token
- Considerado muy seguro
- Es el mismo flujo, pero con un parámetro más.
-
Client Credentials→ Machine-to-machine- Sin usuario involucrado (todo en el sistema)
- Solo el cliente (app) se autentica con client_id + client_secret
- Recibe un token para actuar en nombre propio
- Usado en microservicios, jobs, APIs internas
-
Resource Owner Password Credentials(Depreciado)- App colecta username y password directo del usuario. Esta no es la pantalla de login del Authorization Server.
- Envía al Auth Server y recibe el token
- Desalentado hoy en día, por riesgos de seguridad, pues de alguna forma colectamos la contraseña del usuario.
- Solo usado en sistemas muy controlados (tipo CLI interna) y first client application, pero aún así es desalentado
-
Refresh Token- No es para login, pero para renovar el access token
- Después de que el token expira, se usa el refresh token para tomar uno nuevo
- No necesita hacer login de nuevo
- Usado para mantener la sesión del usuario viva
- Requiere un flujo anterior (authorization code o password)
- Cuando obtenemos el access token también podemos obtener el refresh token (que posee un tiempo mucho mayor de expiración, a veces nunca expira). Pero el refresh token solo funciona para generar un nuevo token y no da acceso a los recursos.
grant_type | Nombre / Flow | ¿Requiere login del usuario? | ¿Usado cuándo? |
|---|---|---|---|
authorization_code | Authorization Code | Sí | Cambiar código por token tras login |
authorization_code + PKCE | Authorization Code (con PKCE) | Sí | Versión segura para SPAs y móvil |
client_credentials | Client Credentials | No | Auth máquina → máquina |
password (obsoleto) | Resource Owner Password Credentials | Sí | Apps heredadas (no recomendado) |
refresh_token | Refresh Token | No | Renovar access_token sin reautenticar |
urn:ietf:params:oauth:grant-type:device_code | Device Authorization Flow | Sí (fuera del device) | TVs, consolas, IoT |
urn:ietf:params:oauth:grant-type:jwt-bearer | JWT Bearer (RFC 7523) | No (token ya firmado) | Login federado entre servicios con JWT |
urn:ietf:params:oauth:grant-type:token-exchange | Token Exchange (RFC 8693) | Depende | Cambiar un token por otro (ej: delegación) |
El valor de grant_type define cómo el Authorization Server debe procesar la petición de token, de acuerdo con el tipo de flujo utilizado.
Tú, como DevSecOps o aspirante a Platform Engineer, debes saber:
| Qué saber | ¿Por qué? |
|---|---|
| Cómo los grant types funcionan | Para entender integraciones seguras y flujos entre apps y servicios |
Cómo proteger client_secrets y tokens | Porque filtración = brecha de seguridad |
| Configurar IdPs (Keycloak, Auth0, etc) | Porque muchas veces el DevOps gestiona el Authorization Server |
| Políticas de expiración y revocación | Para mantener seguridad y control de sesión |
| Monitorear y loguear autenticaciones | Para responder incidentes y auditar accesos |
Desarrollador implementa los flujos entonces necesita conocer con profundidad.
DevOps / DevSecOps / Platform Engineer garantiza que están seguros, escalables y bien configurados.