Apache Kafka
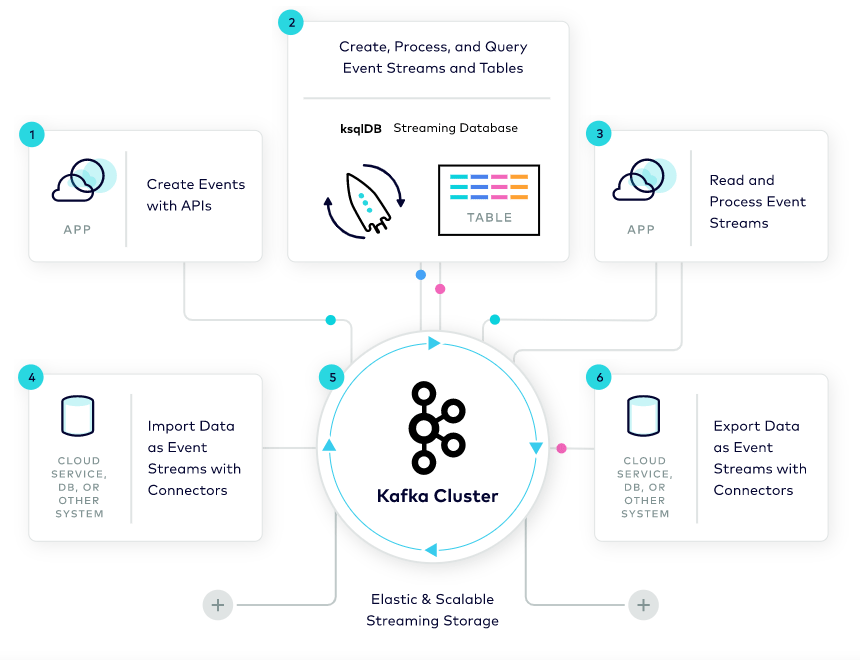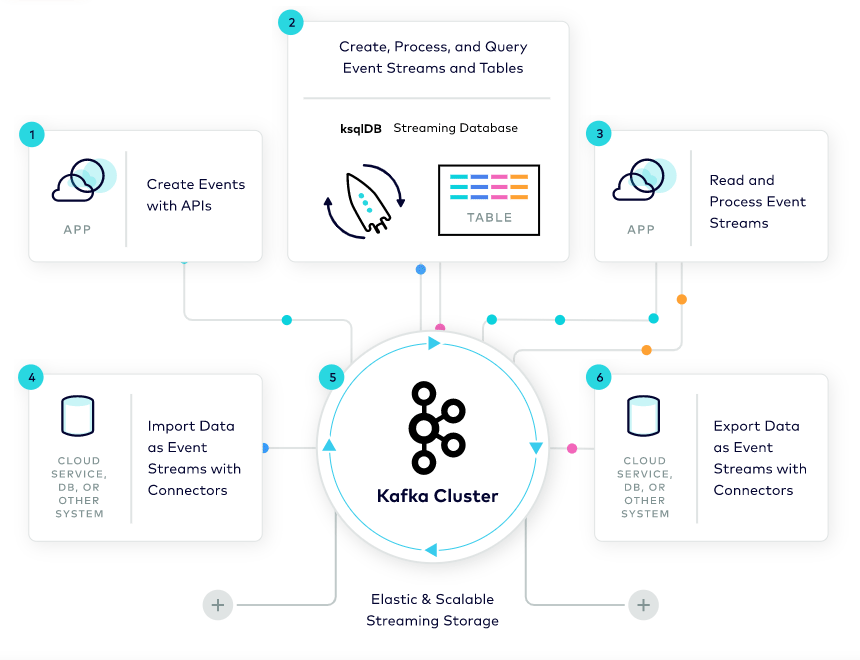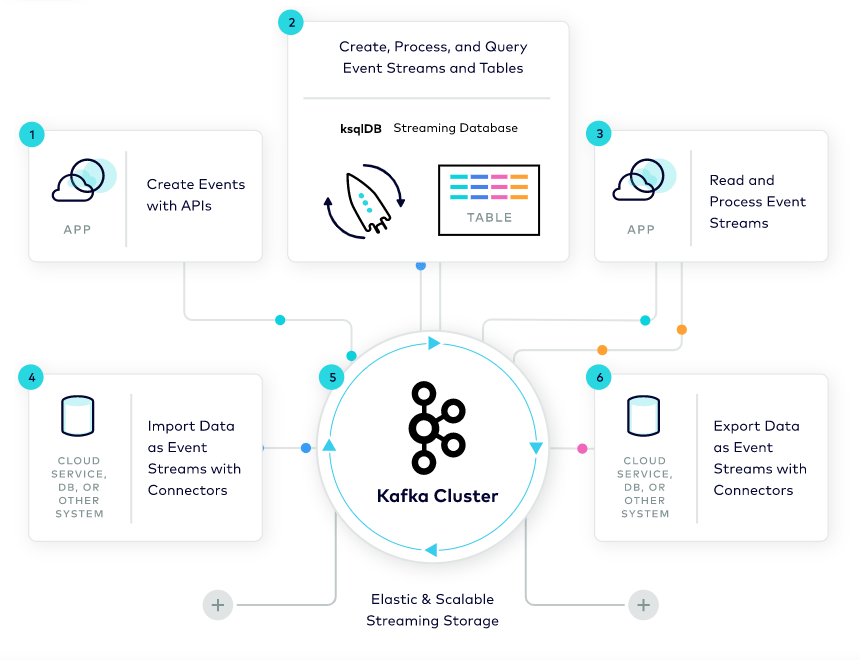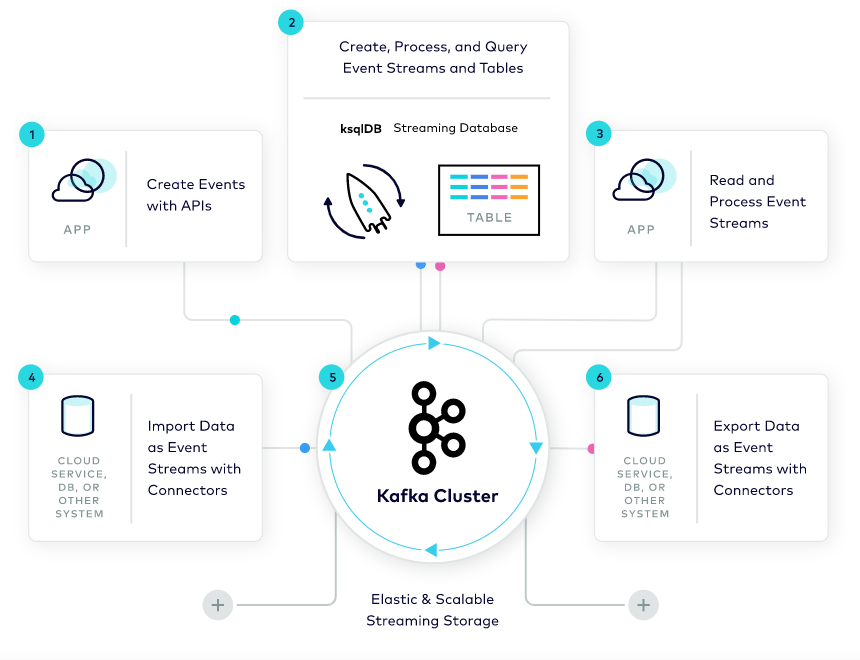
Kafka was developed by LinkedIn in 2010 and is now being used by thousands of organizations.
80 out of the top 100 companies use kafka in different ways.
Apache Kafka is the most popular open source stream processing software for collecting, processing, storing, and analyzing data at scale.
- Excellent performance
- Low latency
- Fault tolerance
- High throughput
- Capable of handling thousands of messages per second
- Scales horizontally (unlimited) and with low-cost servers
- Uses cheaper hardware available in the market and in cloud
- Doesn't require downtime for upgrades, only adding more nodes to the cluster
Some common benefits are:
- Creating data pipelines
- Leveraging real-time data streams, enabling operational metrics and data integration from numerous sources.
Kafka allows organizations to modernize their data strategies with event streaming architecture. The world's top companies use Kafka.
Several clouds offer Kafka as a ready-to-use service, a classic example is MSK on AWS and the most famous which is Confluent Cloud, but nothing prevents us from having our own Kafka, after all it's open source.
Some Use Cases
- Transition from a monolithic architecture to a microservices architecture.
- Acts as a Bus for system events.
- Asynchronous but real-time processing.
- Payments and financial transactions in real time, as in stock exchanges, banks, and insurance companies.
- Tracking and monitoring cars, trucks, fleets, and shipments in real time, as in logistics and the automotive industry.
- To continuously capture and analyze sensor data from IoT devices or other equipment, as in factories and wind farms.
- Collect and immediately react to customer interactions and orders, as in retail, hospitality and travel industries, and mobile applications.
- Monitor patients in hospital care and predict changes in conditions to ensure timely treatment in emergencies.
- Connect, store, and make available data produced by different divisions of a company.
- Serve as foundation for data platforms, event-driven architectures, and microservices.