Information Security Concepts
Asking if software is "secure" requires immediate clarification: "secure in what aspect?" This is because the term "information security" is broad and multifaceted, having different meanings for each context or person.
Far from being a single, absolute concept, security is composed of several pillars. The importance of each varies drastically depending on the objectives and risks of the system in question.
The first three form the classic and most well-known "Information Security Triad" - CIA: Confidentiality, Integrity, Availability
- Confidentiality
- Integrity
- Availability
- Traceability
- Authenticity
- Reliability
- Privacy
- Non-repudiation
Confidentiality
Confidentiality is the security pillar that ensures information is accessible only to properly authorized individuals, systems, or processes. A breach of confidentiality occurs the moment data is exposed or revealed to an unauthorized party, regardless of intent.
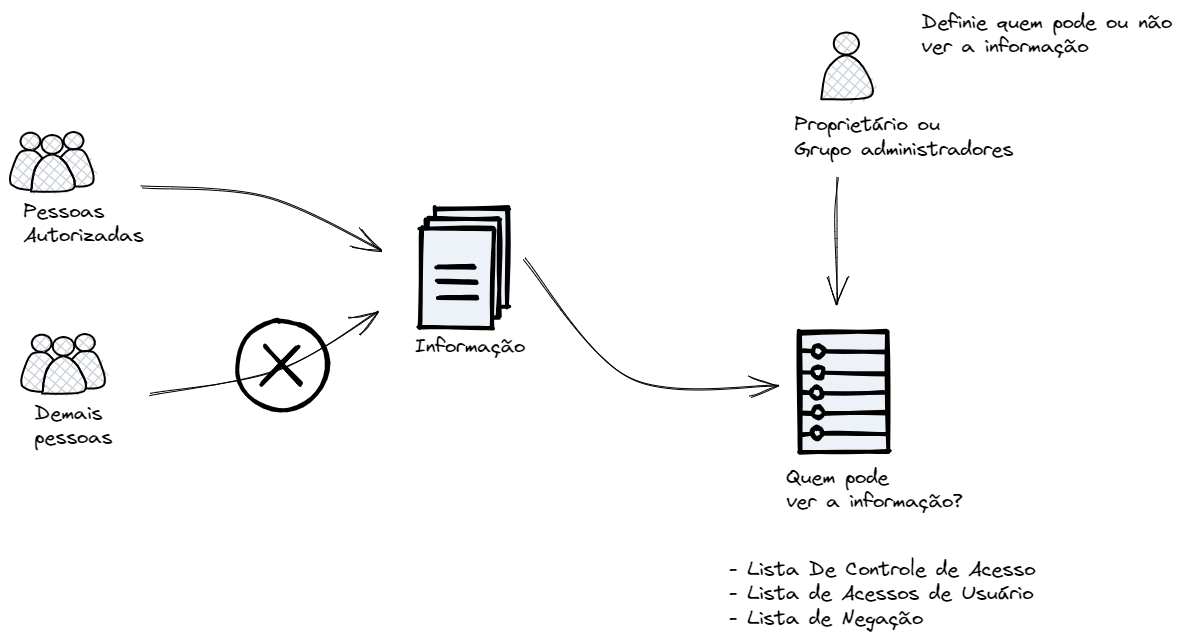
To manage access effectively, each piece of confidential information must have a designated owner from its creation. This owner can be a specific user or group and is the only one with authority to define and maintain the list of who can access this information.
The way this control is implemented depends on the system architecture. Two common approaches are:
-
ACL - Access Control List: Ideal for systems with many objects (data) and a limited number of users. Each object has an attached list specifying which users (or groups) are allowed to access it. Permission checking is done on the object itself. -
Capability List: More suitable for systems with many users and a limited number of sensitive objects. In this model, each user has a "key list" defining which objects they can access. Verification focuses on user identity and permissions.
Managing complex permissions increases operational costs and the risk of misconfiguration. Therefore, a golden rule in system design is to apply confidentiality only to what is strictly necessary.
The need to restrict access to information is not arbitrary. It arises from critical motivations for business, security, and legal compliance. The main reasons for classifying data as confidential are:
-
Legal and Contractual Obligations: Often, confidentiality is not a choice but an imposition. Laws, regulations, and contracts require that certain information be rigorously protected.- Legal Requirements: Specific laws define secrecy levels and penalties for non-compliance.
- The Access to Information Law (Law 12.527/11) establishes gradations for the confidentiality of government documents.
- The Bidding Law (Law 8.666/93, now succeeded by Law 14.133/21) criminalizes the disclosure of confidential process information, such as the administration's internal budget or competitors' proposals before the appropriate time. In these cases, implementing confidentiality is mandatory, and non-compliance can result in severe sanctions, fines, and lawsuits.
- Legal Requirements: Specific laws define secrecy levels and penalties for non-compliance.
-
Competitive Advantage and Strategic Value: Certain information is valuable not for what it is, but because it is secret. As well defined, the value of a secret is how valuable it is while competitors don't know it.- Intellectual Property: Before being formally registered, an innovation needs absolute secrecy. Imagine the data leak about a new drug formula still in the research phase or a product design before patent registration. The secret is what protects the investment and market potential.
- Trade Secrets: Information that gives a company a market advantage. A list of strategic customers, details of an ongoing negotiation, or a pricing algorithm are valuable assets. If a competitor gains access to this data, they can anticipate actions, "steal" customers, and neutralize your competitive advantage.
-
Authentication Factors: This is a special category of confidentiality, where the secret is the user's proof of identity itself.- Passwords and Access Secrets: Confidentiality here is absolute. A user's password, for example, is a secret that must belong only to them. In a well-designed system, no one else can access the password in its original format — not even database administrators, developers, or the infrastructure team. This is ensured through cryptographic techniques like hashing, which make the original password irrecoverable.
The value of a secret is how valuable it is if no one knows it.
Privacy
Although closely linked to confidentiality, privacy is a distinct and fundamental concept. While confidentiality focuses on who can access information, privacy focuses on the individual's right to control how their personal information is collected, used, stored, and shared.
From the perspective of laws like LGPD (General Data Protection Law), the user is the data subject of their personal data, such as:
- First and last name
- Residential address
- Phone number
- CPF, ID, and other documents
One of privacy's pillars is the principle of purpose. When a user fills out a form to make a purchase, for example, they consent to the use of their data only for that specific purpose (process payment, issue invoice, send product).
Any secondary use of this information, whether for marketing purposes or sharing with third parties, requires new consent. The system cannot simply assume this authorization.
The developer must anticipate that the user who has personal information in the system can decide about the use of this information.
This imposes a direct responsibility on software developers and architects: systems must be designed with privacy in mind from the start. It is necessary to create mechanisms that allow users to exercise their control in a granular and transparent manner.
Controls that should be in the user's hands include, at minimum, the ability to:
- Consent (or not) to marketing communications, such as email marketing, newsletters, and direct mail.
- Authorize (or not) sharing of their data with partner companies.
- Manage the use of cookies and other browsing tracking technologies.
- Access, correct, and request deletion of their personal data from the platform, exercising their rights as a data subject.
The moment a user fills out a system form, it is understood that they are already allowing the use of this information within the system itself, but this system is not authorized to use this information for other things.
The system must define the privacy policy, the user just accepts it or not.
An important point to discuss is points where it's difficult to decide whether or not it's privacy
-
Session cookie, in this case it's a cookie that saves user information for access to your system. This is a point that may or may not be defined as a privacy requirement.
-
Cookies like Google Analytics or Facebook, these are certainly private user information that is passed to other systems and are suffering under the laws.
Confidentiality vs Privacy
The fundamental difference between the two can be summarized as:
- Privacy protects the user from misuse of their data by the system.
- Confidentiality protects the system's data from unauthorized access by the user.
Privacy is so important that, in addition to being a right, it is a legal requirement and an intelligent business practice. Its pillars are:
- Legal Aspects:
- Federal Constitution (CRF/88)
- LGPD (General Data Protection Law)
- GDPR (General Data Protection Regulation)
- Protection of the Individual and Business:
- Good Practice: Generates trust and strengthens the brand.
- Limitation of Liability: Reduces legal and financial risks.
To avoid problems, a system should only store data strictly necessary for its operation. Storing unnecessary information brings no benefits and increases the risk of damages and lawsuits in case of a leak.
Integrity
It is a property of information security that ensures data remains complete, accurate, and unaltered, except by authorized modifications. All information needs some degree of integrity. Information that loses its integrity also loses its value.
Only those who are authorized can alter the information. If someone unauthorized alters it, the information becomes non-integral, as shown in the example below.
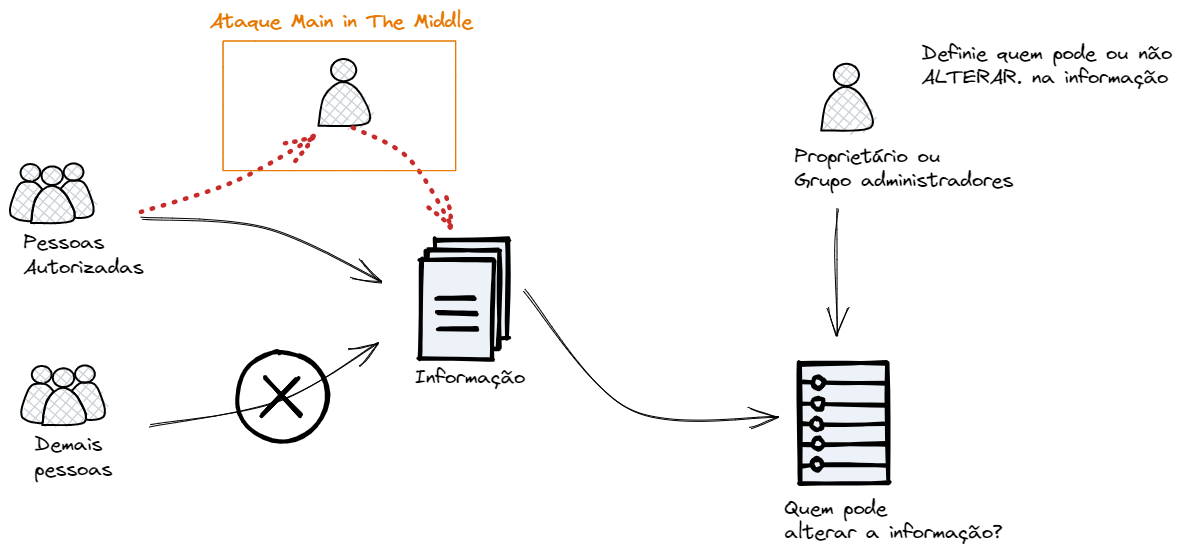
Information should even undergo versioning so that changes can be audited. This is also a form of backup, maintaining the reference. Versioning guarantees the information's lifecycle, all its changes until its destruction. At some point the information will need to be destroyed.
Integrity Pillars:
-
Authorization: Only users or systems with permission can create, modify, or delete information. Any alteration performed by an unauthorized entity constitutes an integrity breach. -
Information Lifecycle:- Creation: Information is born integral.
- Alterations and Access: All modifications are controlled and recorded.
- Deletion: Information destruction is done securely and definitively when necessary.
-
Versioning: Maintaining a history of information versions is crucial. This not only allows auditing all changes made over time, but also functions as a form of backup, ensuring it's possible to revert to a previous integral state.
Threats:
- Direct Attacks: An attacker deliberately alters information to corrupt it.
- Transmission Failures: Data packets that don't reach their destination, as in a Denial of Service (DoS) attack, prevent information from being updated, resulting in an outdated and non-integral state.
- External Incidents: Situations like power failures, natural disasters, hardware failures can prevent necessary modifications from occurring, affecting information correctness.
It is very similar to confidentiality, but referring to alteration and not reading.
It is much easier to detect that there was an integrity breach than a confidentiality breach.
Integrity vs Confidentiality
- Integrity is critical: In financial transactions, the accuracy of the value moved in a customer's account is more critical than the secrecy of the transaction itself.
- Confidentiality is critical: The private key of a Certification Authority (CA) is an example where confidentiality is supreme. The simple leak (reading) of this key, even without alteration, would compromise the entire trust system, requiring immediate revocation of all issued certificates.
Availability
It is one of the three fundamental pillars of information security (along with Confidentiality and Integrity). It is the property that ensures information and systems are accessible and operational for use whenever demanded by an authorized entity.
There's no point in information being secure and integral if legitimate users cannot access it when they need to. Unavailability can cause financial losses, reputational damage, and interruption of critical business processes.
Today with the cloud system, availability reaches practically 99.999%.
Availability is an easy-to-measure indicator and is generally expressed as a percentage.
- Using transactions: Availability = (Successful Attempts / Total Attempts) x 100
- Uptime: (Uptime / (Uptime + Downtime)) x 100
Just for curiosity:
99%: ~3.65 days of downtime per year. 99.9%: ~8.76 hours of downtime per year. 99.99%: ~52 minutes of downtime per year. 99.999%: ~5 minutes of downtime per year.
Ensuring continuous availability involves a set of strategies and best practices to create resilient and fault-tolerant systems. The main ones are:
- Redundancy: Duplicate critical system components (such as servers, disks, network links, and power sources). If one component fails, the redundant one takes over its function immediately.
- Failover: Implement contingency systems that are activated automatically when the primary system fails. This minimizes or eliminates downtime perceived by the user.
- Load Balancing: Distribute traffic and requests among multiple servers. This prevents a single server from becoming overloaded and unresponsive, improving performance and resilience.
- Backups and Disaster Recovery Plan (DRP): Perform constant backups and have a well-defined plan to restore systems and data after a serious incident (such as a natural disaster or a large-scale cyberattack).
Main Threats to Availability:
- Denial of Service Attacks (DoS/DDoS): Flooding a system with a massive volume of traffic or requests with the goal of exhausting its resources and making it inaccessible to legitimate users.
- Hardware and Software Failures
- Ransomware: A type of malware that hijacks data by encrypting it, making it unavailable until a ransom is paid.
- Environmental and Human Factors: Incidents such as power outages, fires, floods, or even human error (such as incorrect configuration or accidental data deletion) can bring down a service.
Reliability
It is the probability of a system or component performing its expected function, without failures, for a specified period of time and under predetermined conditions. The keyword here is "without failures".
While Availability concerns whether the system is "up" at a given moment, Reliability concerns how often it goes down.
Reliability vs. Availability
The relationship between the two concepts is governed by the frequency of failures and the time needed for recovery.
- Availability is impacted by recovery time (how quickly the system comes back).
- Reliability is impacted by failure frequency (how many times it goes down).
Let's analyze with scenarios:
-
Scenario 1: High Availability, Low Reliability
- A system that suffers a micro-failure and restarts every hour, but the restart process takes only 1 second.
- Reliability: Terrible. The system fails constantly (every hour). It's not reliable for continuous processes.
- Availability: Very high. In a 24-hour day (86,400 seconds), it would be unavailable for only 24 seconds. Availability would be (86376 / 86400) * 100 = 99.97%.
- A system that suffers a micro-failure and restarts every hour, but the restart process takes only 1 second.
-
Scenario 2: High Reliability, Low Availability
- A satellite system that works perfectly for 5 years without any failure, but when it finally fails, takes 6 months to be repaired.
- Reliability: Excellent. Worked for 5 uninterrupted years. It's an extremely reliable system during its operation.
- Availability: Low (if we analyze the complete lifecycle). The long repair time (6 months) drastically impacts total availability in the 5.5-year period.
- A satellite system that works perfectly for 5 years without any failure, but when it finally fails, takes 6 months to be repaired.
High reliability is a requirement of real-time critical systems and it is much more difficult to guarantee reliability than availability.
Similarly, a system with high reliability can exist, but with low availability, which would be when a system never goes down, but when it does go down it doesn't come back.
To measure these concepts, the industry uses two main metrics:
-
MTBF - Mean Time Between Failures: It is the average time a system operates correctly between one failure and the next.
- It is the main metric of Reliability. A high MTBF means high reliability.
-
MTTR - Mean Time To Repair: It is the average time it takes to repair a system after it has failed.
- Directly impacts Availability. A low MTTR means high availability.
The availability formula can be approximated by Availability ≈ MTBF / (MTBF + MTTR)
When to Prioritize Each One?
- Priority on Availability (Ex: E-commerce, Social Networks):
- The goal is to be "online" for the maximum number of users. Small failures that are quickly corrected (a page refresh, a server restart in seconds) are tolerable. The important thing is that MTTR be extremely low.
- Priority on Reliability (Ex: Flight system, pacemaker, nuclear reactor control):
- The goal is to never fail. A single failure, no matter how brief, can have catastrophic consequences. In these systems, MTBF must be as long as possible, ideally infinite during the mission lifetime.
Availability is usually more required than reliability. E-commerce can suffer quick drops but cannot go offline. On the other hand, a flight navigation system can never stop.
Generally, a system with high reliability tends to have high availability, because if it fails less (high MTBF), it spends more time operating. Redundancy is the main strategy to increase both: it prevents a component failure from causing a system failure (increasing reliability) and allows almost instant recovery (decreasing MTTR), ensuring availability.
Traceability
It is the ability to link the alteration, creation, or removal of information to the user who performed it, i.e., auditing.
Traceability and privacy are antagonistic requirements. The user needs to accept that in that system they will be tracked and all their actions will be recorded. For this, it is necessary to be in the privacy policies and the user must be aware.
Strong traceability leads to one of the most important concepts in information security: Non-repudiation which is better known as Non-repudiation that we will discuss later.
Non-repudiation is the guarantee that a user cannot deny having performed an action.
For example, if an authorized user transfers funds, the system must have cryptographic or audit evidence so strong that they cannot later deny having made the transaction. This is crucial for the validity of digital contracts, financial transactions, and critical operations.
Traceability serves multiple purposes:
- User Accountability: It is the pillar to ensure that each person is responsible for their actions within the system. The mere existence of an effective audit trail already inhibits malicious behavior.
- Incident Analysis and Security Improvement: In case of a security failure or data breach, logs are the first tool analysts use to understand what happened.
- Legal and Compliance Requirements: Many sectors are legally obligated to maintain detailed audit trails.
In this case, the user is no longer the owner of the information, because if it were this way they would delete the information.
Elections have a high level of privacy (no one can know the voter's vote), which affects traceability because the system cannot get this information from them which affects an audit, thus being difficult to find fraud.
Authenticity
It is the ability to prove, without a shadow of doubt, a user's identity or the origin and integrity of information
This principle unfolds into two practical and complementary concepts:
- Identity Authentication: Verify if a user is who they say they are.
- Information Authenticity: Verify if information was actually created by the declared source and if it has not been altered in transit.
-
Identity Authentication (Who are you?): a system needs proof to validate a user's "login". These proofs are called authentication factors and are divided into three categories:
- Something you know: password, pins, secret phrases, etc.
- Something you have: security tokens, chip cards, 2FA, etc.
- Something you are (usually biometric): fingerprint, iris, voice, facial recognition, etc.
- If you want to better understand this, read Authentication.
-
Information Authenticity (Is this information legitimate?): the guarantee that a document, an email, or software really came from a trusted source and was not modified. The main mechanism for this is Digital Signature which uses asymmetric cryptography (public and private keys) to offer much stronger guarantees:
- Authenticity: Only the holder of the private key can generate the signature. If the corresponding public key can verify it, this proves who the sender was.
- Integrity: The digital signature is based on the exact content of the information. Any alteration, no matter how small (changing a comma, for example), will invalidate the signature.
- Non-repudiation: The sender cannot deny authorship, because they are the only one who has the private key capable of creating that signature.
- If you want to delve deeper into the subject read tls.
Intellectual property registration is an excellent use case. By digitally signing a work at the moment of its creation, an author can prove authorship and the exact date the content existed in that form.
Non-repudiation
Better known in technical circles as Non-repudiation, it is the guarantee that a party involved in a transaction or communication cannot deny their participation or authorship of their actions.
It is the mechanism that provides irrefutable proof of the identity of the author of an action and the integrity of what was done. While traceability records what happened, non-repudiation ensures that this record has legal and technical validity, preventing the author from denying the fact.
Track vs Prove
- Traceability (Audit): A system records in a log: "User 'David Puziol' accessed the system at 10:05 and approved transaction 789". This tells us what happened and which user account was used.
- Non-repudiation: The system not only records the action but links it to cryptographic proof, such as a digital signature. Now, the evidence is: "Transaction 789, with this exact data, was digitally signed with the private key that uniquely belongs to David Puziol".
With the second proof, David cannot claim that his password was stolen or that it wasn't him, because possession of the private key is much stronger proof and is his exclusive responsibility.
Let's exemplify this with an ATM system.
-
Old Scenario (Low Non-repudiation): The only authentication factor was the password. A customer could withdraw money and later claim that their card and password were stolen. Since the bank had no other evidence to unequivocally link that person to that transaction, it often had to bear the loss to not lose the customer. The proof was weak.
-
Modern Scenario (High Non-repudiation): Today, the system combines multiple factors to create robust proof:
- Something you have: The physical card.
- Something you know: The password (PIN).
- Audit Proof: Security cameras recording the person's image at the ATM.
- Something you are (in some cases): Biometrics (fingerprint or palm reading).
In summary, non-repudiation is the closure of the transactional security cycle, ensuring that all digital actions have the same weight and validity as a signed and notarized act in the physical world.