Software and Security
Software is a set of computer instructions designed to assist a human process. Most of the time, it assists a process that already exists manually. This means that software does not exist separate from the world, it is part of a process.
Software does not exist in a vacuum. It is a tool serving a process, executed by people.
- There is a set of activities before the software is used.
- Another during software use.
- And a process at the end of software use.
Payroll software, for example, does not create the process of paying employees. It automates and assists a process that already existed (manual calculations, issuing checks, etc.). The activities of collecting worked hours (before), operating the software (during), and distributing pay stubs and making payments (after) continue to exist. The software is just the central piece that optimizes the "during".
There is no software security decoupled from the processes around it. It is a mistake to think that security is only about the software.
This is the pillar of modern information security. Software can be technically perfect, without any vulnerability, but still be compromised by failures in the processes around it.
Let's exemplify this.
- A banking system can have the strongest encryption in the world, but if the process allows an employee to write down the customer's password on a post-it note, security has been broken by the process, not the software.
- A cloud server can be extremely secure, but if the configuration process is poorly executed and an administrator leaves an access port open to the entire internet, the system becomes vulnerable. The failure was not in the server software, but in the human process around it.
All software is a culture change, they used to do it one way, now they will do it another way. Software implementation requires change including in the manual processes around it.
We can use as an example a company that used spreadsheets for customer control and implements a CRM (Customer Relationship Management) system. Many salespeople may resist, finding the new system "complicated" or "slow", and will continue using their old spreadsheets "for security", creating data inconsistency and a security risk (customer data in loose files).
- Humans have the habit of continuing to try to do something the way they did before.
- Users think the system is more insecure than the previous way.
This is a matter of perception and trust. The manual process, being familiar and tangible (a paper folder in a cabinet), may seem safer to the user than an "abstract" digital system in the cloud, even though the cabinet could be easily broken into and the cloud system has multiple layers of encryption and access control. Lack of understanding generates distrust.
The user is often called the "last line of defense" or, if not trained, the "weakest link" in security.
When is Software Considered Secure?
No matter how many tests have been executed, software is a complex mechanism and almost certainly some failure was not foreseen, and over time they are being corrected.
Why does a system go into production even with failures? Because it is very cheap to correct a failure, unlike a company that produces cars where the recall system would be extremely financially damaging and could lead a company to bankruptcy.
Of course, in some circumstances there are software errors that are extremely expensive, such as aircraft software that stops working leading to a crash and the death of many people.
The idea is to develop software where failures do not generate catastrophic losses.
Software Development Processes
It is necessary to first understand how the software development process works for security in software study to make sense. If you already know the entire process, great! I will try to summarize years in a few lines.
Basically, these are the stages of software development, but it is necessary to take into consideration that the methodology used can change the way each stage is executed.
- Initial Survey
- Specification
- Analysis and design
- Coding
- Testing
- Deployment
- Maintenance
In the past, we had some methodologies (below) that today are considered outdated after what we call the Agile Manifesto. We won't go into details about them, if you're interested just search.
- Waterfall
- Iterative Spiral
- Evolutionary Prototyping
- Code and Fix
Agile Manifesto
The above methodologies generally did not deliver the software the customer requested, because the customer doesn't really know what they want or didn't think about all aspects. Often the market changed before the software was even ready. A methodology was needed that included the customer in the process and was flexible, and this was the basis for what we call the Agile Manifesto.
- Individuals and interactions over processes and tools
- This focuses the collaborator on the project instead of the bureaucracies involved.
- Tools and processes are important, but they should serve people, not the other way around.
- Working software over comprehensive documentation
- Software is constantly evolving. Spending too much time documenting doesn't make sense if this will change so quickly. This doesn't mean you shouldn't have minimum viable documentation.
- Customer collaboration over contract negotiation
- The customer should be part of the team and see what is happening and what is being developed. This avoids closed contracts with fixed time, keeps the customer always informed, and makes specification or understanding errors found quickly.
- Responding to change over following a plan
- Start producing and respond to change as needed.
It is very important to observe that the software architecture under development needs to be designed to respond to changes. Software completely coupled in its functions compromises this factor and demands more time for change.
The most used agile methodologies today are:
-
Scrum
- Based on short and structured work sprints
- Scrum teams commit to completing a shippable increment of work through defined intervals called sprints. The goal is to create learning cycles to quickly gather and integrate customer feedback. Scrum teams adopt specific roles, create special artifacts, and perform regular ceremonies to keep things moving forward. Scrum is best defined in the Scrum Guide.
-
Kanban
- Makes the process more fluid
- It's about visualizing work, limiting work in progress, and maximizing efficiency (or flow). Kanban teams focus on reducing the time it takes for a project (or user story) to go from start to finish. To achieve this goal, they use the Kanban board and always improve workflow.
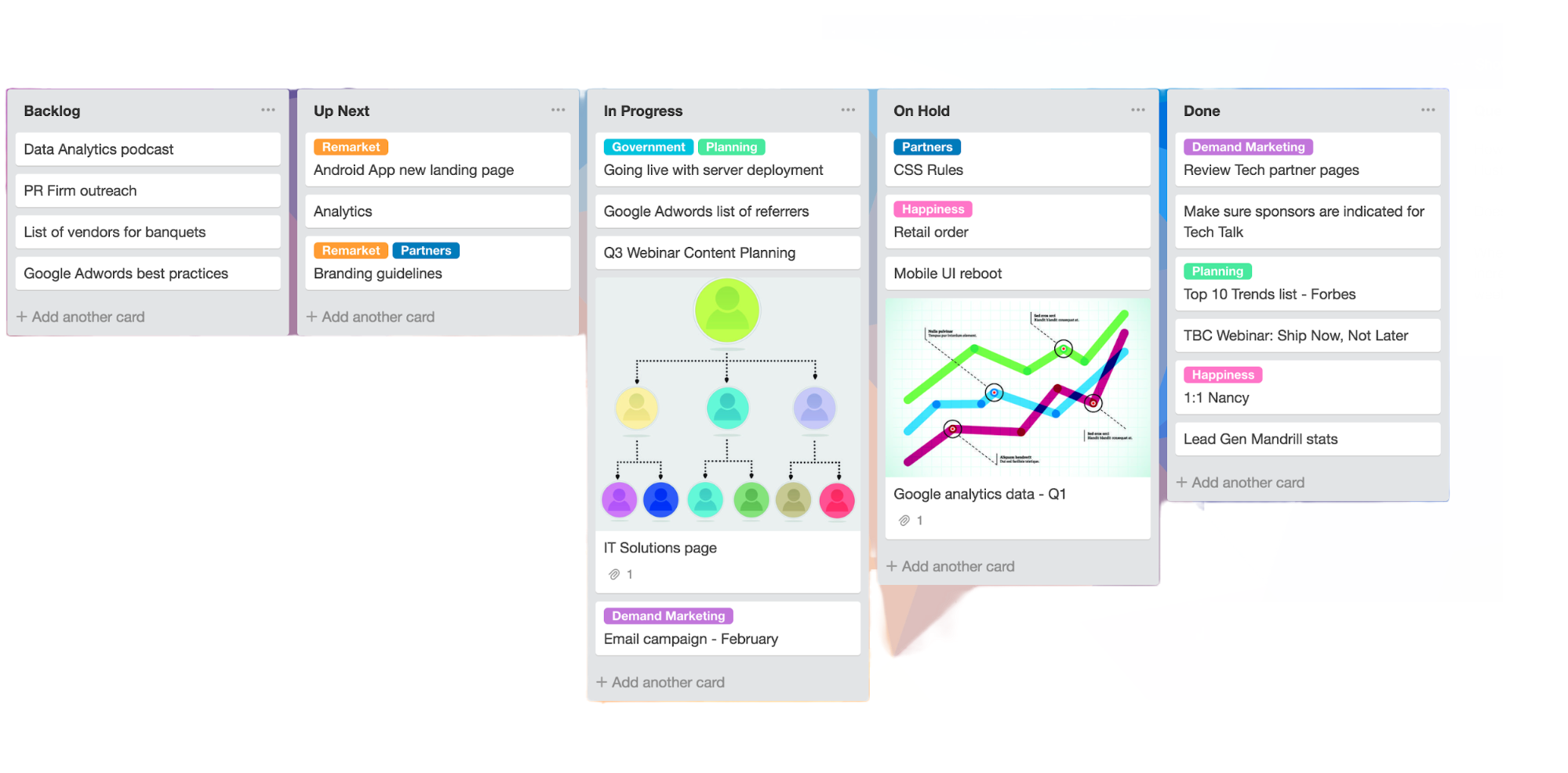
| Scrum | Kanban | |
|---|---|---|
| Origin | Software development | Lean manufacturing |
| Ideology | Learn through experience, self-organization and prioritization and reflect on wins and losses to always improve. | Use visuals to improve work in progress |
| Cadence | Regular, fixed-length sprints (e.g., two weeks) | Continuous flow |
| Practices | Sprint planning, sprint, daily scrum, sprint review, sprint retrospective | Visualize workflow, limit work in progress, manage flow and incorporate feedback loops |
| Roles | Product owner, scrum master, development team | No mandatory roles |
An in-depth study of these methodologies is valuable for working with software today, especially Scrum. Generally, companies adapt scrum to their needs by reducing some ceremonies. There is even a mix between Scrum and Kanban called Scrumban.
There are many tools that help in applying agile methodologies.
Legacy Software
Legacy software is a system, technology, or application that, while still in use and often critical to operations, is considered obsolete. It remains active mainly for two reasons: it supports vital business processes ("it still works") and the cost or risk of replacing or modernizing it is considered prohibitive by the organization.
- Non-existent or outdated documentation making any modification a slow and risky process.
- Written in obsolete languages that have few developers available in the market.
- Has high maintenance costs
- Was developed without following modern software engineering standards, resulting in code.
It represents a great risk to information security, as it does not receive updates and often has known and uncorrected vulnerabilities.
Programming Languages
The processor only understands binary 0 and 1 and humans have difficulty programming directly like this.
For this, high-level languages are defined that create an algorithm (logical flow) that can be easily read by humans.
The compiler (other software) reads this high-level language and transcribes it to binary.
Languages can be:
-
Compiled (C, C++, Delphi, Python, Rust, etc.)
- Takes the high-level source code and generates the executable that is already in machine language (0 and 1)
- It is necessary to recompile at each source code change
- It is necessary to compile for the correct processor architecture
- Usually faster languages because everything is ready.
-
Intermediate Code (Java, C#)
- Generates intermediate code to run on a virtual machine that is prepared to read this pre-compiled code and compile correctly for the processor architecture the virtual machine is running on, making necessary adjustments and even improvements.
- Usually optimizes code for final compilation according to the processor being an advantage over interpreted code.
- Language is concerned with generating virtual machines for each processor architecture.
- Greater flexibility
- It is easier to do reverse engineering with pre-compiled code generating a security problem.
-
Interpreted (PHP, JavaScript, Beanshell, etc.)
- Reads source code at runtime and generates machine code in real time.
- Does not need to generate executables prepared for each architecture
- Less performant
Mobile Application Development
Mobile application development frequently uses intermediate code. This code, in turn, goes through a final compilation process that optimizes it for the specific architecture of mobile processors, aiming to maximize performance and, especially, energy efficiency to preserve battery life.
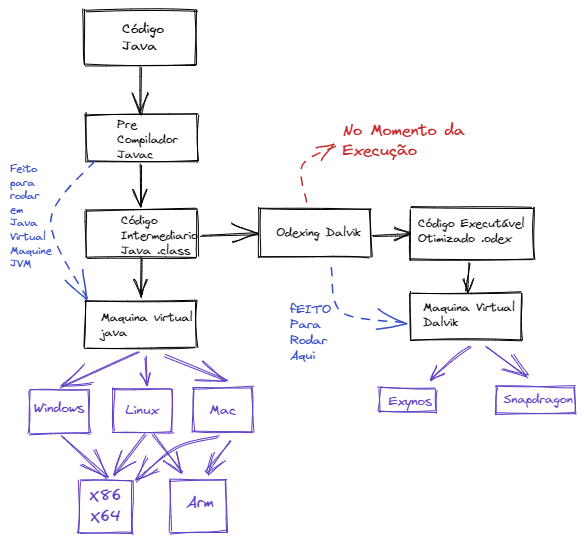
To ensure the application's authenticity and integrity, protecting it against tampering and counterfeiting, the final code is digitally signed with a digital certificate.
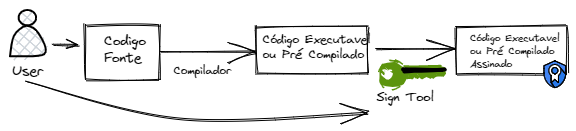
Both Android and iOS rigorously perform this validation. If the application code is modified in any way, the digital signature becomes invalid, and the operating system refuses the app's installation or update, protecting the user.
Apple's philosophy is more restrictive: in addition to the developer's signature, Apple itself reviews and "notarizes" each application, centralizing distribution on the App Store (with recent exceptions for alternative stores in the European Union). Android allows installation of apps from external sources (a process known as sideloading), as long as the application has a valid digital signature.
From a security perspective for the average user, this centralized approach makes the iPhone ecosystem widely considered more secure, as it eliminates the main vector of malware: installing apps from untrusted sources.
The risk on Android lies in the fact that, although you cannot update an app with a different signature, an attacker can tamper with a legitimate application and distribute it as a new app, signed with their own certificate. For this reason, the fundamental security recommendation for Android users is to install applications exclusively from the official store, the Play Store.
It is important to note that all this security structure is valid for devices in their original state (iPhone without jailbreak and non-rooted Android). Making these modifications breaks the system's protection barriers, allowing installation of any software, including malicious ones.
This verification principle is not exclusive to mobile systems. Windows, through SmartScreen, warns about unsigned applications, and Linux repositories use cryptographic keys to validate package authenticity and integrity, ensuring the source is trustworthy.
System Architecture (Overview)
Every software application, in its essence, can be divided into three fundamental logical components:
- Interface: The layer with which the user interacts.
- Logic: Where rules, processing, and calculations are executed.
- Data: The layer responsible for storing and retrieving information.
The way these components are organized and communicate defines the system architecture.
Mainframe
In this totally centralized model, all three components (presentation, logic, and data) reside and are processed on a single large server, the Mainframe. Users interact with the system through "dumb terminals", which only serve to display information and send commands, without local processing capability.
Stand Alone
This is the classic desktop software architecture. Here, all components are installed and executed on the user's own machine. There is, by default, no network communication to access an external data or logic layer. Examples include text editors or spreadsheets in their offline mode.
Client Server
In this model, the Data layer is centralized on a database server. However, the Presentation and Business Logic layers are executed on the client machine.
This architecture is largely obsolete due to a fundamental security flaw: the client application needs to connect directly to the database over the network, which means access credentials are stored on the user's machine. An attacker could easily use a network sniffer to capture this authentication data or, having access to the machine, extract credentials and manipulate the database directly.
Modern Architectures and Common Patterns
3-Tier and N-Tier Architecture
3-Tier architecture is the foundation for most modern systems. It physically separates the three logical components:
- Presentation Layer: Responsible for the user interface (e.g., a web browser, a mobile app).
- Application/Logic Layer: A server where business rules are processed.
- Data Layer: A database server that stores information.
N-Tier architecture is an evolution of this model, allowing creation of additional intermediate layers for specialized functions, such as caching, message queues, or security gateways.

-
N Tiers

-
Mobile
- WebApp which is actually an app that runs in the browser underneath. It's just a shell. Most are this type of app.
- Native are real apps.
- Hybrid, with some functions treated as web
-
3 Tiers
Web Architecture
Web architecture is the most common implementation of the 3-tier model. The flow works as follows:
- The browser (Presentation) sends a request via HTTP/HTTPS protocol.
- The Application Server (Logic), running technologies like Java, C#, Python, Node.js, etc., receives the request, processes the business rules, and interacts with the database.
- The server then sends a response back to the browser, which renders it for the user.
This communication model is synchronous and known as Request-Response. Architectural styles like REST are widely used to structure this communication in a standardized way.
Mobile Architecture
- Native: Applications developed specifically for an operating system (iOS or Android), using their native languages and tools. They offer the best performance and full access to device resources.
- Web App: In practice, it's a website designed to look and behave like an application, running inside the phone's browser.
- Hybrid: A combination of both worlds. Uses a native "shell" (WebView) to run web technologies (HTML, CSS, JavaScript), but can access some native device functionalities through bridges.
Asynchronous Communication: Publish-Subscribe (Pub/Sub)
In contrast to the synchronous model, the Pub/Sub pattern uses an intermediary, such as a message queue (message broker), for communication.
- A service ("Publisher") publishes a message to a topic, without knowing who will receive it.
- Other services ("Subscribers"), who are interested in that topic, receive the message and process it in their own time.
- This model is asynchronous, decoupling services and being ideal for tasks that don't require an immediate response.
Microservices
Microservices architecture structures an application as a collection of small independent services, each responsible for a specific business area. Communication between these services is a crucial point, and they use a combination of patterns:
Synchronous Communication (e.g., REST APIs): For direct commands that need an immediate response.
Asynchronous Communication (e.g., Pub/Sub): To notify other services about events, ensuring decoupling and resilience.